Applying valute iteration and MDP to to teach a reinforcement learning agent playing tic-tac-toe. The code is written in Python from scratch, and the policy is near-optimal.
The memory folder contains initialized and re-evaluated state-value pairs. (load using Pickle)
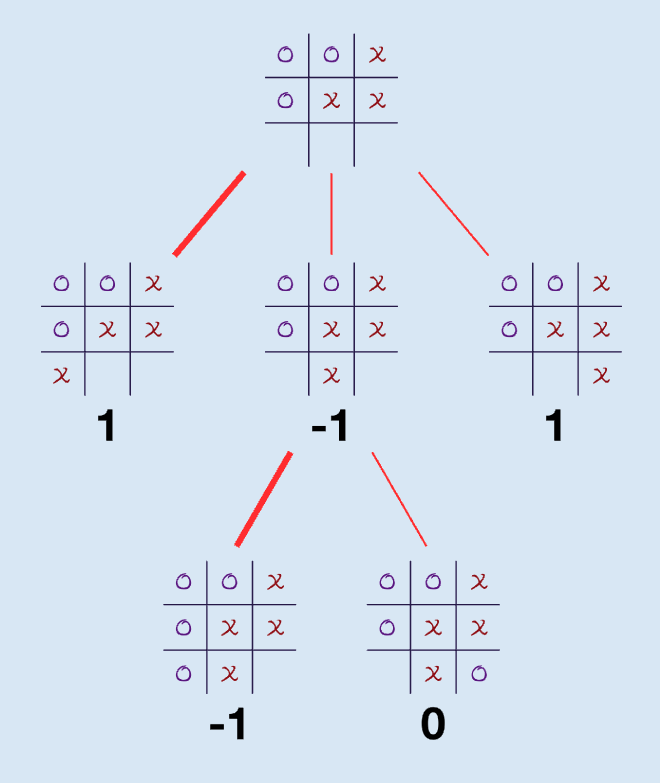
Step 1. Extract all the possible states and initialize their values:
python3 state_extractor.pyStep 2. Run value iteration over all the states until convergence:
python3 value_iterator.pyStep 3. Several ways to check the policy
- Method I: AI plays against a randomly playing agent:
python3 markov_eval.py- Method II: AI plays against itself:
python3 against_itself.py- Method III: AI plays against human:
python3 human.py