
-
Subdomain Discovery:
- Fetches relevant subdomains for the target website and compiles them into a whitelist. These subdomains can be utilized during the scraping process.
-
Site-wide Link Discovery:
- Gathers all links across the website based on the provided whitelist and the specified
max_depth.
- Gathers all links across the website based on the provided whitelist and the specified
-
Form and Input Extraction:
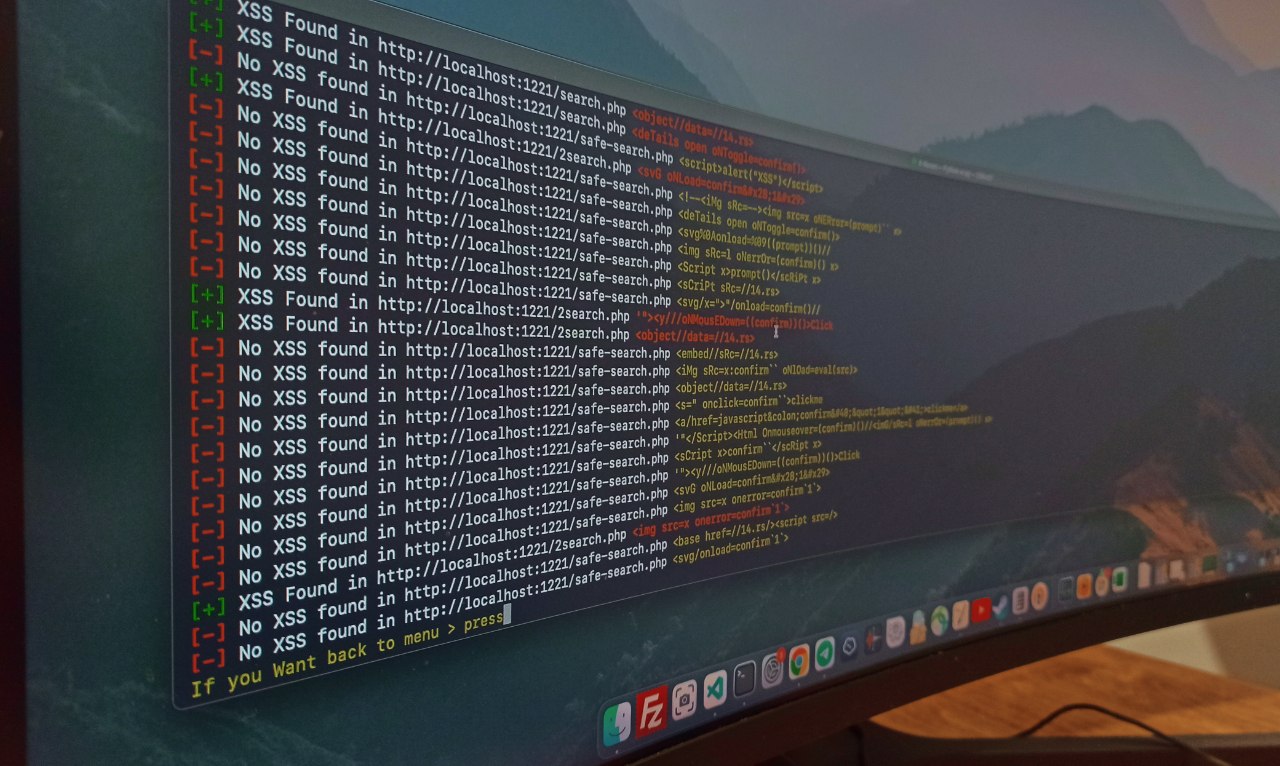
- Identifies all forms and inputs found within the extracted links, creating a JSON output. This JSON output serves as a foundation for leveraging the XSS scanning capability of the tool.


Note:
This tool maintains a current list of file extensions that it skips during the exploration process. The default list includes common file types like images, stylesheets, and scripts (
".css",".js",".mp4",".zip","png",".svg",".jpeg",".webp",".jpg",".gif"). You can customize this list according to your needs; just add alarm items to themodule\costumblocklist.txtfile
$ git clone https://github.com/joshkar/X-Recon
$ cd X-Recon
$ python3 -m pip install -r requirements.txt
$ python3 xr.pyYou can use this address in the Get URL section
http://testphp.vulnweb.com