
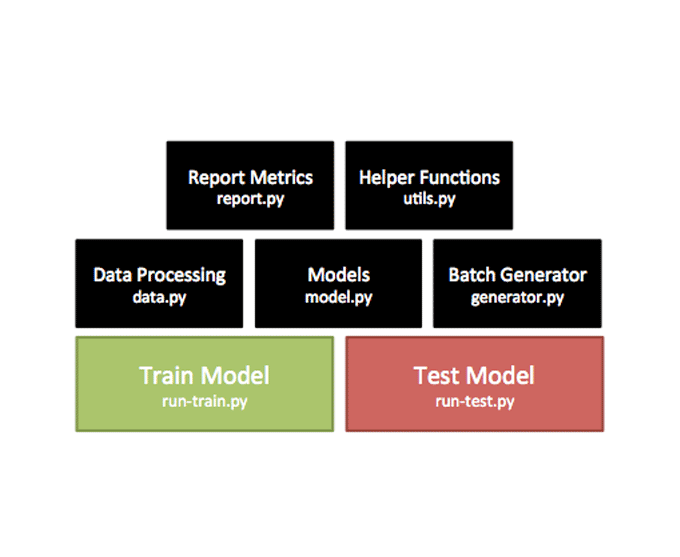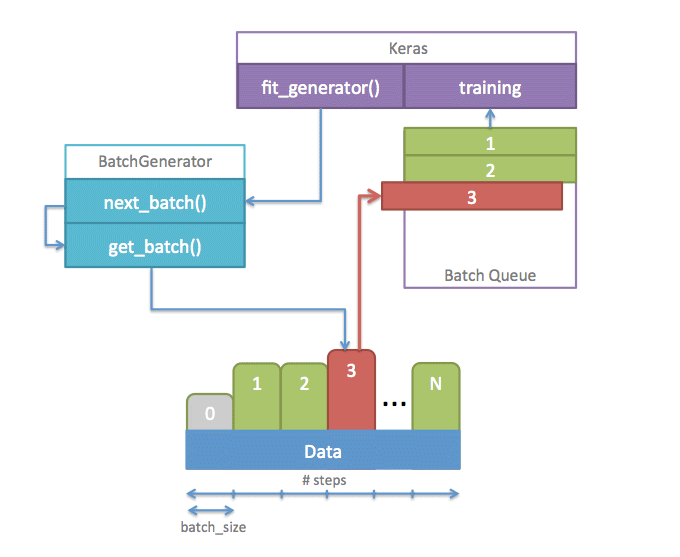
Repository for experimenting with different CTC based model designs for ASR. Supports live recording and testing of speech and quickly creates customised datasets using own-voice dataset creation scripts!
- Recommended > use virtualenv installed with python2.7 (3.x untested and will not work with Core ML)
git clone https://github.com/robmsmt/KerasDeepSpeechpip install -r requirements.txt- Get the data using the import/download scripts in the
folder, LibriSpeech is a good example.
- Download the language model (large file) run
./lm/get_lm.sh
- To Train, simply run
python run-train.pyIn order to specify training/validation files usepython run-train.py --train_files <csvfile> --valid_files <csvfile>(see run-train for complete arguments list) - To Test, run
python run-test.py --test_files <datacsvfile>
- Mozilla DeepSpeech
- Baidu DS1 & DS2 papers
The content of this project itself is licensed under the GNU General Public License. Copyright © 2018
Have a question? Like the tool? Don't like it? Open an issue and let's talk about it! Pull requests are appreciated!