🏪 Official stores
Chrome & Brave
•
Firefox
An automated, web-based and minimalist reference manager.
It is not meant to replace, rather complete more standard reference managers as Zotero etc.
This browser extension allows you to do automatically store research papers you read and much more:
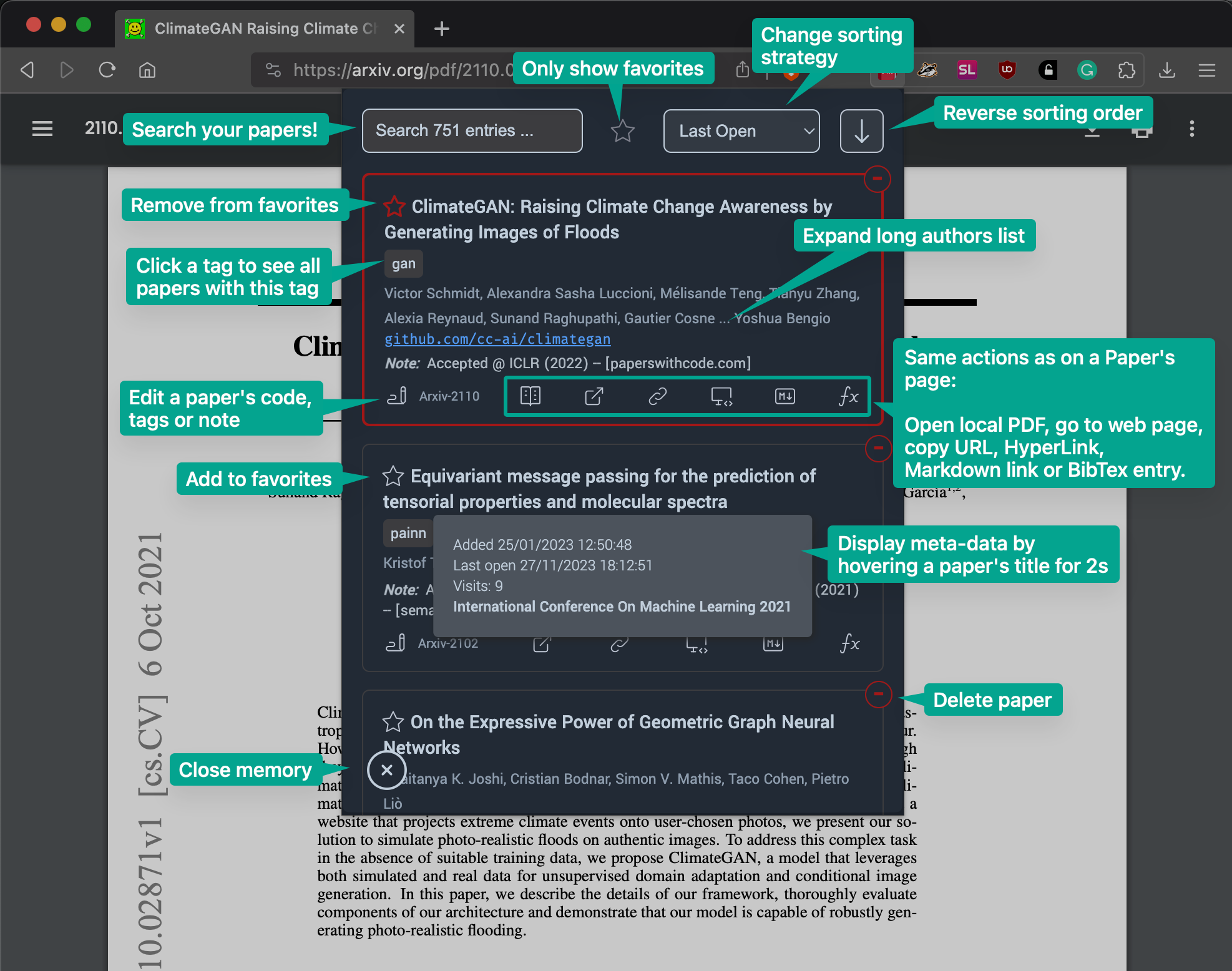
- 🏬 Automatically record papers you open, without clicking anywhere. You can then search them, tag them, comment them and link a code repository.
- 🎬 Change a pdf's webpage title to the article's title, because who cares about that saved bookmark
1812.10889.pdfwhen it could beInstaGAN Instance-aware Image-to-Image Translation.pdf - 🎫 BibTex citation, because citing papers should not be a hassle you can copy a BibTex citation to your clipboard or export the Memory itself as a
.bibfile - 🔗 Markdown link,
[title](url)because it's the little things that make sharing a paper easier (to be used in issues, PRs, Readme, HackMD.io etc.) - 🗂 Direct download button with a nice name including the paper's title, so that you don't have to open the pdf's webpage and then download it from your browser.
- 📄 Go back from a pdf to its abstract page. For instance: from
https://arxiv.org/pdf/1703.06907.pdftohttps://arxiv.org/abs/1703.06907in a click. - 🏛️ Export your data as a
.jsonfile or a.bibfull BibTex export
- Arxiv (PaperMemory will try to find if a pre-print has been published and create a corresponding
noteto the paper (see preprints)) - BioRxiv
- NeurIPS
- Open Review (ICLR etc.)
- Computer Vision Foundation (I/ECCV, CVPR etc.)
- Proceedings of Machine Learning Research (PMLR) (AISTATS, ICML, CoRL, CoLT, ALT, UAI etc.)
- Association for Computational Linguistics (ACL) (EMNLP, ACL, CoNLL, NAACL etc.)
- Proceedings of the National Academy of Sciences (PNAS)
- SciRate
- Add more
About finding published papers from preprints
All the data collected is stored locally on your computer and you can export it to json it from the menu.
I'm regularly adding feature ideas in the issues. Feel free to go upvote the ones you'd like to see happen or submit your own requests.

