3rd place on Naver NLP Challenge NER Task
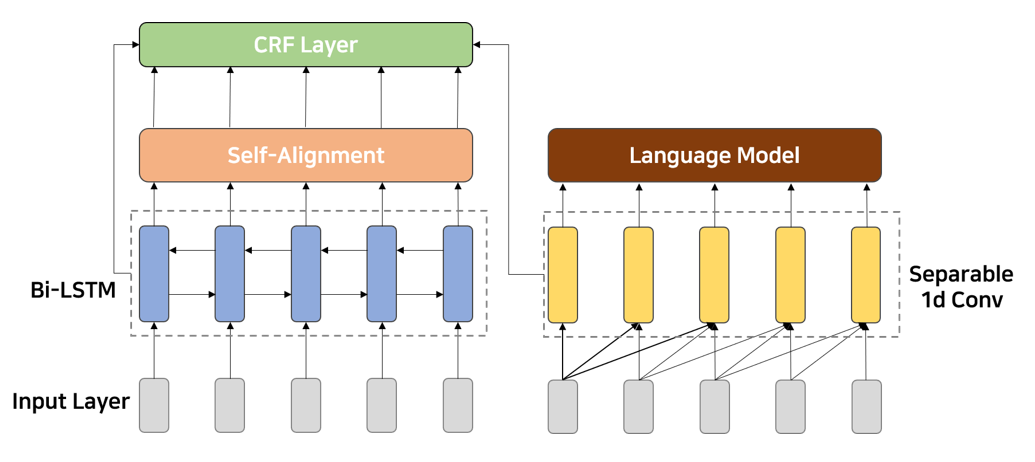
- The code uses BiLSTM + CRF, with multi-head attention and separable convolution.
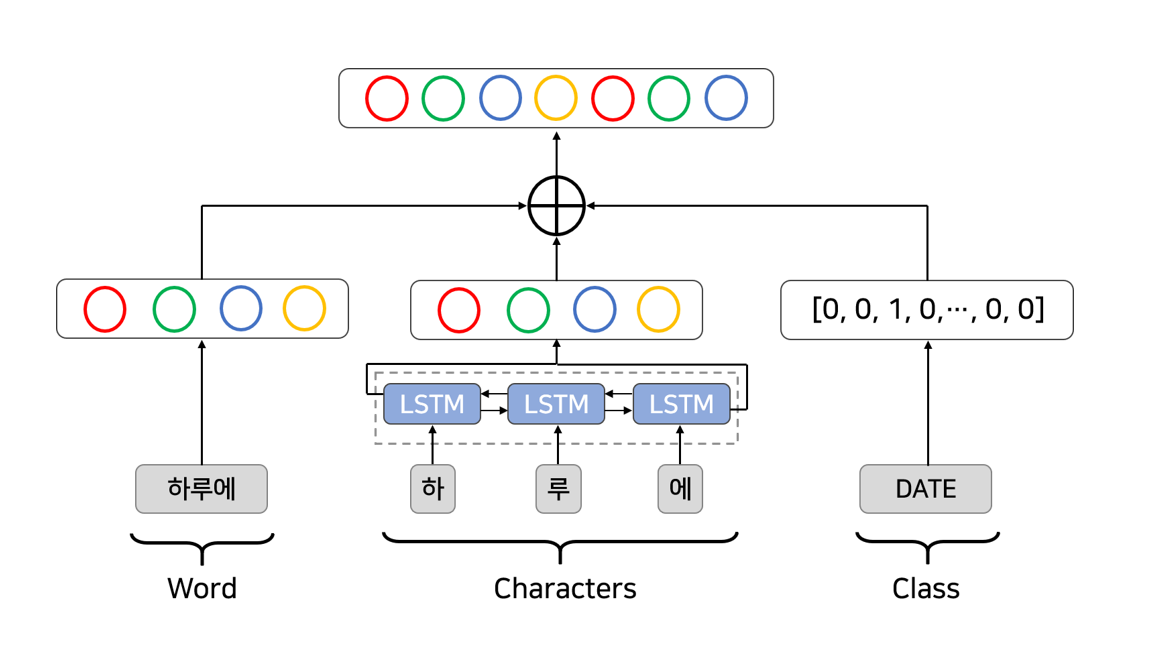
- We used fastText for word and character pretrained embedding.
- Baseline code and dataset was given from Naver NLP Challenge Github.
- Dataset contains 90,000 sentences with NER tags.
- Dataset was provided by Changwon University Adaptive Intelligence Research Lab.
- We use 300-dim Korean fastText. This embedding is basically based on words(어절), but most of the characters(음절) can be covered by fastText, so we also used fastText for character embedding.
- Take out the words and characters that are only in train data sentences and make it into to binary file with pickle library.
- For installing word pretrained embedding (400MB) and char pretrained embedding (5MB)
- Download from this Google Drive Link.
- Make 'word2vec' directory from root directory.
- Put those two file in the 'word2vec' directory.
$ mkdir word2vec
$ mv word_emb_dim_300.pkl word2vec
$ mv char_emb_dim_300.pkl word2vec
- tensorflow (tested on 1.4.1 and 1.11.0)
- numpy
$ python3 main.py
- Link for Naver NLP Challenge: https://github.com/naver/nlp-challenge
- Slideshare Link (Korean): https://www.slideshare.net/JangWonPark8/nlp-challenge
- Park, Jang Won (https://github.com/monologg)
- Lee, Seanie (https://github.com/seanie12)