Michael & Sketch assignment solution repository.
This repository will have all the code and documentation needed for the proposed exercises.
The target of this solution is to have a tiny CI/CD environment for the mgtascu/guava open-source project which was previously forked from google/guava.
This solution is oriented on EaC(everything as code). Some of the benefits from having EaC are:
- Reducing human intervention which is error prone
- A better solution management (versioning, portability, security, etc)
- Consistency and scalability
The underlying environment for the Jenkins server is cloud-based (AWS) which is provisioned through terraform IaC.
The Jenkins web-server is running inside a docker container, making it fast to install, running in an isolated environment, thus easy to replicate on another infrastructure. The configuration, plugins and the job are all generated by code, with little to none human interaction, with the help of DevOps tools like JCasc, JobDSL, GroovyDSL, Jenkins Job Builder.
guava is a java with maven project, which usually means there are a lot of dependencies when running the build. Mounting the docker daemon into the Jenkins container, enables us to run the build itself in a separate container, prepared to execute the maven lifecycle of this build, therefore skipping the need to prepare an environment for the run.
The GitHub status checks are easy to install through the UI and for the purpose of this exercise I did so. However, there is are ways to automatically set them up, by making use of the graphql calls to the github's api, or by using terraform's github provider
Note: to run the solution as smoothly as possible, the configurability of the execution is reduced considerably, aiming to lessen the data needed.
Assuming there is an AWS account available, here is a list of requirements to run the solution.
-
An environment with
awscliandterraforminstalled. While developing the solution, I used the at2.micro AWS EC2 instancerunning Amazon Linux 2 and the following tool versions.aws-cli/1.18.147 Python/2.7.18 Linux/5.10.109-104.500.amzn2.x86_64 botocore/1.18.6 or aws-cli/2.2.31 Python/3.8.8 Darwin/21.4.0 exe/x86_64 prompt/off
Terraform v1.1.9
-
Subscribe to the AWS Marketplace Centos AMI, if you haven't already. The terraform apply command will require this step and fail otherwise.
-
The
awsclimust be configured with the credentials of an IAM user with the proper access to create and delete the required infra(sg, key pairs and instances, in ec2). To achieve this, runaws configureand input your user details.AWS Access Key ID []: <your_user_access_key_id>
AWS Secret Access Key []: <your_user_secret_access_key>
Default region name []: eu-west-1
Default output format []: json
Note: The
ami-idused in the solution belongs to eu-west-1(Ireland) region. Please use the same region, to avoid searching for a matchingamiin a different region. -
Place the
solutionrepository to a location of your choosing in the environment and switch to that location. I will refer to it as/tmp/solutionin the following section.
In this section we go through a series of steps to successfully run the solution.
To create and execute a simple build pipeline for the guava repository, firstly we need an environment with this capability. We will be using terraform to provision a landing zone, composed of a security group, a ssh key pair and an EC2 t3.medium instance.
Note: A github token with minimal access was created for this exercise. For security reasons, it cannot be pushed to the remote repository. Please find it in the demo_token.txt attached file.
