AI for Snake game trained from pixels using Deep Reinforcement Learning (DQN).


We implemented a sarsa method, 4 dqn extensions and the combined dqn version based on the previous basic dpn engine which was implemented by Yuriyguts (2017) [4]. We also compared to the results metioned in paper "Rainbow: Combining Improvements in Deep Reinforcement Learning" by DeepMind.
- Sarsa
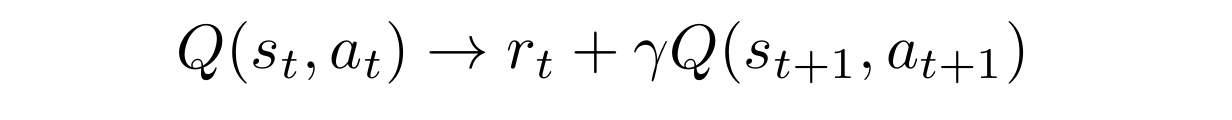
- Double Q function
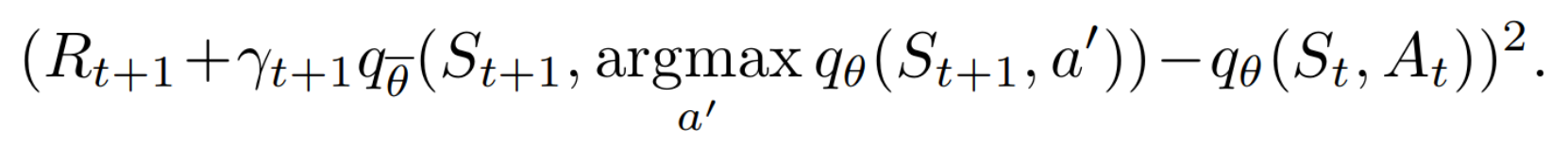
- Multi-step rewards
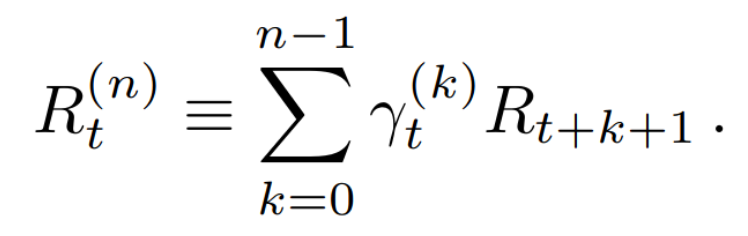
- Prioritized replay
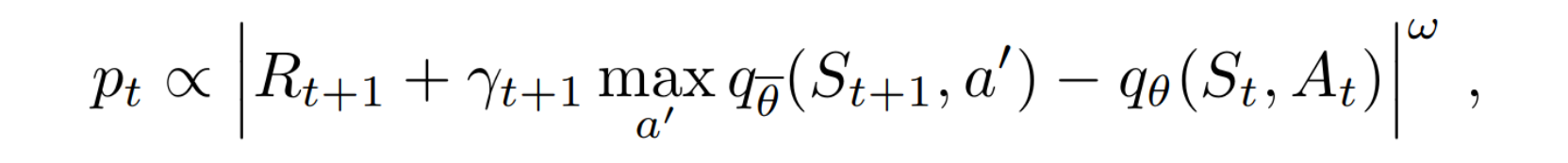
- Dueling networks
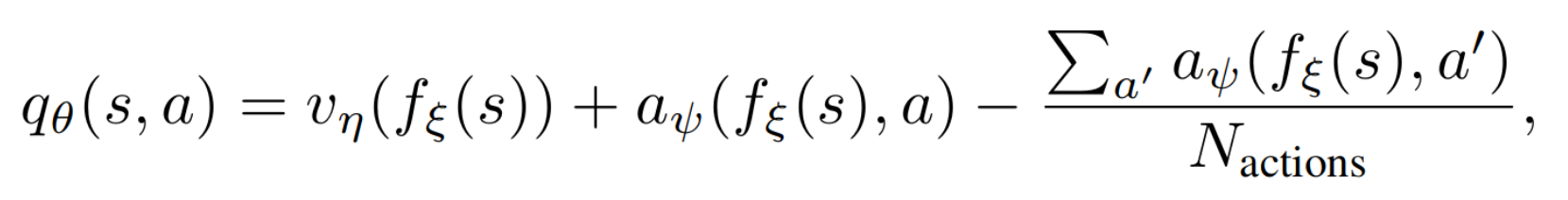
- Hybrid Method
All components have been written in Python 3.6. Training on GPU is supported but disabled by default. If you have CUDA and would like to use a GPU, use the GPU version of TensorFlow by changing tensorflow to tensorflow-gpu in the requirements file.
