SIT CSC2101 (Professional Software Development and Team Project 2)
-
Your Hyperviser is set to enable Windows Subsystem for Linux, otherwise see here for me information on how to install WSL
-
An Nvidia GeForce GTX/RTX Graphics Processing Unit (GPU) or Graphics Card which is CUDA enabled
-
At least 16GB of RAM and a lot of swap space on disk
-
At least 8GB of VRAM on your graphics card with 16GB of shared memory swap space
-
Installed
docker AND docker-composeor havedocker desktop with wsl2 integration (Ubuntu)
-
Run as admin in Windows Powershell, run wsl -l -v to check what sub-systems you have and ensure that they are version 2
-
Restart wsl by running
wsl --shutdownand running it again or re-opening up Ubuntu (for example)
---Only execute step 2 and 3 for this section if running linux system---
-
Run Windows Powershell and enter into your wsl -- OR Run a distro of your choice from the Microsoft Store (i.e Ubuntu)
-
Important: Download GeForce Experience to acquire the latest Nvidia graphics drivers for your host machine specific Operating System
-
Important: Follow these steps under the "> Base Installer" tab sequentially to install the necessary drivers to allow wsl/linux distro to interface to your GPU. Ensure that you choose the correct versions for your specific graphics drivers and Operating System
-
Run "nvidia-smi" on the terminal to confirm that the necessary drivers have been properly installed.
-
It is important to note that the NVIDIA cuda toolkit installation steps do not work as they install the newest versions of the toolkit for usage. However, it is very important to understand that Pytorch and Tensorflow is very sensitive to the version of the CUDA toolkit and cuDNN versions, in particular the newer versions or the installation will just NOT work and default to use the CPU instead. So make sure to install the proper version of the CUDA toolkit 11.8.0 and cuDNN 11.9
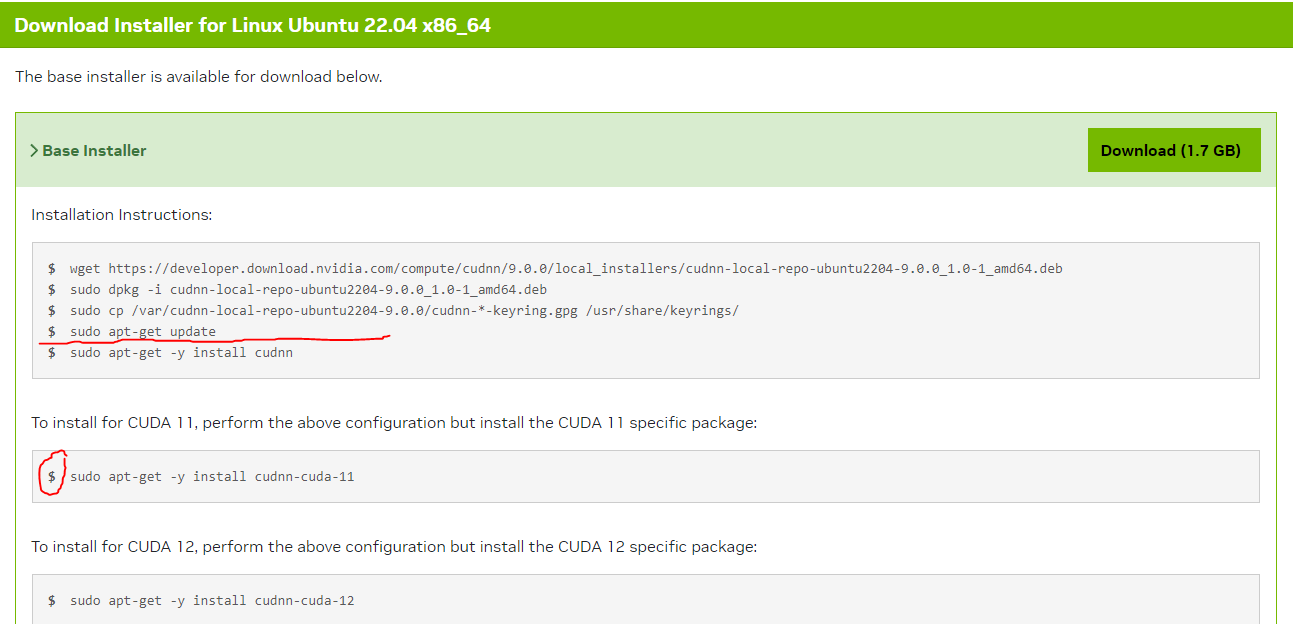 Skip the last step
Skip the last step sudo apt-get -y install cudnnand move to the step to dosudo apt-get -y install cudnn-cuda-11instead. This is to make sure that you have consistent cuda drivers for the project, being at 11.8.0 for the toolkit. -
Bring up Windows Powershell again and navigate yourself to the current User of the computer (i.e: C:\Users\Alice) folder and create a new file called .wslconfig
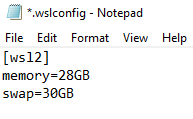 This is to increase the amount of virtual memory for any WSL or docker containers depending on the size of the model/project you intend to use this for.
This is to increase the amount of virtual memory for any WSL or docker containers depending on the size of the model/project you intend to use this for. -
Configure the amount of memory and swap space as required such that the model is able to properly fit within the physical constraints available to your hardware
-
Restart wsl by running
wsl --shutdown


-
If you have yet to do so, use a web browser, download Docker-desktop from their website and install
dockeranddocker-composeto run the microservice containers, remember to also enable wsl integration with your distro and enable kubernetes in the settings as well. -
Using wsl, check for successful installation by running
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi, if a table like this does not show up as an echo from your docker container, perhaps you have missed a step somewhere in the installation process. At bare minimum, you should be able to run nvidia-smi on your wsl terminal.
-
cd CSC2102 -
docker-compose up -d -
Wait for the server to download the shard required for loading the model into your GPU.
-
docker-compose down
-
cd CSC2102 -
docker-compose -f docker-compose-llm.yml up -d -
Create K8s namespace
kubectl apply -f ./namespace.yaml -
Start K8s replicasets and statefulsets
kubectl apply -f ./mariadb.yamlkubectl apply -f ./mongodb.yamlkubectl apply -f ./server.yaml -
Stop cluster
kubectl delete -f .docker-compose -f docker-compose-llm.yml down
-
For debugging purposes on the model, either use
docker logs llm(or container name), ordocker-compose logs llm(or container name) -
docker run --name llm -it -p 8080:8080 -v /path/to/mount/point:/server/data --gpus all *image_name* bashto run the container as a standalone for further debugging in the bash shell
- Monitor the processes using task manager,
toporhtopto see whether there is enough RAM for the model to be loaded into memory - Check your .wslconfig on the memory configuration size
- Make sure to restart your wsl by running
wsl --shutdown