Implementation of alphazero learning algorithm for 6-6-4 Tictactoe
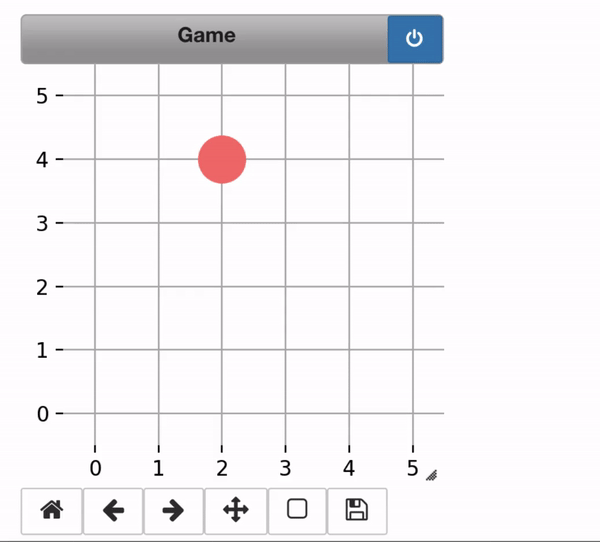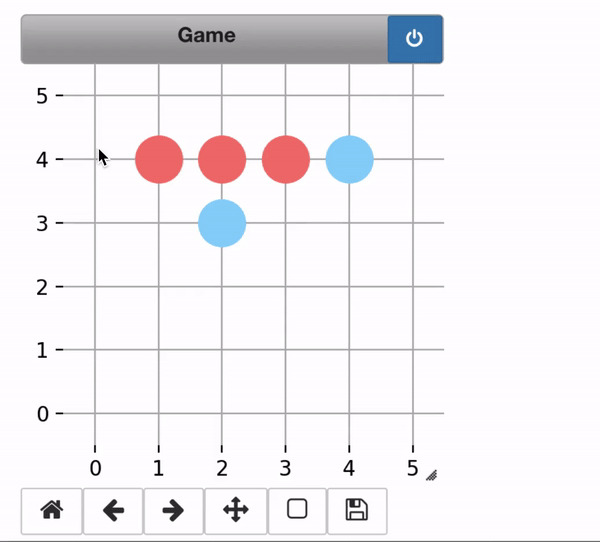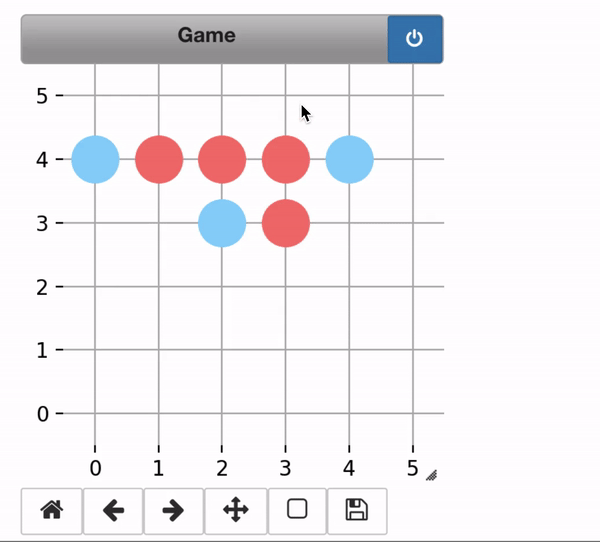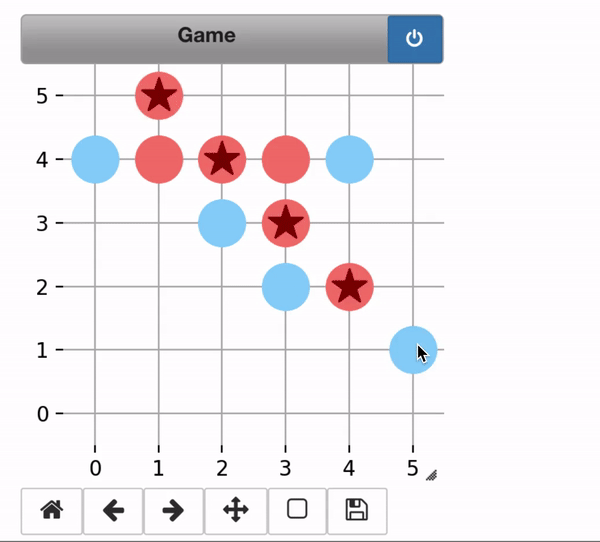
The trained alphazero agent easily defeated me!
- Player1 (Red) : Alphazero
- Player2 (Blue) : Me
alphazero_tictactoe.ipynb: Jupyter notebook for training alphazero for normal 3x3x3 tictactoealphazero_tictactoe_advanced.ipynb: Jupyter notebook for training alphazero for complex 6x6x4 tictactoeMCTS.py: Helper file for Monte Carlo Tree SearchPlay.py: File for helping with interactive game playConnectN.py: File defining the game structure6-6-4-pie.policy: Trained policy weights for 6x6x4 tictactoe
- Follow the step by step instructions in
alphazero_tictactoe_advanced.ipynbto train your own alphazero agent!