To install all Python dependencies, run:
$ make deps
You can find a few pre-trained DQN agents on the Releases page. Pass the model file to the play.py front-end script (see play.py -h for help).
-
dqn-10x10-blank.modelAn agent pre-trained on a blank 10x10 level (
snakeai/levels/10x10-blank.json). -
dqn-10x10-obstacles.modelAn agent pre-trained on a 10x10 level with obstacles (
snakeai/levels/10x10-obstacles.json).
To train an agent using the default configuration, run:
$ make train
The trained model will be checkpointed during the training and saved as dqn-final.model afterwards.
Run train.py with custom arguments to change the level or the duration of the training (see train.py -h for help).
The behavior of the agent can be tested either in batch CLI mode where the agent plays a set of episodes and outputs summary statistics, or in GUI mode where you can see each individual step and action.
To test the agent in batch CLI mode, run the following command and check the generated .csv file:
$ make play
To use the GUI mode, run:
$ make play-gui
To play on your own using the arrow keys (I know you want to), run:
$ make play-human
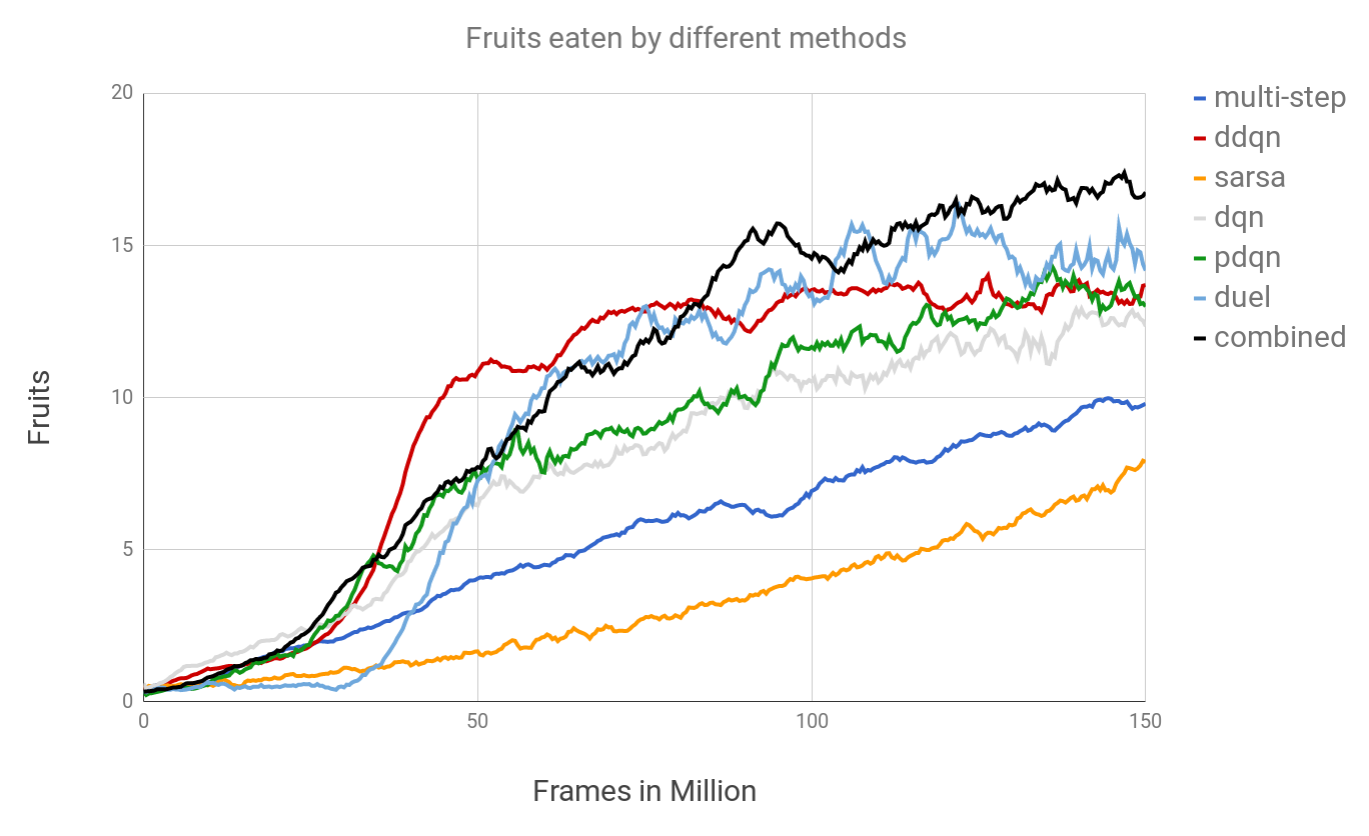
Similar to the find out in the Deepmind paper[2], we find out most methods improve the learning ability on Deep Reinforcement Learning (DQN).
