| 序号 | 文件名 | 数据内容 |
|---|---|---|
| 1 | sku_info.csv | SKU基本信息 |
| 2 | sku_attr.csv | SKU属性信息 |
| 3 | sku_prom.csv | 促销信息 |
| 4 | sku_sales.csv | 销售信息 |
| 5 | sku_prom_testing_2018Jan.csv | 2018年1月促销信息 |
| 6 | sku_quantile.csv | 目标预测分位点 |
组织架构图

- 整个比赛数据结构图如上,是以sku_id为核心拓展
- info表中first、second third sku_id有种层级关系,就是说确定了下级上级一定唯一确定,这四个四选一即可,不用两两三三组合
- info表中brand不独立也就是说有些brand会对应多个维度。。甚至171号brand经营了7和6两个first,有且仅有这一个brand经营两种或以上first
- Attr表中attr和attr_values都不对应。。这里看上去有些奇怪但是确实存在一个values对应多个attr的情况
- Prom里面type只有10,6,4,1,测试集中同样只有这四种,考虑使用one-hot
- prom里面third还是和skuid对应的。。像info中一样,搞不清楚主办方搞这个做什么。。。
- Sales信息最多,目前可以肯定date的分布一定保证是连续的,但是有很多不是两年中全部数据都有,但是中间不会间断,因为count和数据间隔之间只差30的整数倍(6、11月数据的缺失导致),比如有的2016-07-15~2017-05-16这样
- vendibility是个布尔型的数(0/1),original_price很小理解成原价感觉好奇怪。。。Discount就是折扣率。。。Price和折扣率是不是和pro_type一一对应还有待验证(这数据划分的。。京东真不让人省心。。真混乱),如果不是一一对应真不知道这有啥用。。。测试集中又没有,只能作为历史信息。。感觉历史上折扣率平均值这种特征真心没用
- Vendibility啥意思??是不是留了货???有啥用。。怎么用。。。不知道。。。
- 关于Prom:同一天可能有多种促销方式。。。。我们还是onehot吧。。。。
- 促销信息有重复!有重复!test里没有,所以我们相当于消去重复置为1
- Prom_type不分开只看组合之后分类,比如一个id就是(1,4,6,10)
