I recommend cloning the repo git clone https://github.com/miararoy/feature_store.git and running the example.ipynb jupyter notebook. This will run the full flow implemented:
- Loading n_flow flows to database
- DS querying and saving the query
- DS performing feature extraction
- DS extracting features and saves etl
- BE runs the DS's query from the feature store
- BE runs the DS's feature extraction from the feature store
- DS handles queries and feature extraction (etl) - he knows what data to pull and how to handle it
- BE should not implement queries and feature extraction (etl) - this should be communicated via query_id and etl_id
- sql consistency: by using the same sql query in training and in serving (sql wrapping with where clause)
- etls should be deployed via git (atm link, in real life - via github integration) for version control
- schema comparison: when etl is saved to catalog it's data schema is saved and compared with new realtime data
- Data extration (queries):
- query warehouse for training DS models
- query in app (real time) data for real time predictions (serving)
- save and load queries to catalog for re-querying
- Feature extractions:
- load feature extraction (etl) transformations from git
- run feature exraction against query
- save and load feature extraction (etl) to catalog
- compare training and realtime data for 100% consistency
- TESTS!
- integration to github
- using pickling of etl (tried, impl. took too much time so I dropped it)
- train models on feature store
- Authentication and security
- Idempotency: hash the query with HMAC to make sure identical queries are not saved to database
- query cache - if query is performed a lot, cache it as view in a faster database
- Concurrency - some calls should be atomic but others should run in seperate threads.
Feature store encapsules data query and feature extraction and exposes APIs for both data scientists and backend engineers.
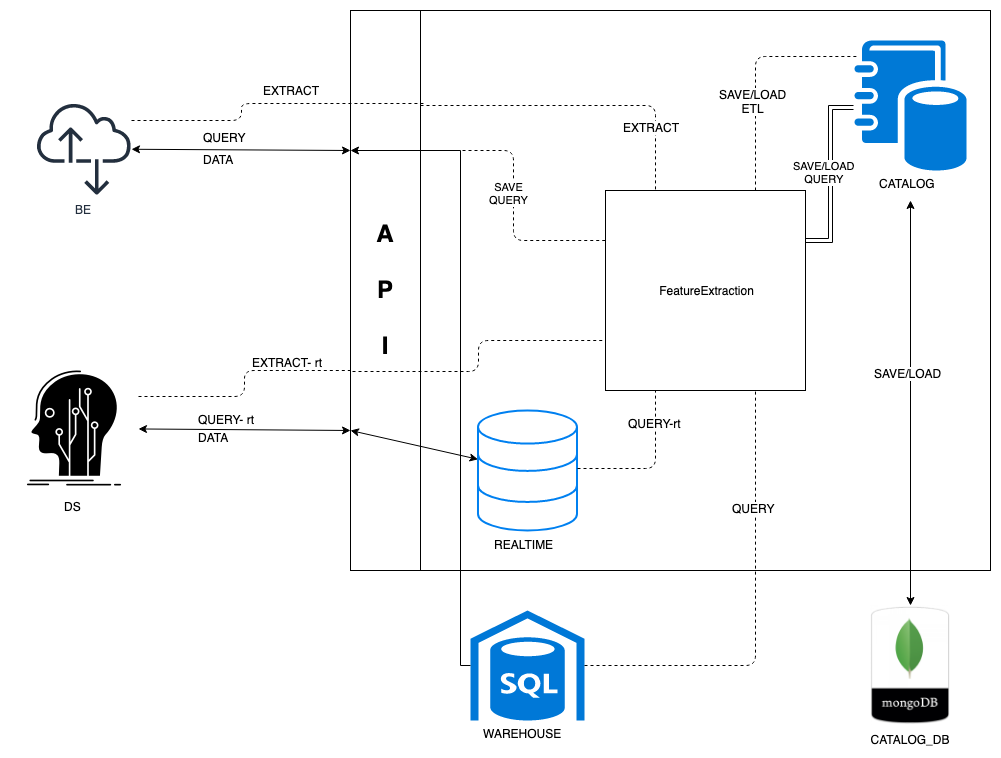
- Catalog: save and/or load queries and etls to catalog database (mongoDB)
- Realtime: in memory sql db to run 'hot' queries
- FeatureExtraction:
- load etl from git .py file
- run queries and pull data from realtime / warehouse database.
- run feature extraction on pulled data
- save feature extraction (etl) to catalog
extract/realtime
app.extract_realtime
runs a query against training database
| Response |
Reason |
| 200 |
OK |
| 500 |
Failed |
| Name |
In |
Description |
Required? |
Type |
| query |
body |
the query to run |
true |
extract_rt |
| Produces |
| application/json; |
| Consumes |
| application/json |
extract/train
app.extract_train
runs a query against training database
| Response |
Reason |
| 200 |
OK |
| 500 |
Failed |
| Name |
In |
Description |
Required? |
Type |
| query |
body |
the query to run |
true |
extract |
| Produces |
| application/json; |
| Consumes |
| application/json |
creates flows and save to db, emulate user flow
| Response |
Reason |
| 200 |
OK |
| 500 |
Failed |
| Name |
In |
Description |
Required? |
Type |
| n_flows |
query |
number of flows |
true |
integer |
| Produces |
| application/json; |
runs a query against training database
updates database with hf
| Response |
Reason |
| 200 |
OK |
| 500 |
Failed |
| Name |
In |
Description |
Required? |
Type |
| query |
body |
the query to run |
true |
query_rt |
| Produces |
| application/json |
| Consumes |
| application/json |
runs a query against training database
updates database with hf
| Response |
Reason |
| 200 |
OK |
| 500 |
Failed |
| Name |
In |
Description |
Required? |
Type |
| query |
body |
the query to run |
true |
query |
| Produces |
| application/json; |
| Consumes |
| application/json |
extract Definition
| Property |
Type |
Format |
| query_id |
string |
|
| etl_path |
string |
|
extract_rt Definition
| Property |
Type |
Format |
| query_id |
string |
|
| etl_path |
string |
|
| index_key |
string |
|
| index_value |
string |
|
| Property |
Type |
Format |
| query |
string |
|
| query_name |
string |
|
| Property |
Type |
Format |
|
|
|
| query_id |
string |
|
| index_key |
string |
|
| index_value |
string |
|