- Change the working directory to
tfcodecd /tmp/solution/tfcode - Initializing the
terraformworking directory containing theterraformconfiguration filesterraform init - Create a
terraform planto visualize the set of changes which will be applied to your AWS accountterraform plan -var="github_token=<the_additionally_shared_token>" - Apply the previously planned changes to create the landing zone automatically
terraform apply -var="github_token=<the_additionally_shared_token>"This operation will take a few minutes
After the apply command has finished running, there will be an output printed to the console with some useful data, similar to the one below such as the Jenkins access URL(jenkins_server_url) and the generated ssh key to access the Jenkins server (ssh_key_name):
Apply complete! Resources: 5 added, 0 changed, 0 destroyed. Outputs: ec2_id = "i-02842e6e3b2188592" ec2_private_ip = "172.31.23.109" ec2_public_ip = "54.217.178.253" jenkins_server_url = "http://ec2-54-217-178-253.eu-west-1.compute.amazonaws.com:8080" ssh_key_name = "jenkins_ssh_access_key.pem"
Now that the landing zone is create, let us run the solution
-
Copy the
jenkins_server_urlfrom the console, and paste it into a browser -
You will be prompted with a Jenkins login
Login Credentials: - username: user - password: userpass -
Once logged in, you will find a
seedjob waiting for you :). Use this job to generate the pipeline for theguavarepository, by building it straight away. To do so, click on thejob nameand the onBuild Now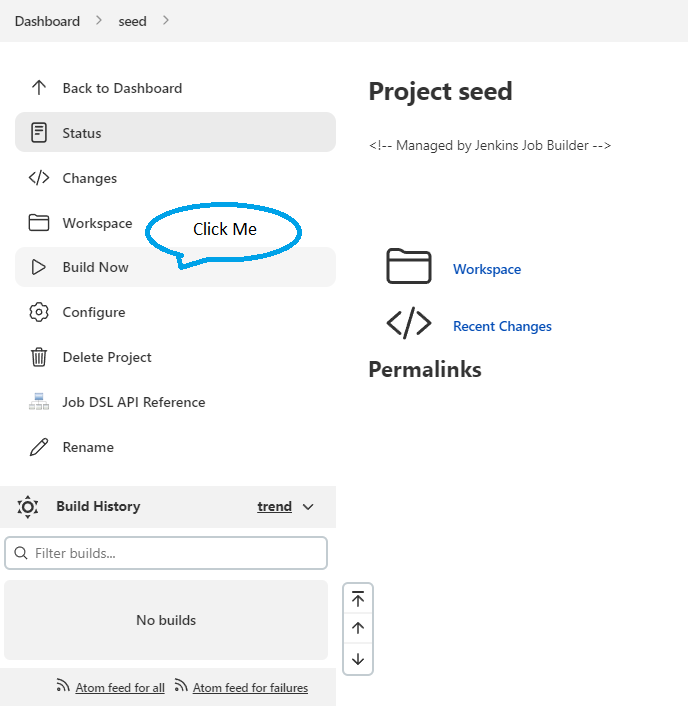
-
After this build completed, the
guavarepository build pipeline is created and already running the scan for existing PRs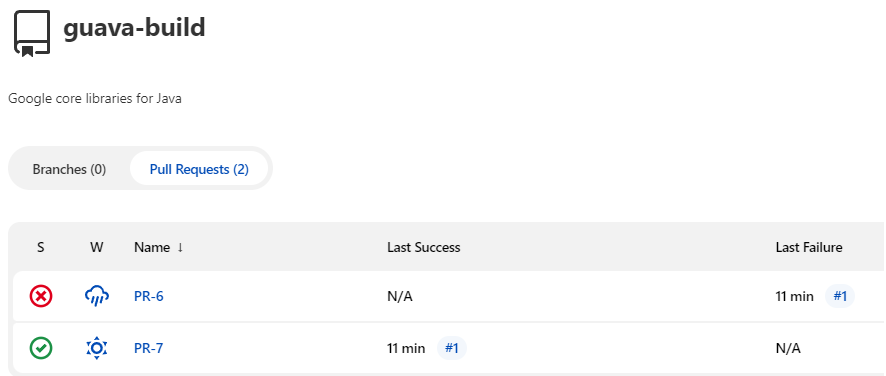
-
In the fork that I have prepared for this exercise, there are 2 PRs that are matching the scan criteria, thus they are discovered and built right away. A run consists of 3 stages simple stages, like in the below screenshot
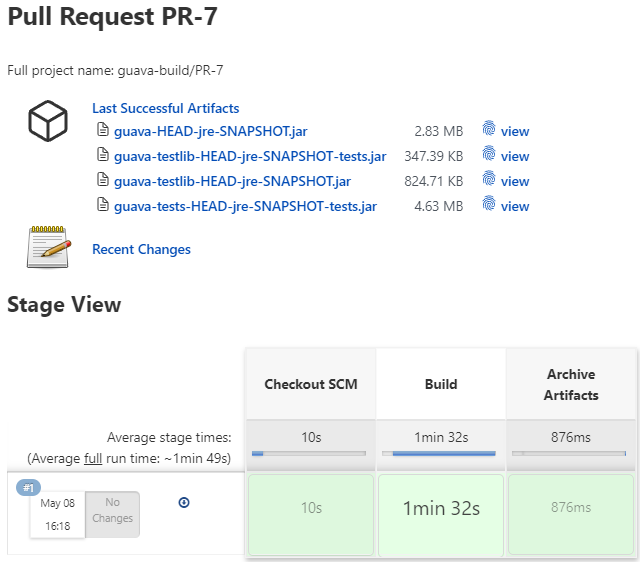
-
After the builds succeeded, the build artifacts are available on the build page to easily download them




To shell case completing all the challenges of this exercise, I'll show the GitHub integration side in this section.