- attr表里每个sku_id对应多个attr和attr_value啊!!!咋处理。。难道就提取每个sku有几个attr?几个attr_value??值太大,one-hot得话矩阵会异常稀疏特征巨多啊!!!
- 训练集,测试集: train2016->train201701 预测 train2017->test201801 训练集,验证集,调参: train2016->train201701 预测 train201612_201711->train201712
- 想不清楚各个特征应该用sum还是mean.....
- 缺失值暂时不处理?
- 损失函数咋写啊
- 先对比看看吧 我们现在要解决的问题就是:
- 决定自己的验证集好不好用 选一个与结果对应的验证集
- 人工去特征?看看重要性?
- 看看损失函数 验证函数那边是不是可以改进 提高效率
- xgboost调参
- 尝试其他的模型
- 自定义的损失函数 验证函数那边应该没问题了是嘛
- 深入理解 弄一些新的特征
- dc_id=0
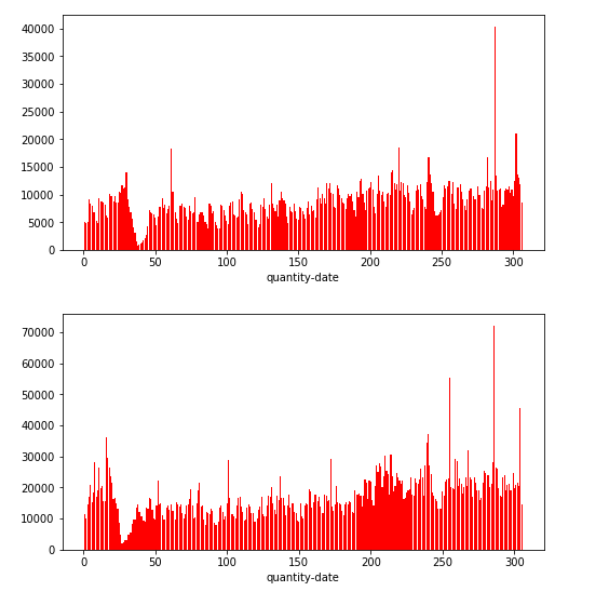
- dc_id=1
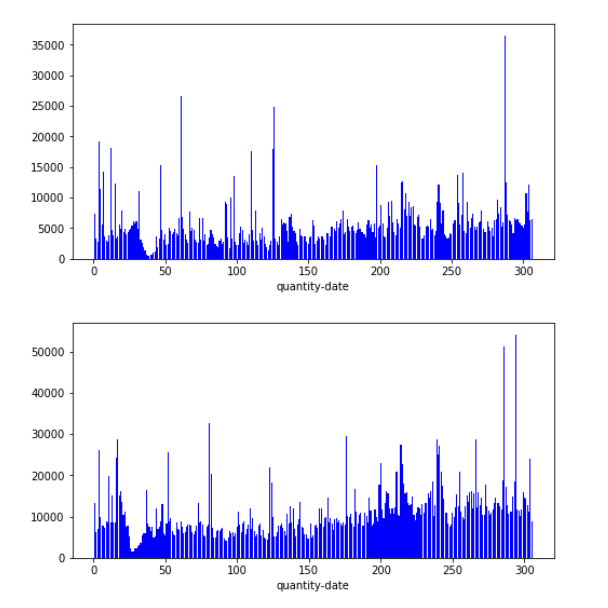
- dc_id=2
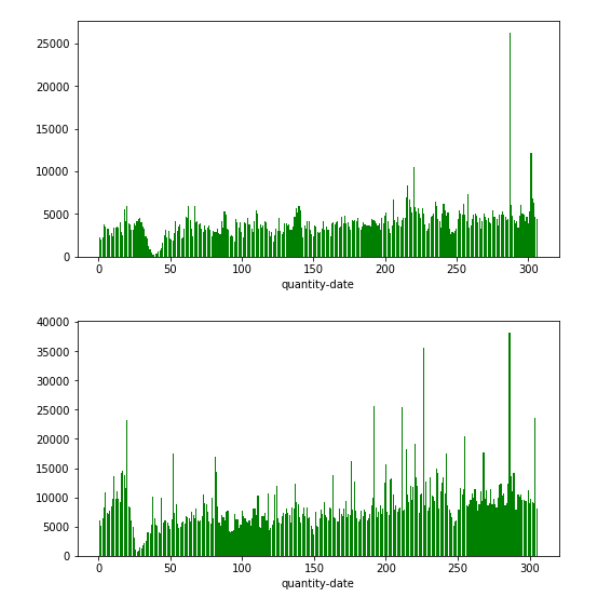
- dc_id=3
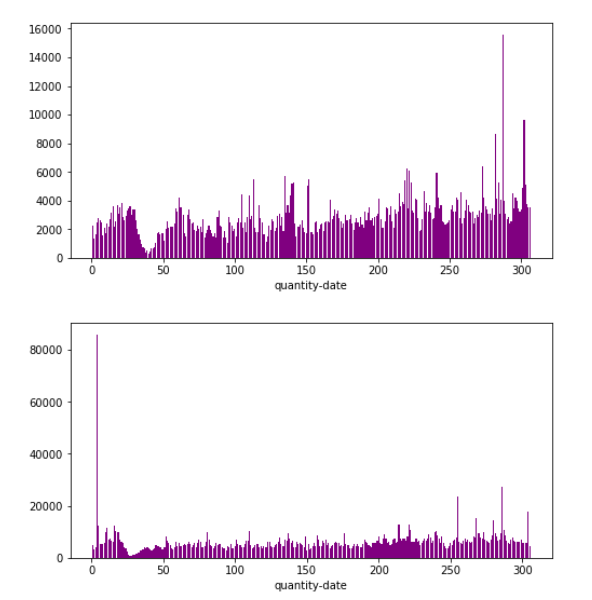
- dc_id=0,1,2,3
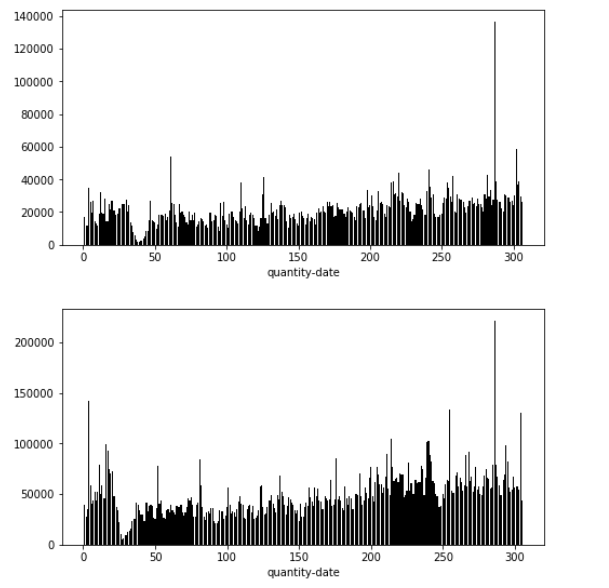
- 每年分布规律大致和上年相同,但是数值上确都接近翻倍,整体分布还是呈现一个连续的过程,考虑着重提取2018-1月之前几个月的信息,这部分建议用sum,让机器学习到附近连续的规律去确定销量的基值(直流成分。。。。),而提取2017-1月信息的时候我们要尽量使用mean()消除绝对销量的影响去学习波动的规律(谐波成分。。。。)
- 看数据分布还是春节有个下凹,可以考虑把二月数据删除,然后有一些异常高的数值例如年末那里,也可以考虑删除
- dc_id=是one-hot呢还是分别训练学习呢。。。?感觉都是一个问题必然有共性,数据量又有点小预计的特征数还很多我们还是one-hot吧。。。(注意它本身还是要作为历史数据merge的id的)
- 历史数据的划分和学习范围是很值得深究和思考的部分的感觉。。。