The multi-step stepsize extension may suffer from future rewards which slower the network learning progress. The combined method (combined with extension Double Q function, Multi-step rewards, Prioritized replay, Dueling networks) outperforms the basic dpn and achieves the best performance among all methods.
It is worth mentioning that we highly recommend using Dueling networks architecture. It improves the performance a lot while comparing the basic dpn only slight changes need to be modified in the output layers.
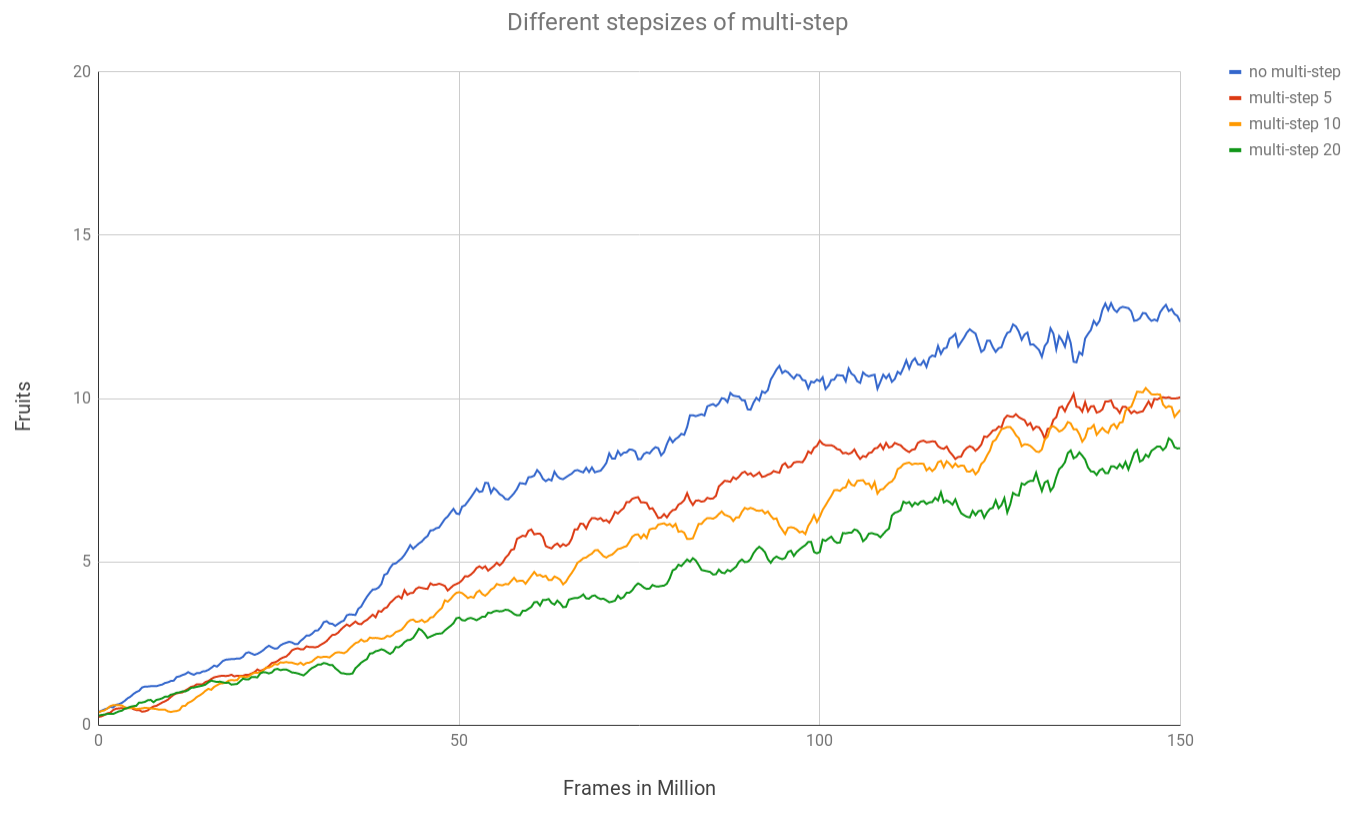
The performance decreases as the stepsize gets bigger. This maybe due to larger multi-step stepsize could hinder the learning ability of the neural network. With large step size, the neural network is forced to consider future rewards which might slower the learning progress.
