
| 🏠 Project Page | 📄 Paper | 🔥 Demo

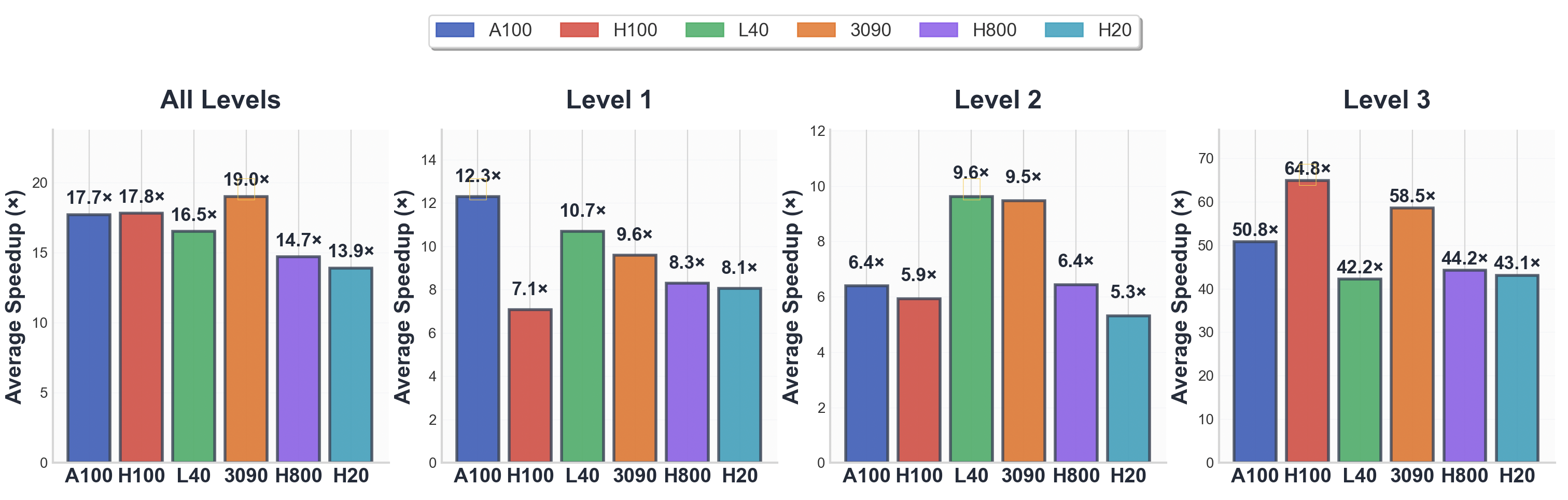
In this paper, we introduce CUDA-L1, an automated reinforcement learning (RL) framework for CUDA optimization. The core of CUDA-L1 is a contrastive RL model, a newly-designed RL system to enhance optimization through comparative learning. CUDA-L1 achieves unprecedented performance improvements on the CUDA optimization task: trained on NVIDIA A100, it delivers an average speedup of ×17.7 across all 250 CUDA kernels of KernelBench, with peak speedups reaching ×449. Furthermore, the model also demonstrates excellent portability across GPU architectures, achieving average speedups of ×17.8 on H100, ×19.0 on RTX 3090, ×16.5 on L40, ×14.7 on H800, and ×13.9 on H20 despite being optimized specifically for A100. Beyond these benchmark results, CUDA-L1 demonstrates several remarkable properties:
- It discovers a variety of CUDA optimization techniques and learns to combine them strategically to achieve optimal performance;
- It uncovers fundamental principles of CUDA optimization, such as the multiplicative nature of optimizations and how certain "gatekeeper" techniques must be applied first to unlock the effectiveness of others;
- It identifies non-obvious performance bottlenecks (such as CPU-GPU synchronization dominating compute optimizations) and rejects seemingly beneficial optimizations that actually harm performance.
