A class with helper methods to accelerate exploration of a Dataset
An instance of the explorer class is initialized with a Pandas DataFrame of features (i.e. independent variables) and a Pandas Series containing the target values (i.e., dependent variables).
The following helper methods are available:
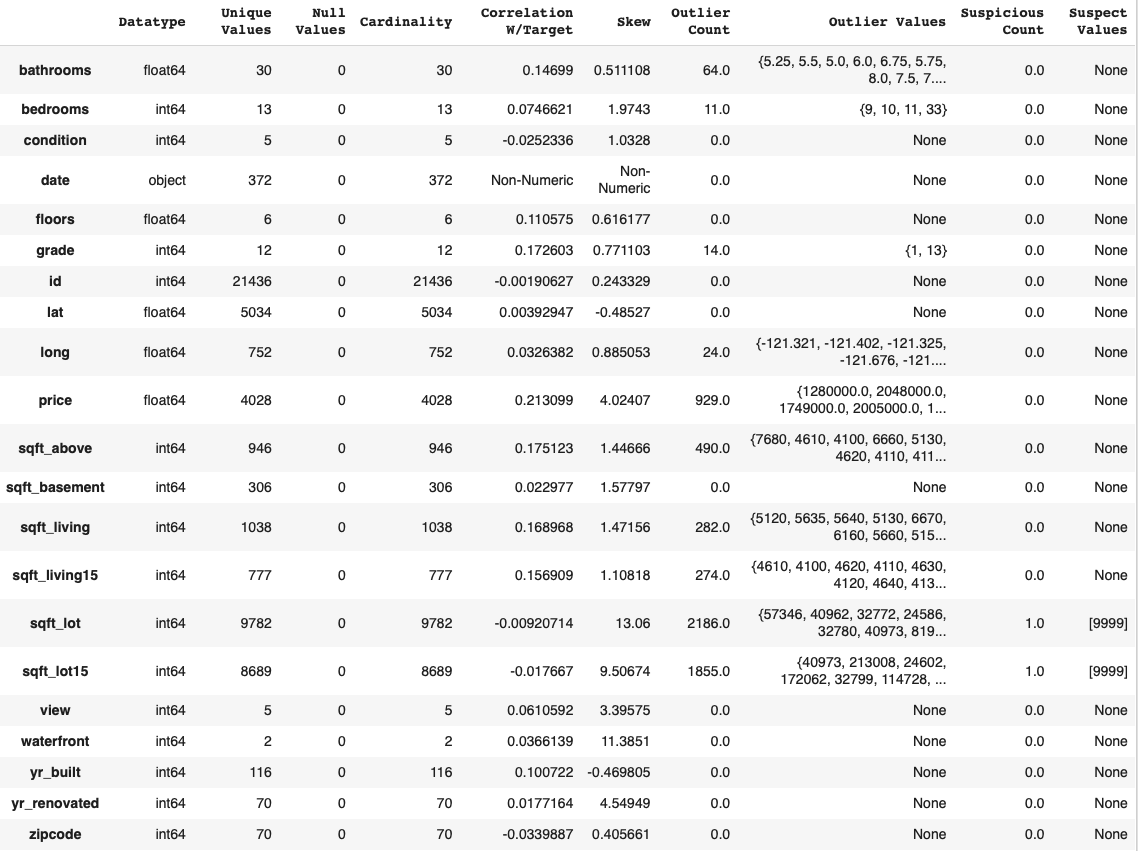
- data_dict(self): Creates a DataFrame intended to orient the user to a dataset. For each column of the DataFrame, the following is summarized: datatype, cardinality, null values, correlation w/target, skew, outlier count, list of outlier values, count of suspicious values, and a list of suspicious values.
- get_cardinality(self, include_numeric): Determines the cardinality of each column.
- corr_with_target(self): Determines correlations of numeric columns with a specified target.
- detect_suspicious(self, custom_vals): Searches a DataFrame for values that should possibly be considered np.nan.
- detect_outliers(self, method, threshold): Identify outliers in numeric columns using the specified outlier detection method.
- outlier_modified_z_score(self, threshold): Identify outliers in numeric columns using the modified z score range method. A modified z score uses the median rather than the mean.
- outlier_z_score(self, threshold): Identify outliers in numeric columns using the z-score method.
- outlier_iqr(self, threshold): Identify outliers in numeric columns using the interquartile range method.
pip install -i https://test.pypi.org/simple/ data-explorer
The following code block returns a useful summary that can inform further data exploration, cleaning, and engineering:
# Import dataset to use for demonstration purposes
import pandas as pd
king = pd.read_csv('https://raw.githubusercontent.com/ryanleeallred/datasets/master/kc_house_data.csv')
# Assumes the data_explorer package has already been installed
from Data_Explorer.explorer import explorer
# Initialize an instance of the explorer class
ex = explorer(king, king['price'])
# Call the data_dict() method
ex.data_dict()