- 深入理解xgboost原理,划分偏差和方差,调参实现偏差和方差的平衡
- 一开始就要可视化数据进行数据分布的分析,合适得寻找验证集,使得验证集和测试集的分布尽可能相同,避免“炼丹式”调参
- 尝试模型融合 lightgbm?
- 对于特征除了特征工程自动化(时序特征)以外是否可以考虑人为构建特征
- 画图分析预测的结果准确度,看看哪些种类预测得好,哪些预测得不好,对比尝试改善不好的一部分
- 快速实现baseline在这基础上不断迭代提高,多种方向尝试前先尽可能分析会产生的影响和预期效果,如果理论提升效果很小,就不要花时间尝试了才知道没有用。
- 控制特征数和无意义的复杂特征,避免矩阵太稀疏;同时降低模型的可解释性
- 不仅仅是简单给出一个结论,要思考能够从算法和数据中挖掘出什么信息。
- 第一名 :
- 一开始进行细致的数据分析:
- 明显的时间趋势,越近的数据预测力越强-->数据选取、时间加权
- 20%的商品带来了80%以上的成本-->着重优化目标
- 一些类别商品需求不确定性极大—>对该商品进行针对性的识别和优化
- 业务场景决定了算法选取
- 理论:估计的是分布的尾巴样本极少
- 实践:加入简单规则后几乎没有改进
- 结论:历史销量直接统计分位数
- 程序设计关键点
- 加速技巧:numpy矩阵运算替代循环
- 基于采样的数值近似和估计(非参估计比参数估计好)
- 高质量的仿真环境
- 抓住主要矛盾,数据可视化使得设计算法前对问题有直觉判断
- 一开始进行细致的数据分析:
- 第二名:
- 特征工程
- 销量的指数加权
- 多重统计值:min、max、std、median、count、skew
- 没太看懂它的数据集构造方式。。。
- lightGBM
- 特征工程
- 第三名:
- lightGBM和RNN模型融合
- 删除春节数据
- 比较不同时间间隔Spearman correlation的heatmap确定预测时间区间:月均销量相关性高,月均销量预测更加准确
- 特征工程
- 销量/销量差的均值/指数加权(随时间变化,越近越相关)
- 有/无促销的天对应的销量:用促销形式作为key进行特征工程自动化
- 时间段上前向后向处理:前i天中,最后/最先有各类促销/销量的时间间隔
- 提取形式:标准差
- 注意数据划分方式。。。
- 为了减少异常数据影响:对label进行对数变换/其他变换
- ensemble方式多样化。。。。。?