For this project, you will work with the Reacher environment.

In this environment, a double-jointed arm can move to target locations. A reward of +0.1 is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector should be a number between -1 and 1.
The task is episodic, and in order to solve the environment, your agent must get an average score of +30 over 100 consecutive episodes.
Follow the instructions in Continuous_Control.ipynb to get started with training your own agent!
- Download the Unity environment:
bash download_env.sh - The python environment used in this project is similar to ones used in my Project I, with
torch==2.0.0andgrpcio==1.53.0 - There will be 2 options to start this notebook on your local machine.
- Start locally: Run
python3 -m pip install .in the terminal - Use with docker: Run
make all RUN=1
- Re-run every cells in
Continuous_Control_solution.ipynb
Below is my solution for Option 1 task
I began with a baseline of the original DDPG used in the ddpg-pendulum example, with state being a (33,1) vector and action being a (4,1) vector.
- However, there was no significant increase in the average score
 .
. - The chart below show the average scores after 1000 episodes.
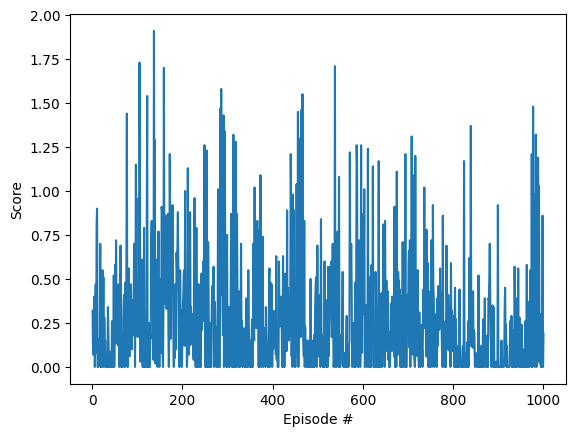 .
.


I modified the neural architectures of Actor and Critic, referenced from Anh-BK works [1], so that it would be easier to tune the number of hidden layers:
- After training for only 498 episodes, my agent has achieved an average score of
30.12 - Here is the plot of the scores achieved after each episode.
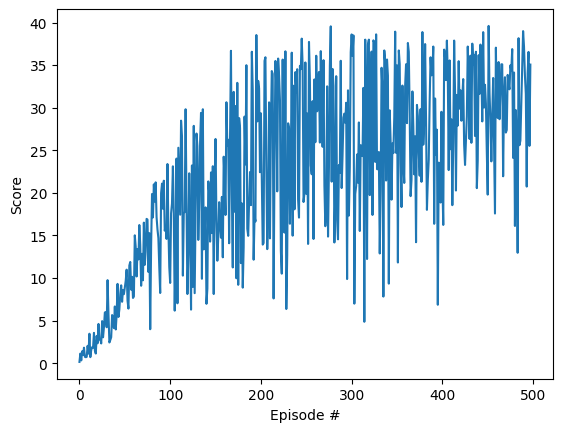
- The checkpoint of the actor is saved in
checkpoint_actor.pth - The checkpoint of the critic is saved in
checkpoint_critic.pth

- Integrate wandb into training pipeline to have better visualization with different hyper-parameters (epsion, hidden units in the Q-nets).
- Try experiments with TD3 method [2]. I have included a placeholder to train a TD3 agent. TD3 is considered to be more effective than DDPG since it does not rely heavily on hyper-parameter tuning. I have adapted a version of the original TD3 in
agent/TD3.py
[2] Original TD3