This is a project for CUNY SPS 607 - Data Acquisition and Management. This project was completed by
- Elizabeth Drikman
- Michael Yampol
- Michael Silva
- Corey Arnouts
Our motivation for this study is to gain an understanding of which skills are the most useful for a data scientist to have so that we can plan what courses to take in our Master's program.
To answer this question we will scrape data scientist job listings on dice.com and extract the skills listed on the postings.
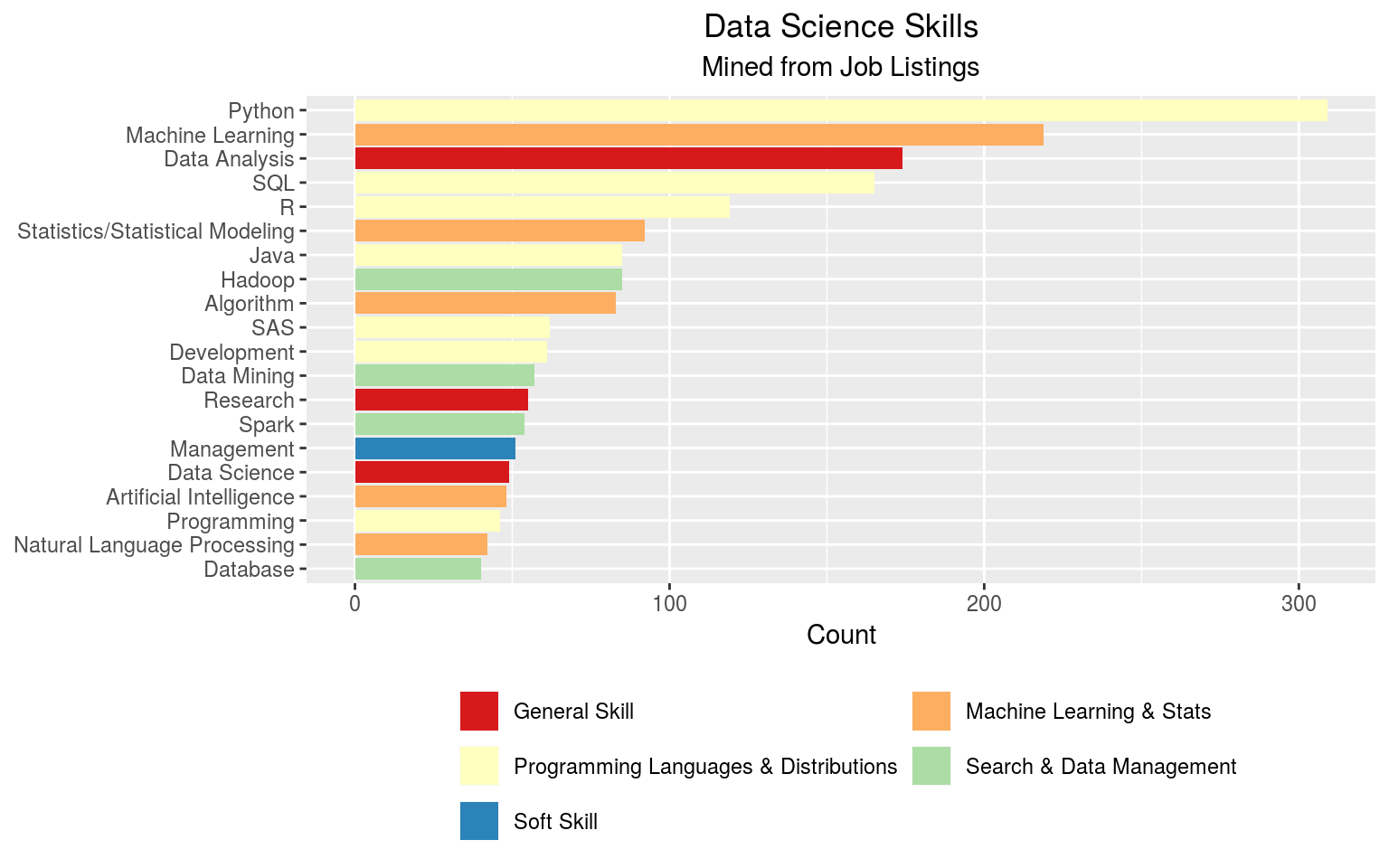
The following figure shows the top 20 skills of a data scientist:
This wordcloud summarizing all the top skills listed on the job postings:

Full findings are found in https://rpubs.com/mikesilva/skills-of-a-data-scientist.
This study uses both R and Python 3. In order to replicate it you will need the following installed:
- R
- DBI
- RMySQL
- dplyr
- tidyr
- stringr
- splitstackshape
- Hmisc
- wordcloud
- ggplot2
- rmdformats
- Python 3
- requests
- sqlalchemy
- pymysql
- beautifulsoup4
- selenium
- pandas
You will need the Chrome selenium driver installed on your local machine.
You will need to edit Credentials.R with your MySQL credentials.
You will first need to run the Setup.R script. This will set up your local MySQL database. It will then launch a selenium controlled Chrome browser which will search for dice.com using "Data Scientist" as the keyword (in quotes).
The next step is to run the Dice Scraper script which will scrape all the URLs previously stored in the MySQL database. Note: You may need to run this more than once.
Next run the Skills Miner script which will create locations.csv, skills_counts.csv and skills_list.csv.
The next step is to clean up and standardize the skills list. Project_3_V2.R was an attempt to clean up the skills programatically but human interpretation was needed. Running Project_3_V2.R which will clean up the skills_counts.csv and create data_science.csv.
The final step is to run the presentation.Rmd which will create the visualizations.