, and many more [1].

Note: This project is mostly inspired by this helpful link.
To detect the location of the car license plate in the images, Yolov7 pre-trained model is used in this project. Here is a short description of this high-performing model:
Yolov7 was introduced in July 2022 and outperforms other object detection models in terms of accuracy and speed. In the image below, Yolov7's performance is compared to other well-known object detectors:
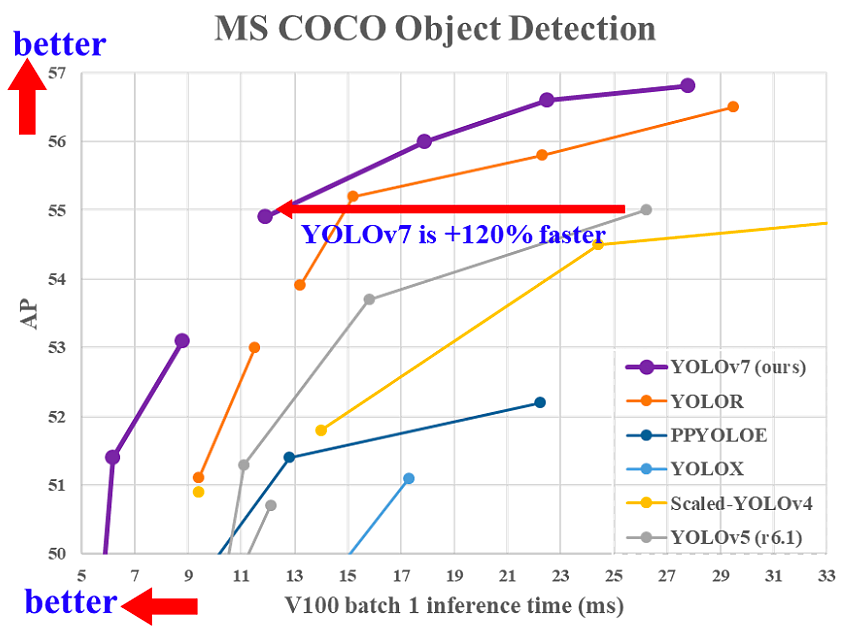
The Yolov7 model was trained on MS COOC dataset and no pre-trained weights were used for training [2].
In Yolov7 architecture, Extended Efficient Layer Aggregation Network (E-ELAN) was used which leads the model to learn more features. Moreover, the architecture of Yolov7 has scaled by concatenating other models such as YOLO-R which can address different speeds for inference. Thanks to bag-of-freebies, Yolov7 has better accuracy without any increment in the inference speed [3].
More information is available at this link.
In order to train the model, two car datasets are used which have annotations for license plates. One of them is Car License Plate Detection which consists of 433 images of license plates. Another dataset is IranianCarsNumberPlate which has 442 images of Persian cars. The annotations of both datasets are in XML format.
To easily generate a uniform dataset out of the above-mentioned datasets, roboflow platform is used. It automatically loads the images with their corresponding annotations, manages train/val/test splits, and also adds preprocessing and augmentation steps to the dataset. Finally, it gives a few lines of code which can easily be integerated into the python code.
Training is last for about 1 hour for 30 epochs. In the following image, the result of the training is shown:

As can be seen, the precision, recall, and mAP@0.5 (mAP calculated at IOU threshold 0.5) of both training and validation data reach around 0.9 through training time.
Note: You might encounter the following error when you want to train the yolov7 model:
Indices should be either on CPU or on the same device as the indexed tensor
To handle this bug, some minor changes to the loss.py file as mentioned in this link will help.
Here a few test images whose license plate are correctly predicted by the trained model are shown. The model could correctly detect license plates and draw their corresponding bounding boxes in different circumstances with different angles and illumination. In addition, it could detect two or more license plates whenever more cars are available in the image:



There are also some false positives where the model incorrectly detects some rectangular shapes as license plate:


Note: For this step, Train_Yolov7_for_LPD.ipynb is used.
After detecting the location of the license plate of the car in an image, now, it is time to recognize the exact character and numbers written on the plate. For this step, many methods are described in the literature. One of them is using open source packages like Tesseract and EasyOCR which support many languages including Persian. Unfortunately, the problem with them is that they must be fine-tuned especially for the font used in Persian license plates. Otherwise, they do not give acceptable results in recognizing the characters [4].
Another way for OCR of the license plate is to find out where the location of each character/number is in the image by image processing techniques and then give it to a trained image classification model to distinguish it correctly. Although it is a more acceptable method than the abovementioned ones, it needs a good collection of data for each character/number used in the license plate for training. In addition, since image processing techniques are somehow a manual way of feature engineering, it might have a shortage to generalize rules for all circumstances. Despite the limits, this method is implemented in step 2.1 and results are discussed.
Another method is to train an object detection model such as yolov7, this time, for recognizing characters/numbers in the license plates of cars. This method is implemented and discussed in step 2.2.
To train a model to recognize the Persian characters and numbers, we need to have a related dataset. After some research, a dataset named Iranis was found which is appropriate for training license plate recognition applications. Iranis is a large-scale dataset consisting of more than 83000 real-world images of Persian characters and numbers of car license plates [5].
In the image below, some sample images of this dataset for each character and number are shown:

