This project implements a Transformer-based image captioning model. We aim at training an image captioning network in a low-resource regime. We make use of the Flickr8k dataset consisting of 30,000 image-caption pairs. This is still a work in progress.
- An Overview of work
- Model comparison
- Results
- Project TODO
- Usage
- Optimizing Transformers for small datasets
- Self-Critical Sequence Training (SCST)
- Good Resources
We implement an image captioning model that uses a Transformer for both the encoder and decoder. The Transformer encoder will be used for self-attention on visual features, while the Transformer decoder will be used for masked self-attention on caption tokens and for vision-language attention.
On top of this, we will be incorporating the improvements introduced to Xu et al.'s Soft-Attention model, described in our previous work. Below is a short summary of the improvements:
- Representing the image at various levels of granularity to the decoder in terms of low-level and high-level regions, providing additional context to the decoder
- Introducing a pre-trained language model that suppresses semantically unlikely captions during beam-search
- Improve the vocabulary and expressiveness of the model by augmenting training captions with the aid of a paraphrase generator
We will be using our previous work's implementation as our base model, that is comprised of the Soft-Attention model along with all 3 improvements listed above. To measure the effectiveness of these improvements on a transformer-based model, we will be implementing the following model variations:
| Model | Description |
| Base Transformer | The encoder is fed image region embeddings consisting of high-level attention regions achieved through the feature maps of a pre-trained CNN in ResNet. |
| MLR - Multi-level regions Transformer | In addition to the high-level attention regions provided in the base transformer, we provide more fine-grained attention regions produced by either PanopticFCN or Faster R-CNN. |
| LM - Language Modelling rescoring Transformer | During beam-search, we will use GPT-2 to rescore the caption candidates. |
| CA - Caption augmentation Transformer | We make use of the T5 text-to-text model to augment training captions. |
| Model | B-1 | B-2 | B-3 | B-4 | MTR | CDR |
| Soft-Attention | 67 | 44.8 | 29.9 | 19.5 | 18.9 | - |
| Hard-Attention | 67 | 45.7 | 31.4 | 21.3 | 20.30 | - |
| gLSTM | 64.7 | 45.9 | 31.8 | 21.6 | 20.19 | - |
| F-G Attention | 69.4 | 48.2 | 33.7 | 23.8 | 22.62 | - |
| GLA | - | - | 23.9 | 14.8 | 16.9 | 41.9 |
| SDA-CFGHG | - | - | 33.4 | 22.1 | 20.5 | 45.9 |
| Base LSTM model | 68.6 | 48.5 | 34.7 | 24.5 | 23.2 | 49.2 |
| Base Transformer | 68.49 | 51.15 | 35.82 | 25.25 | 27.43 | 47.79 |
| MLR Transformer (Faster R-CNN) | 69.95 | 52.84 | 36.80 | 25.80 | 27.14 | 49.88 |
| MLR Transformer (PanopticFCN)* | 69.31 | 52.08 | 36.01 | 25.04 | 26.79 | 47.19 |
| LM rescoring Transformer | 69.02 | 51.74 | 36.07 | 25.57 | 26.81 | 49.10 |
| CA Transformer | 68.78 | 52.12 | 36.45 | 25.68 | 27.17 | 49.83 |
| Final Transformer | - | - | - | - | - | - |
Base LSTM model is an LSTM-based model (Soft-Attention) incorporating all 3 proposals. Models marked with * have not yet been hyperparameter tuned and are expected to improve. To the contrary of what research suggests for transformers trained on smaller datasets, we have 6 encoder layers and 3 decoder layers (opposite of what is suggested) and shows promising results.
While BLEU is the most common metric used within the field of machine translation, it has some drawbacks. Sulem et al (2018) recommend not using BLEU for text simplification. They found that BLEU scores don’t reflect either grammaticality or meaning preservation very well. Novikova et al. (2017) show that BLEU, as well as some other commonly-used metrics, don’t map well to human judgements in evaluating NLG (natural language generation) tasks. Therefor recent work has chosen to optimize on CIDEr-D scores and use BLEU as complimentary metric.
- Fix tokenizer (30/1/2022)
- Literature review of image captioning papers implementing transformers (1/2/2022)
- Base Transformer (2/2/2022)
- Optimize Transformer for smaller datasets (8/2/2022)
- Use custom vocab instead of Bert (recommended for limited datasets, able to limit vocab) (9/2/2022)
- MLR Transformer implementation (7/3/2022)
- Beam search implementation (20/2/2022) fixed at (1/3/2022)
- LM rescoring Transformer implementation (28/2/2022)
- CA Transformer implementation (16/2/2022)
- Self-Critical Sequence Training (SCST)
Clone repository:
$ git clone https://github.com/mikkkeldp/transformer-image-captioner
Install dependencies:
$ pip install -r requirements.txt
Download and extract Flickr8k Dataset from here and extract to dataset folder
We use the Bert Tokenizer to build a vocabulary over the captions within the training captions.