-
Branch Protection Rule
-
On the repository's
settingspage, underbranches, I have added a branch protection rule for therelease/*branch name pattern. -
The rule currently applies to 3 branches and require the
continuous-integration/jenkins/pr-headstatus check to pass before unlocking the pull request merge into the matching branches.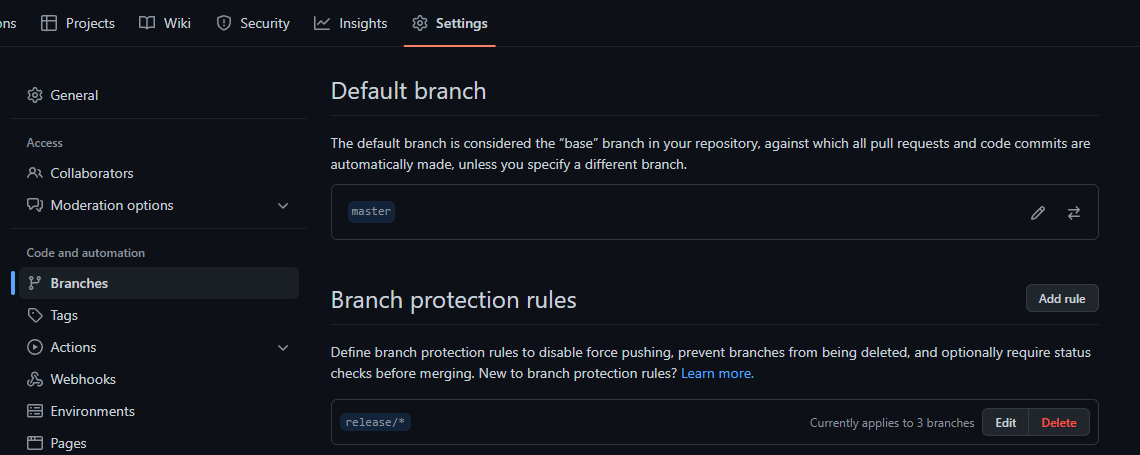
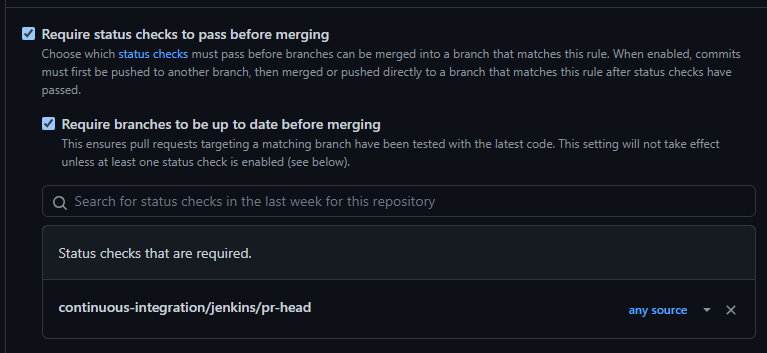
-
-
PR Status Checks
- In one of the prepared PRs there is a failure, introduced on purpose, to block the merge due to status check failing.