As can be seen, there are 28 classes in this dataset. It is good to mention that license plates with red, green, and yellow backgrounds are related to governmental, police and public transportation, and taxi cars. While the white background license plates are referred to the normal private cars.
For training a neural network, a dataset should be split into training, validation, and test sets. Working with the raw dataset of Iranis would not be helpful. Thus, a python package named split-folders is used to split a dataset into different abovementioned sets. In this way, each character and number have the same ratio in training, validation, and test sets.
To recognize each character/number, first, we should train an image classification model on our prepared dataset. A roughly simple convolutional neural network, which its architecture is shown in the image below and drawn by this website, is used for classification task:

After training the CNN model for about 10 epochs, the validation and training loss becomes very small. In the graphs below, the accuracy and loss for training and validation in each epoch are shown:

Moreover, the confusion matrix shows that the number of true positives for each class is much higher than false predictions as the diagonal values show higher numbers:

Note: For this step, Train_CNN_Model_for_LPR.ipynb is used.
After training a model to classify each character/number, it is time to segment each one and feed it to the model to recognize which character it is. In this section, several image processing techniques have been used for the segmentation of characters in the detected plate.
In the following, the general steps which are taken for character segmentation and recognition are listed:
- Detect the location of the plate and change the detected plate to a gray image
- Find the longest line in the image and calculate the angle of the longest line with respect to the image
- Rotate the image if the calculated angle is greater than 10 or smaller than -10; in this way, the later classification problem will be easier [6]
- Preprocess the image including applying gaussian blur, otsu threshold, and dilation to make characters in the plate recognizable from noise and background, then find connected contours [7]
- Search through found connected white blobs and check some criteria such as ratio and area; if the ratio of height to the width of the rectangle containing the blob is greater than 0.8 and the area of the rectangle is greater than 100 then apply the image classification to recognize which character or number it is based on our trained ocr model [8]
- Print the number of the license plate and save the annotated image into the drive
In the image below, the result of some of the abovementioned steps for correctly recognized license plates are shown:

Although image processing will get good results in some cases, it suffers from the manual tuning of some manual parameters such as the size of filters or ratio and area which was discussed earlier. In addition, some Persian characters such as B (ب) which has dots on its own, cannot be recognized as a whole character, and their dots can be incorrectly classified as 0 (۰). Moreover, sometimes after thresholding, some noises are big enough that considered white blobs and feed into the model for classification which leads to wrong detected number plates.
Note: For this step, LPR_Image_Processing.ipynb is used.
In this step, instead of using image processing techniques, a new yolov7 model is used for object detection of characters inside license plate.
First, we need an appropriate dataset for training an object detection model to recognize the Persian character and numbers available on car license plates. Since no such dataset was found through research, some of the data available in Iran-Vehicle-plate-dataset and IranianCarsNumberPlate are annotated manually.
For this, the plate regions of images of the above datasets are cropped and then feed into the roboflow platform. After that, around 200 images are annotated, in such a way that each character or number in the license plate is determined by a bounding box and labeled to its corresponding class. There are 25 classes including numbers from 0 to 9 and characters repeated in private Persian cars. After the train and validation split, some augmentation including adding noise, blurring, and rotation is added to the data. In this way, the number of images reaches around 560 images.
In the image below, a view of some of the annotated images is shown:

This annotated dataset is publicly available here.
Note: For this step, Separate_Plates_from_Car_Images.ipynb is used.
Like training yolov7 for object detection of license plates in the images, here, a model is trained for detecting the location of each character in the license plate and classifying it. The prepared dataset from the previous step is fed into the model. The model is trained for 100 epochs for about 1 hour. The result for the last epoch is 0.968, 0.993, 0.991, and 0.661 for precision, recall, mAP@0.5, and mAP@.5:.95 respectively.
In the image below, the performance of the model during the training is shown. It is clear that the performance gets improved during the time:

In the image below, the prediction of model for some test cases is shown:

Note: For this step, Train_Yolov7_for_LPR.ipynb is used.
After training the model using yolov7, in this step, a pipeline is created for two main steps of the project. First, detecting the license plate and second recognizing the character and numbers of the plate for test images. The code written for this part is mainly get from the detect.py file of yolov7 codes.
In the image below, the result of some of the abovementioned steps for correctly recognized license plates are shown:

After repeating the prediction on more test images, it is revealed that the performance of this pipeline is much better than the image processing techniques results. However, the predicted number plates are sensitive to the hyperparameter called conf which is the confidence level of prediction. If it is set too small, noises can be recognized as a character. On the other hand, by setting it to too high values, some characters or numbers inside the license plate will be missed.
Note: For this step, LPR-using-yolov7.ipynb is used.
In this project, the detection and recognition of Persian license plates were implemented. For future work, some ideas are listed below:
- Annotate more data for OCR
- Gather more data as the test set
- Train for more epochs and tune the hyperparameters to improve the performance of models
- Investigate misclassified license plates for detection and characters/numbers for recognition
- Recognize the characters/numbers of license plates other than private cars such as governmental, police, and public transportation
- Recognize the characters/numbers of free zone and temporary passing license plates
- Deploy the trained model on a web/mobile application and examine the performance on real-world images
- Extend the overall idea of detecting and recognizing license plates on images into videos for tracked cars