$ python3 build_vocab.py
Tweak the hyperparameters in configuration.py.
To train on a single GPU, run:
$ python3 main.py
To train from a checkpoint, run
$ python3 main.py --checkpoint /path/to/checkpoint/
We train our model with AdamW setting learning rate in the transformer to 1e-4 and 1e-5 in for ResNet.
To test the model using a checkpoint, run:
$ python3 test.py --checkpoint /path/to/checkpoint/
It is known that transformers struggle to learn under a low-resource regime. However, there are some works that managed to achieve success under these circumstances. These works focus on the task of machine translation (Seq2Seq), but hopefully carry over to the task of image captioning. Here are the findings of some of these papers:
Limit the amount of trainable parameters. They found that Transformers under low-resource conditions is highly dependent on the hyper-parameter settings. Deep transformers requires large amounts of training data. Reducing the depth and width, including the number of attention heads, feed-forward dimension, and number of layers along with increasing the rate of different regularization techniques is highly effective (+6 BLEU). The largest improvements are obtained by increasing the dropout rate (+1.4 BLEU), adding layer dropout to the decoder (+1.6 BLEU), and adding word dropout to the target side (+0.8 BLEU).
| Optimal hyper-parameters | default | 5k | 10k | 20k | 40k | 80k |
|---|---|---|---|---|---|---|
| BPE operations | 37k | 5k | 10k | 10k | 12k | 15k |
| feed-forward dim | 2048 | 512 | 1024 | 1024 | 2048 | 2048 |
| att heads | 8 | 2 | 2 | 2 | 2 | 2 |
| dropout | 0.1 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 |
| layers | 6 | 5 | 5 | 5 | 5 | 5 |
| label smoothing | 0.1 | 0.6 | 0.5 | 0.5 | 0.5 | 0.4 |
| enc/dec layerdrop | 0.0/0.0 | 0.0/0.3 | 0.0/0.2 | 0.0/0.2 | 0.0/0.1 | 0.0/0.1 |
| src/tgt word dropout | 0.0/0.0 | 0.0/0.1 | 0.0/0.1 | 0.1/0.1 | 0.1/0.1 | 0.2/0.2 |
| act dropout | 0.0 | 0.3 | 0.3 | 0.3 | 0.3 | 0 |
| batch size | 4096 | 4096 | 4096 | 4096 | 4096 | 8192 |
They found that using large models is detrimental for low-resource language translation, since it makes training more difficult and hurts overall performance. It was found that depth of 6 layers was optimal, opposed to a deep Transformer consisting of 12 layers. They also found that finfing stable learning rates can be very computationally expensive.
This work introduced a novel neural architecture Transformer-XL that was able to perform sequence-to-sequence translation with great success. A key insight was discovered after the code had been released, was that in a small dataset regime, data augmentation is crucial. This in turn regularizes the model. The most dramatic performance gain comes from discrete embedding dropout. That is, you embed as usual, but with a probability p you zero the entire word vector. This is akin to masked language modelling but with the goal not to predict the mask - just regular LM with uncertain context. Another important factor is regular input dropout. This is, dropping elements of the embeddings with probability p. This is the same as dropping out random pixels from images. The drawback to all these regularization techniques is much longer training times.
Below are the most common transformer hyper-parameters used for image captioning (as found on public github repos). These are mostly tuned for MSCOCO, but give an indicator of adjustments made for the task of image captioning, opposed default parameters for seq2seq tasks.
| Parameter | default | recommended |
|---|---|---|
| lr | 0.00005 | 0.0003 |
| lr-scheduler | StepLR (10 epoch steps) | inverse_sqrt (8000 iteration steps) |
| criterion | CE | label smoother CE |
| encoder layers | 6 | 3 |
| decoder layers | 6 | 6 |
| dropout | 0.1 | 0.3 |
| encoder_embed_dim | 128 | 512 |
| Model | description | B1 | B2 | B3 | B4 | MTR | CDR | # epochs |
|---|---|---|---|---|---|---|---|---|
| Default | Base model with default transformer hyper-params. Standard image transforms of resize, normalization. | 64.96 | 46.29 | 32.60 | 22.78 | 23.44 | 45.98 | 7 |
| Image transforms | Base model with default transformer hyper-params. Image transforms: color jitter, random horizontal flip, random rotation. | 63.63 | 45.34 | 31.80 | 22.27 | 23.21 | 47.86 | 12 |
| Partial optimal suggested hyper-params with image transforms. | enc/dec layers = 5, feedforw dim = 1024, heads =2. dropout=0.3(other regularization techniques to be added) | 64.57 | 46.30 | 32.98 | 23.29 | 23.09 | 46.45 | 14 |
| Smaller max_position_embedding | max_position_embeddings = 64, image transformers, batch_size = 10, default settings otherwise | 64.55 | 45.92 | 32.31 | 22.75 | 22.84 | 43.03 | 8 |
| Common IC transformer params, but adjusted for smaller datasets | enc_layers = 3, dropout = 0.2, default image transforms, lr=0.0003, lr_step at epoch 8 | 65.29 | 46.54 | 32.99 | 23.39 | 23.26 | 45.62 | 8 |
From observing the results achieved through implementing regularization techniques only increases the training time (more epochs) without noticeably increasing the accuracies.