Customize features in the menu:

Switch between Light and Dark mode

Share ideas 💡 in issues and love with stars ⭐️:)
- Keyboard navigation:
- Open the popup:
cmd/ctrl + shift + e
- Open the Memory
afrom the popup's home will open it- navigate to the bottom left button with
taband hitenter
- Search
- Search field is automatically focused on memory open
- Navigate to the top input with
taborshift + tab
- Navigate papers
tabwill iterate through papers down the listshift + tabwill go back up the list
- Edit a paper
- Press
eto edit the paper's metadata: tags, code and note when the paper is focused (from click or keyboardtabnavigation)- Navigate through fields with
(shift+) tab: tags and note if you're on a paper's page.
- Navigate through fields with
- Press
enterto open a focused paper (focus an existing tab with the paper or create a new tab to the paper's pdf if it's not open already) backspaceto delete a focused paper (a confirmation will be prompted first don't worry 👮♀️)
- Press
- Close Memory or Menu
esccloses the memory (or the menu -- not in Firefox)
- Open the popup:
- Search
- In a paper's authors, title and note.
- Split queries on spaces:
gan imwill look for: all papers whose (title OR author) contain ("gan" AND "im")
- Split queries on spaces:
- In a paper's code link
- Start the search query with
c:to only search code links
- Start the search query with
- In a paper's tags
- Start the search query with
t:to filter by tags t: ganwill look for all papers whose tag-list contains at least 1 tag containing "gan"t: gan timwill look for all papers whose tag-list contains (at least 1 tag containing "gan") AND (at least 1 tag containing "tim")
- Start the search query with
- In a paper's authors, title and note.
- Export your memory as json file (in the extension's Menu)

In the extension's options (right click on the icon or in the popup's menu) you will find advanced customization features:
- Auto-tagging: add tags to papers based on regexs matched on authors and titles
- Custom title function: provide Javascript code to generate your own web page titles and pdf filenames based on a paper's attributes
- Data management: export/load your memory data and export the bibliography as a
.bibfile

- Download the repo
- Go to Chrome/Brave's extension manager
- Enable developer mode
- Click on "load unpackaged extension"
- Select the downloaded repo :)
There currently exists, to my knowledge, no centralized source for matching a preprint to its subsequent published article. This makes it really hard to try and implement best practices in terms of citing published papers rather than their preprint.
My approach with PaperMemory is to try and notify you that a publication likely exists by utilizing the note field. You will occasionally notice Accepted @ X in a Paper's notes. This will be added automatically if you are on a known published venue's website (as PMLR or NeurIPS) but also from:
- CrossRef.org
- A query is sent to their api for an exact paper title match
- The response must contain an
eventfield with anameattribute. If it does not it'll be ignored. - If it does, a note is added as:
Accepted @ ${items.event.name} -- [crossref.org]
- dblp.org
- A query is sent to their api for an exact paper title match
- The oldest
hitin the response which is not a preprint (hit.venue !== "CoRR") is used - If such a match is found, a note is added as:
Accepted @ ${venue} ${year} -- [dblp.org]\n${dblpURL}- Try for instance Domain-Adversarial Training of Neural Networks
- DBLP venues are weird, for instance
JMLRisJ. Mach. Learn. Res.. There's a per-venue fix in the code, raise an issue to add another venue fix
There's room for improvement here^, please contact me (an issue will do) if you want to help
- Improve
Contributing.md - Tests & Docs (WIP => Puppeteer + Mocha #26)