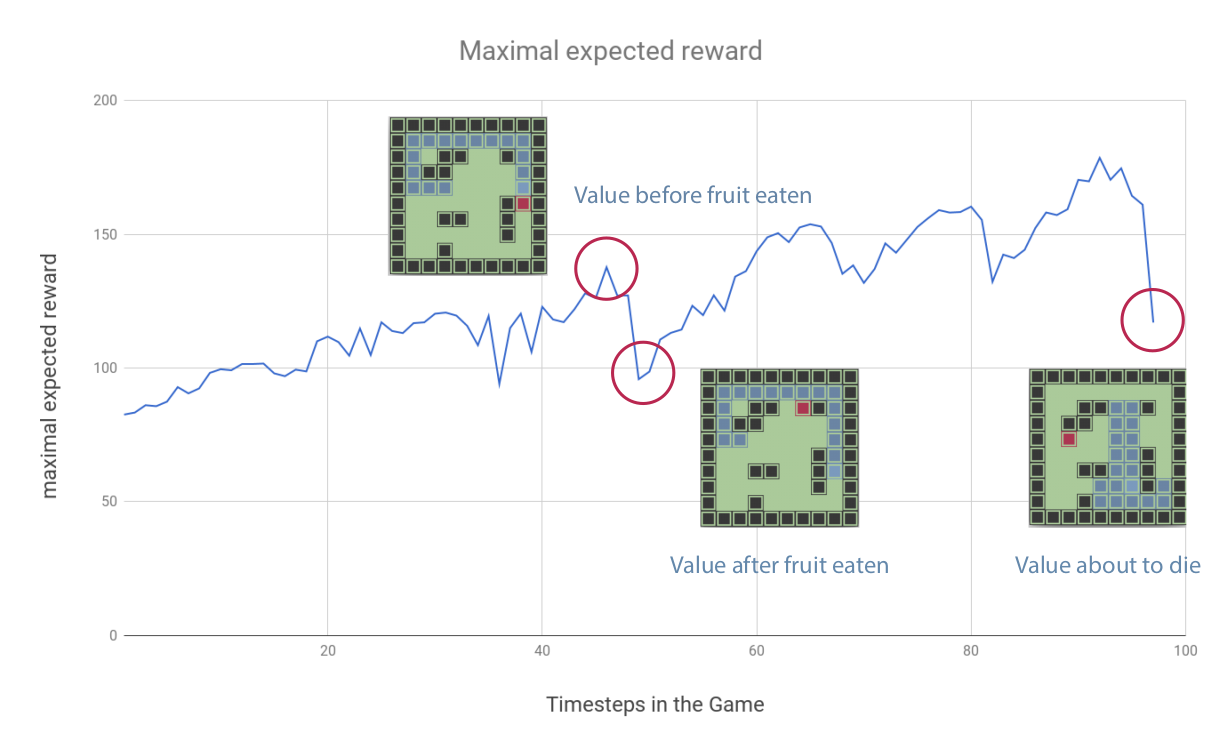
The graph shows how the expected maximal reward increases or decreases during one game. Note that every time the expected maximal reward goes down, it means that the snake ate a fruit at the last step. Because the fruit is further away at the next step the expected reward goes down.
- The combination of DDQN, dueling networks, prioritized replay and multi-step performed the best.
- The performance SARSA and multi-step was worse than original DQN.