| Model | B1 | B2 | B3 | B4 | MTR | CDR |
|---|---|---|---|---|---|---|
| Base Transformer beam width 1 | 68.49 | 51.53 | 35.58 | 25.25 | 27.43 | 47.79 |
| Base Transformer beam width 3 | 65.69 | 48.49 | 32.91 | 22.7 | 26.57 | 42.65 |
| Base Transformer beam width 5 | 63.71 | 46.23 | 30.90 | 21.08 | 25.97 | 39.87 |
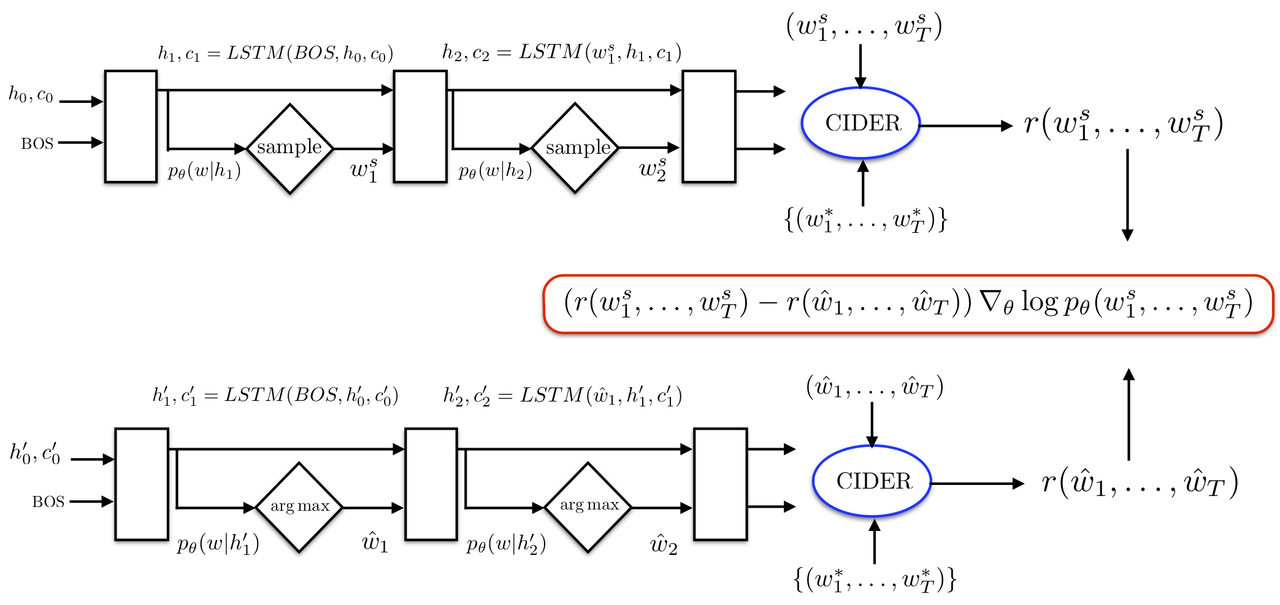
Deep learning models for sequence generation are traditionally trained using supervised learning methods, in which a cross entropy loss is calculated for each output token and average across the entire generated sequence. Such models are often sequence-to-sequence recurrent models, where the model maintains an internal state ht during the generation of a sequence and outputs a single token wt corresponding to an input token at each time step t.
During training time, a method called "Teacher-Forcing" is often used, where the model is trained with cross entropy to maximize the probability of outputting a token wt conditioned on the pervious ground truth token wt-1 (in addition to its internal state ht). Through using cross entropy loss during training, the network is fully differentiable, and thus backpropagation can be used. This, however, creates a schism between training and testting time, as the model's test-time interference algorithm does not have access to the previous ground truth token wt-1 and therefore typically feeds in the previous predicted token ŵt-1. This may lead to cascasing errors during inference and is known as exposure bias.
The use of policy gradient methods from reinforcement learning is a relatively new development in the training of sequence generation models. This class of algorithms allow for non-differentiable metrics to be directly optimized and perform the exposure bias to be reduced. In the case of image captioning, you can directly optimize the model to maximize a evaluation model. The most commonly optimized metric is CIDEr, as it's known to lift the performance of all other metrics considerably.
Recently, reinforcement learning methods such as SCST have emerged to mitigate the weaknesses with policy gradient methods. SCST uses the reward obtained from the model's own test-time inference algorithm as the baseline and combines it with the technique known as REINFORCE. The cost of SCST is only one additional forward pass, therefor only requiring 1.33x cost versus traditional backpropagation methods.