Project Overview
Apache Cassandra project in the Data Engineering Udacity Nanodegree.
Introduction
At Sparkify, our app allows the user to stream music. We want to analyze the data on songs and user activity on their new music streaming app. In particular, we want to understand what songs users are listening to. This repository allows to create an Apache Cassandra database with tables designed to optimize queries on song play analyses.
Dataset
Data reside in a the directory event_data. It contains CSV files partitioned by date. Here are examples of filepaths to two files in the dataset
event_data/2018-11-08-events.csv
event_data/2018-11-09-events.csv
Files
In addition to the data files, there are the following files:
Project_1B_ Project_Template.ipynb, a jupyter notebook creating the tables and testing them with queries. It is described later in more detailevent_datafile_new.csvthe .CSV file created by theProject_1B_ Project_Template.ipynband collecting the data from theevent_datafolderREADME.mdthis readmeimagesfolder, contaning the images for the readme and for the jupyter notebook.
ETL Pipeline and DB
The file Project_1B_ Project_Template.ipynb includes
- the preprocessing of the files
- the creation of the DB
- queries for testing the DB
Preprocessing
The ETL pipeline for preprocessing the files iterates over the file in the event_data folder and writes them into a .CSV table. Each row in the table contains the following information
- artist
- firstName of user
- gender of user
- item number in session
- last name of user
- length of the song
- level (paid or free song)
- location of the user
- sessionId
- song title
- userId
The image below is a screenshot of what the denormalized data look like in the event_datafile_new.csv after preprocessing.
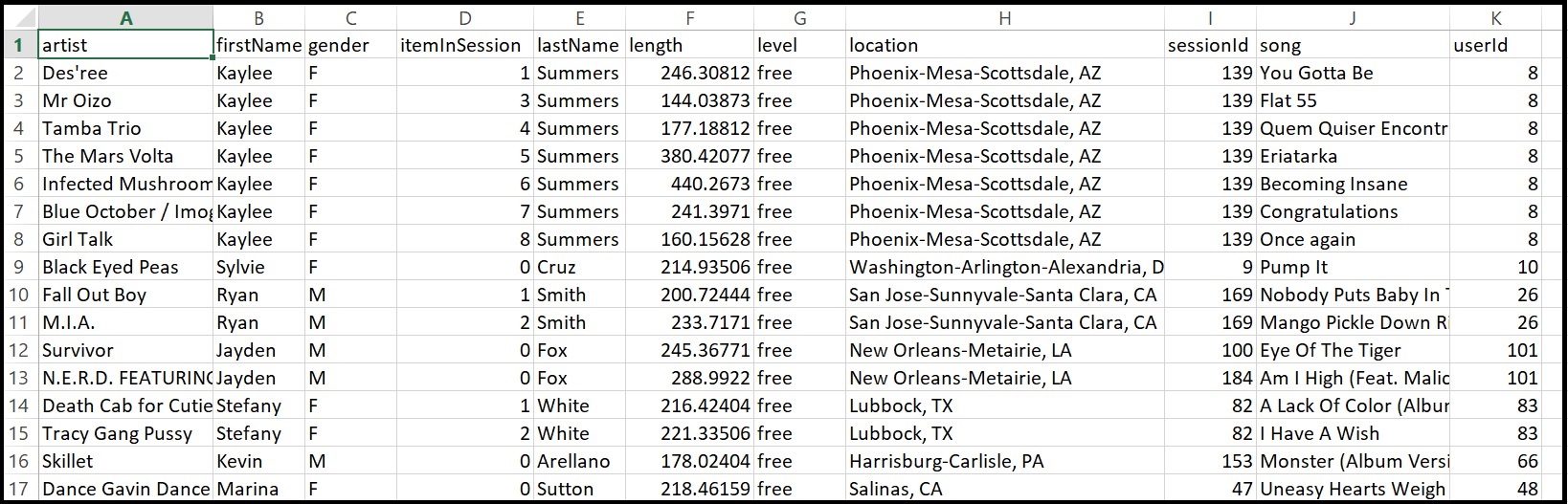

We create a dictionary dct in order to simplify the process of filling in the tables, later on. We do not have to remember the ordering of the CSV file to access each information, but can access it via its name.
DB creation
Three tables are created, each optimised for a query of the following type.
Query 1
Give me the artist, song title and song's length in the music app history that was heard during sessionId = 338, and itemInSession = 4
For this query we create the table session_library with Apache Cassandra statements CREATE. The DB consists of the following columns
sessionIdof typeintitemInSessionof typeintsongof typetextartistof typetextlengthof typefloatSince the queries focus on specificsessionIdanditemInSession, these are chosen as PRIMARY KEY.
The table is filled in by iterating over the rows of the .CSV file, accessing the column required by using the dictionary dct and, when needed, converting the data to the required type. Then running the Apache Cassandra statements INSERT.
After creating the DB, we can check that everything worked by performing the query
SELECT artist, song, firstname, lastname FROM session_library
WHERE sessionId=338 AND itemInSession = 4
This should return
| song | artist | length |
|---|---|---|
| Faithless | Music Matters (Mark Knight Dub) | 495.30731201171875 |
- Give me only the following: name of artist, song (sorted by itemInSession) and user (first and last name) for userid = 10, sessionid = 182
For this query we create the table
user_librarywith Apache Cassandra statementsCREATE. The DB consists of the following columns
userIdof typeintsessionIdof typeintitemInSessionof typeintsongof typetextartistof typetextfirstNameof typetextlastNameof typetextSince the queries focus on specific(userId,sessionId), these are chosen as partition key. Since results must be sorted byitemInSession, this is chosen as clustering key.
The table is filled in by iterating over the rows of the .CSV file, accessing the column required by using the dictionary dct and, when needed, converting the data to the required type. Then running the Apache Cassandra statements INSERT.
After creating the DB, we can check that everything worked by performing the query
SELECT artist, song, firstname, lastname,iteminsession FROM user_library \
WHERE userId=10 AND sessionId = 182
This should return
| Artist | song | firstName | lastName |
|---|---|---|---|
| Down To The Bone | Keep On Keepin' On | Sylvie | Cruz |
| Three Drives | Greece 2000 | Sylvie | Cruz |
| Sebastien Tellier | Kilometer | Sylvie | Cruz |
| Lonnie Gordon | Catch You Baby (Steve Pitron & Max Sanna Radio Edit) | Sylvie | Cruz |
- Give me every user name (first and last) in my music app history who listened to the song 'All Hands Against His Own'
For this query we create the table
song_librarywith Apache Cassandra statementsCREATE. The DB consists of the following columns
songof typetextfirstNameof typetextlastNameof typetextuserIdof typeintThe entryuserIdis added to render the PRIMARY KEY unique for each entry. Since the queries focus on specificsong, this is chosen as partition key. To render the PRIMARY KEY unique,userIdis added as clustering key.
The table is filled in by iterating over the rows of the .CSV file, accessing the column required by using the dictionary dct and, when needed, converting the data to the required type. Then running the Apache Cassandra statements INSERT.
After creating the DB, we can check that everything worked by performing the query
SELECT firstname, lastname FROM song_library \
WHERE song='All Hands Against His Own'
This should return
| firstName | lastName |
|---|---|
| Jacqueline | Lynch |
| Tegan | Levine |
| Sara | Johnson |