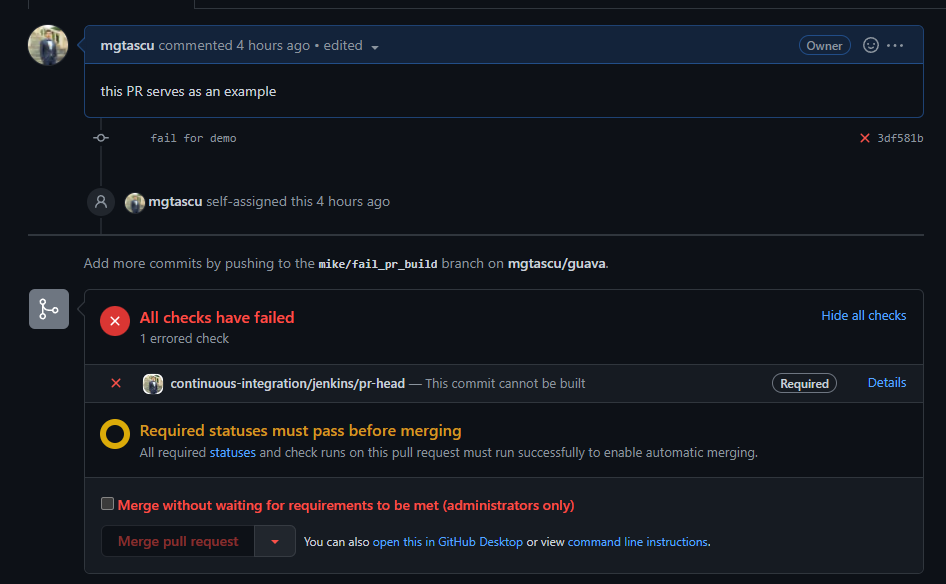
- The other PR however, has no issue at build time, therefore it passes the status check and allows the merge to happen.
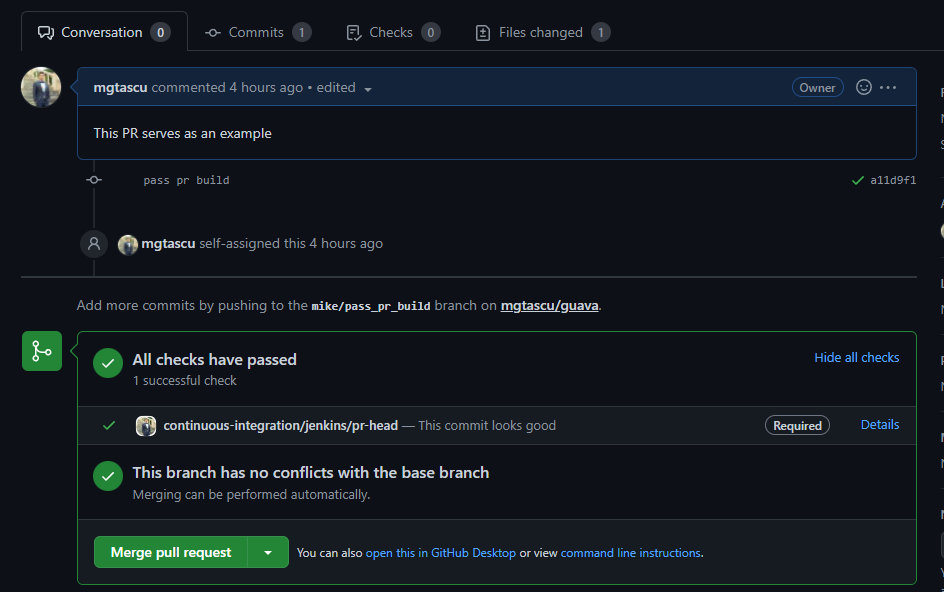
- In one of the prepared PRs there is a failure, introduced on purpose, to block the merge due to status check failing.




To avoid generating redundant cost, after the execution has solved its purpose, the environment can be destroyed easily from where it was created.
cd /tmp/solution/tfcode terraform destroy -var="github_token=<the_additionally_shared_token>"
While the solution presented in the first part of the documentation is quite robust, it is not designed to run continuous hours of operation nor to scale it to multiple pipelines. To bring it to a production level environment, we need to build more around this prototype.
Assuming AWS as the infrastructure provider,
Assuming
guavaas the main content in this production environment :D
The first area to bring into attention for a production ready environment, would be to scale the infrastructure.
Making use of the Auto-Scaling service and the Load balancer service in AWS, we can enable Jenkins to use more resources when needed while maintaining a cost efficient approach. In doing so, we can afford using workers for Jenkins, and avoid running any builds on the master.