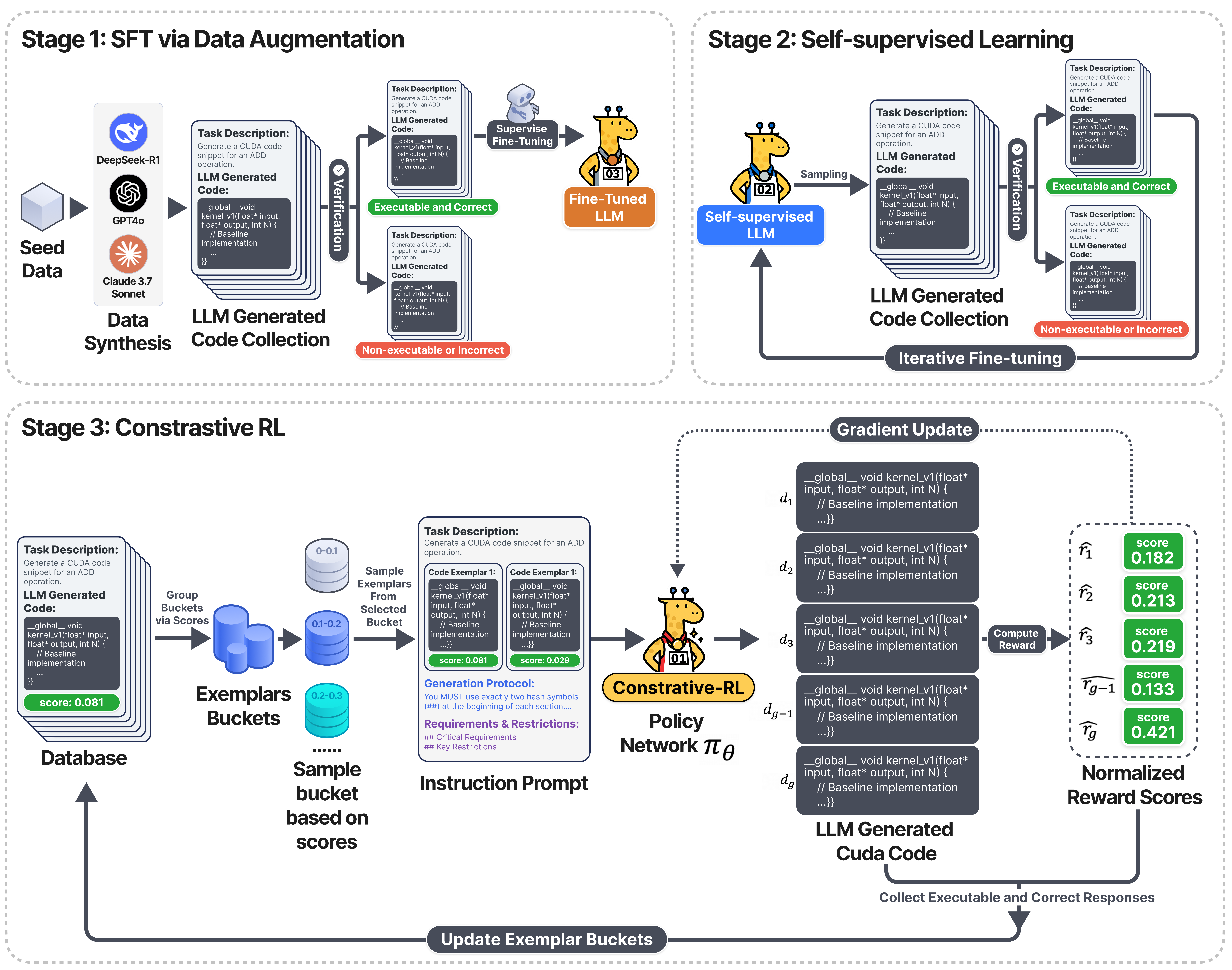
We augment the training dataset with CUDA code variants generated by LLMs and fine-tune the base model on executable and correct implementations to establish foundational CUDA knowledge.
The model iteratively generates CUDA kernels, validates their correctness and executability, and trains on successfully validated examples, enabling autonomous improvement without human supervision.
We employ contrastive learning with execution-time rewards, training the model to distinguish between faster and slower CUDA implementations, ultimately optimizing for superior performance.
| Method | Mean | Max | 75% | 50% | 25% | Success # out of total |
Speedup # out of total |
|---|---|---|---|---|---|---|---|
| All Levels | 17.7× | 449× | 7.08× | 1.81× | 1.22× | 249/250 | 242/250 |
| Level 1 | 12.3× | 166× | 9.28× | 1.65× | 1.15× | 99/100 | 96/100 |
| Level 2 | 6.39× | 111× | 4.42× | 1.61× | 1.24× | 100/100 | 97/100 |
| Level 3 | 50.8× | 449× | 22.9× | 2.66× | 1.58× | 50/50 | 49/50 |
| GPU Device | Mean | Max | 75% | 50% | 25% | Success Rate |
|---|---|---|---|---|---|---|
| A100 PCIe | 17.7× | 449× | 7.08× | 1.81× | 1.22× | 99.6% |
| H100 XSM | 17.8× | 1,001× | 4.02× | 1.63× | 1.16× | 98.4% |
| RTX 3090 | 19.0× | 611× | 4.41× | 1.44× | 1.11× | 98.4% |
| L40 | 16.5× | 365× | 6.17× | 1.61× | 1.15× | 98.8% |
| H800 XSM | 14.7× | 433× | 4.80× | 1.57× | 1.16× | 99.6% |
| H20 | 13.9× | 412× | 4.76× | 1.54× | 1.16× | 99.2% |
• Level 3 tasks (complex ML operations) show the highest speedups, making CUDA-L1 especially valuable for real-world applications
We also compare baseline methods (backboned by Deepseek-R1, OpenAI O1) with CUDA-L1 on KernelBench.
We provide CUDA code snippets optimized by CUDA-L1 in the optimized_cuda_code folder, with separate versions for each GPU device. For example, to reproduce our results on H100 XSM, download ./optimized_cuda_code/h100_xsm.json and run each code snippet on your H100 device.
@article{deepreinforce2025cudal1,
title={CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning},
author={Li, Xiaoya and Sun, Xiaofei and Wang, Albert and Li, Jiwei and Chris, Shum},
journal={arXiv preprint arXiv:2507.14111},
year={2025}
}If you have any questions, please reach out to us at research@deep-reinforce.com.