Feedforward Neural Network Implementation
Overview:
Feedforward Neural Network implemented in pure python + numpy . The main features are based on my Deep Learning Notes .
Features:
- Xavier, He initialization
- Dropout
- Mini-batch / Stratified mini-batch training
- Multiple optimize functions: Momentum, NesterovMomentum, RMSprop, Adam etc.
- Multiple activation functions: Relu, Leaky relu, Selu, Softplus etc.
- Learning rate decay
- Early stopping
Usage
from DNN_implementation.data import cifar_data
from DNN_implementation.model import Network_mini_batch
from DNN_implementation.train import train_DNN_minibatch
from DNN_implementation import Momentum
(X_train, y_train), (X_test, y_test) = cifar_data.load_data(normalize=False, standard=True)
dnn = Network_mini_batch(sizes=[3072, 50, 10], activation="leaky_relu", alpha=0.01, dropout_rate=0.3)
optimizer = Momentum(lr=1e-3, momentum=0.9, batch_size=128)
train_DNN_minibatch(X_train, y_train, 100, optimizer, 128, dnn, X_test, y_test)Benchmarks
| mnist - model size: [300, 100] | mnist (loss) | mnist (accuracy) | cifar10 - model size: [1000, 500, 200] | cifar10 (loss) | cifar10 (accuracy) | |
|---|---|---|---|---|---|---|
| activation: Sigmoid, use Early Stopping | 0.2717 | 0.9222 | | | activation: Sigmoid, use Early Stopping | 1.4914 | 0.4735 |
| + Relu | 0.0773 | 0.9758 | | | + Relu | 1.4078 | 0.5118 |
| + Relu & Xavier Initializer | 0.0701 | 0.9784 | | | + Relu & Xavier Initializer | 1.3275 | 0.5303 |
| + Relu & He Initializer | 0.0718 | 0.9789 | | | + Relu & He Initializer | 1.4620 | 0.5356 |
| + Relu & He Initializer & Momentum | 0.0696 | 0.9783 | | | + Relu & He Initializer & Momentum | 1.4145 | 0.5391 |
| + Relu & He Initializer & Adam | 0.0686 | 0.9801 | | | + Relu & He Initializer & Adam | 1.5610 | 0.5546 |
| + Leaky Relu (alpha=0.1) & He Initializer & Adam | 0.0716 | 0.9807 | | | + Leaky Relu (alpha=0.01) & He Initializer & Adam | 1.3282 | 0.5572 |
| + Selu & He Initializer & Adam | 0.0716 | 0.9807 | | | + Selu & He Initializer & Adam | 1.3282 | 0.5572 |
| + Relu & He Initializer & Adam & Learning Rate Decay | 0.0726 | 0.9802 | | | + Relu & He Initializer & Adam & Learning Rate Decay | 1.5508 | 0.5575 |
| + Relu & He Initializer & Adam & Stratified mini-batch training | 0.0686 | 0.9800 | | | + Relu & He Initializer & Adam & Stratified mini-batch training | 1.5140 | 0.5593 |
| + Relu & He Initializer & Adam & Dropout 0.3 | 0.0610 | 0.9827 | | | + Relu & He Initializer & Adam & Dropout 0.3 | 1.3406 | 0.5927 |
| + Relu & He Initializer & Adam & Learning Rate Decay & Dropout | 0.0607 | 0.9834 | | | + Relu & He Initializer & Adam & Learning Rate Decay & Dropout | 1.2485 | 0.5933 |
| + Relu & He Initializer & Adam & Learning Rate Decay & Dropout & Stratified mini-batch training | 0.0591 | 0.9827 | | | + Relu & He Initializer & Adam & Learning Rate Decay & Dropout & Stratified mini-batch training | 1.2444 | 0.5935 |
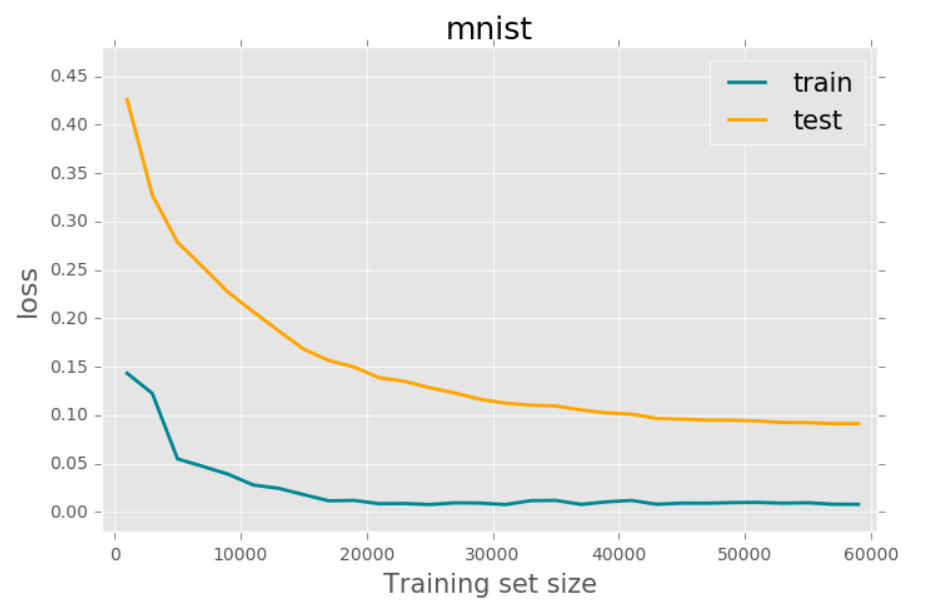
Learning Curve
Lincense
MIT