Another very important aspect of the production environment would be to have a disaster recovery mechanism, ensuring zero-downtime(or closet to) of the environment. We can leverage terraform infrastructure as code, to replicate the environment in a different region. On the configuration side, having the server, plugins and jobs as code, will enable us to be up an running quickly.
Considering a cloud-native solution, and the 2 areas above, an ideal production infrastructure for Jenkins server would be to have the containerized Jenkins run in the control plane of AWSs managed kubernetes (EKS), while managing the workload on the node groups attached to the cluster. The node groups would be making use of auto-scaling to provision infrastructure dynamically and the Load balancer will offer access to the server. Jenkins will launch the workers inside pods and they can be tailored to the pipeline needs.
On the CI side of the pipeline, to achieve a production ready pipeline for the guava project, we can use a set of jobs to cover the development needs. In addition, an artifact repository manager would be used to store the build artifacts(ex. Artifactory, Nexus).
Considering the GitHub branching strategy and the matrix of configuration, we have the following scenarios:
-
CI (Continuous Integration) build
- Builds the
main/masterbranch, the current line of development. Always has the latest working code. - The lifecycle of this branch is permanent, as long as the repository exists.
- PRs to this branch can only be merged when both
mainandheadbranch are green. - Builds the code, runs the tests and pushes the artifacts to the "stable/release" repository.
- Builds the
-
Release build
- Builds the
release/*branches. Branched formmain/masterat a point in time, when releasing a version of the artifacts. Mainly used to address patches and hot-fixes for the released version. - The lifecycle of this branch ends when the support for the released version ends.
- PRs to this branch can only be merged when both
releaseandheadbranch are green. - Builds the code, runs the tests and pushes the artifacts to the "stable/release" repository.
- Builds the
-
PF (Pre-Flight/Pre-Commit) build
- Builds the
feature/privatebranches. Usually created by 1 developer to address a code change/feature implementation - The lifecycle of this branch stops when it is merged
- Builds the code quickly, by default skipping the tests run, but with an option to enable it if desired. Pushes the artifacts to the "sandbox/snapshot" repository.
- Builds the
-
PR (Pull-Request) build
- Builds a merge commit between the
baseand theheadbranch. - There is no branch associated with this. It exists until the PR is merged or closed.
- Builds the code, runs the tests and does not push any artifacts.
- Can be leveraged to validate if the merge breaks the CI/Release and for automating the merge.
- Builds a merge commit between the
For the CD side of the pipeline there isn't much to do, since the guava project is a core library for java. However, assuming we have an automated way to deploy and validate one or more use cases of this project, we can extend the CI and Release pipelines to include this part before promoting an artifact.
When implementing a production environment, a major consideration goes to the security factor. In order to address the security concerns about the infrastructure, we can apply AWSs best practices. The access to the builds can be role-based controlled by leveraging Jenkins plugins and the access to the Jenkins server can be restricted to allow only connections via a dedicated VPN.
Cost mitigation is crucial when building production or scaled environments. Keeping it in check from early on is a great idea, making it harder to snowball out of control and inducing downtime for maintenance and refactoring.
When building artifacts, versioning plays an important role in organizing and orchestrating a healthy CI/CD environment. Using versioning patters such as semantic versioning can prove to be quite beneficial in the long run.
Many features can boil down to having the required resources at a point in time. Using a cutting-edge tech stack sometimes introduce complexity and can delay things in a time of need. If time is of the essence when building a production environment like this one, a fixed infrastructure can be deployed using on-demand or reserved instances. The Jenkins server will be hosted on a node by itself and a couple of other instances will be connected to the master as permanent nodes. With containerized builds, the pipeline side won't change much form the initial approach and the solution is still robust, but things like high availability, scalability and cost optimization will be traded off.
To integrate an iOS build in our Jenkins server we need to enable it to build on iOS using XCode tools. After some research, it looks like there is a Jenkins plugin to handle XCode or we can run the commands from shell directly if we need to avoid using this plugin. On the system side, we need a server running macOS to connect is as a permanent node to our Jenkins server.
The pipeline will run on this node only(at least for the build part) and have the same set of jobs associated. The artifacts can be pushed to our artifact repository manager and then consumed in the other project. If there is a dependency to build the XCode project every time before running a build, we can setup a project dependency relationship using a Jenkins plugin or api calls.