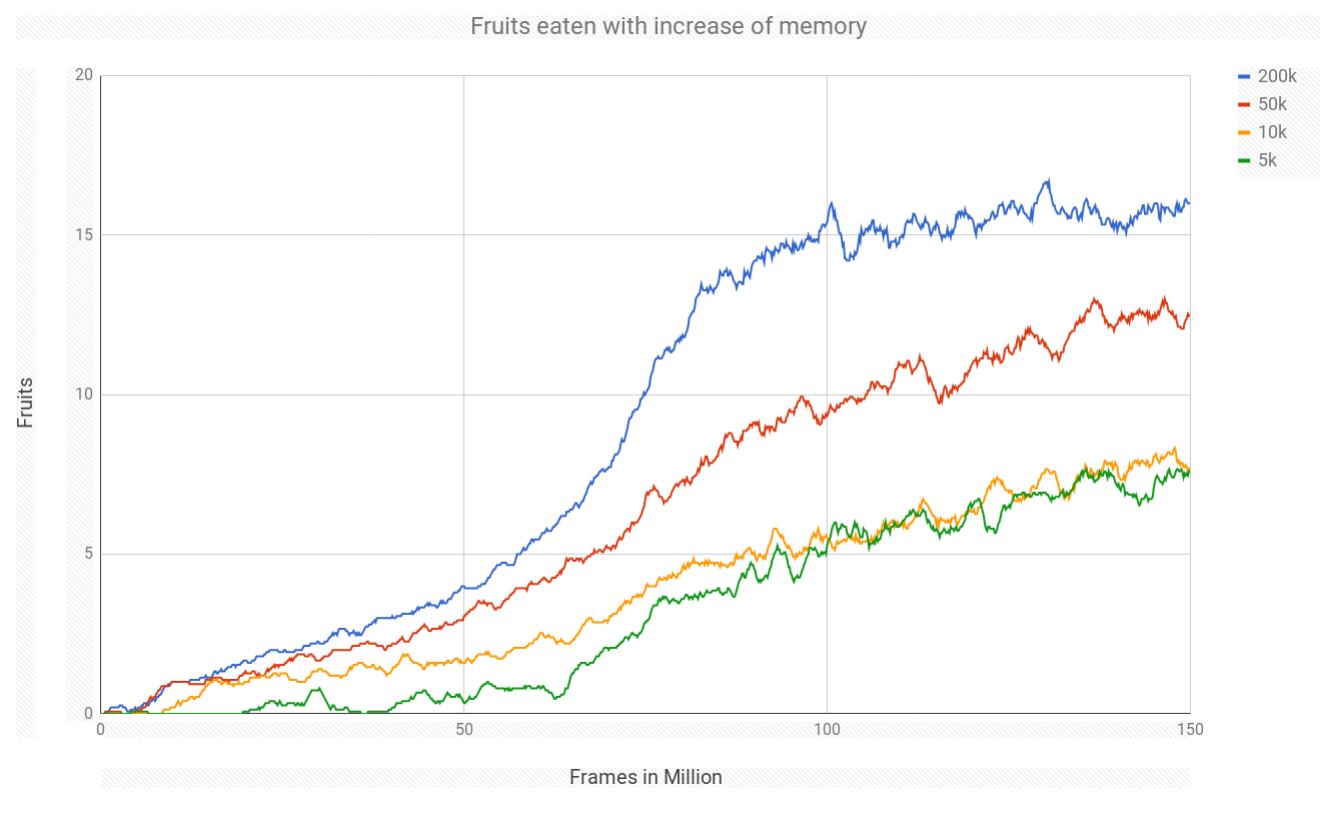
- The more memory we used for Experience Replay the better the performance.
- The performance decreases as the stepsize gets bigger.

[1] Fuertes, R. A (2017). Machine Learning Agents: Making Video Games Smarter With AI. Retrieved January 15, 2018 from https://edgylabs.com/machine-learning-agents-making-video- games-smarter-with-ai
[2] Hessel, M., Modayil, J. & Hasselt, H. V. (2017). Rainbow: Combining Improvements in Deep Reinforcement Learning. Retrieved January 10, 2018 from https://arxiv.org/pdf/1710.02298.pdf
[3] Mnih, V., Kavukcuoglu, K. & Silver, D. (2013). 1312.5602v1.pdf. Retrieved January 10, 2018 from https://arxiv.org/pdf/1312.5602v1.pdf
[4] Yuriyguts (2017). GitHub - YuriyGuts/snake-ai-reinforcement: AI for Snake game trained from pixels using Deep Reinforcement Learning (DQN) . Retrieved January15, 2018 from https://github.com/YuriyGuts/snake-ai-reinforcement