Reinforcement Learning on FrozenLake is a collection of jupyter files that you can learn and try basic reinforcement learning algorithms.
This repo is written for people who want to quickly learn basic concepts of Reinforcement Learning with code.
2024-11-24: Made a demo version of this repo! link
- Easy explanation of RL concepts
- Interactive RL algorithm
- You can also run RL algorithms in FrozenLake-v1, a OpenAI Gymnasium environment, with hyperparmeter customization.
- Wrapper for the environment can render not only the environment, but also state-action value or model of the algorithms.
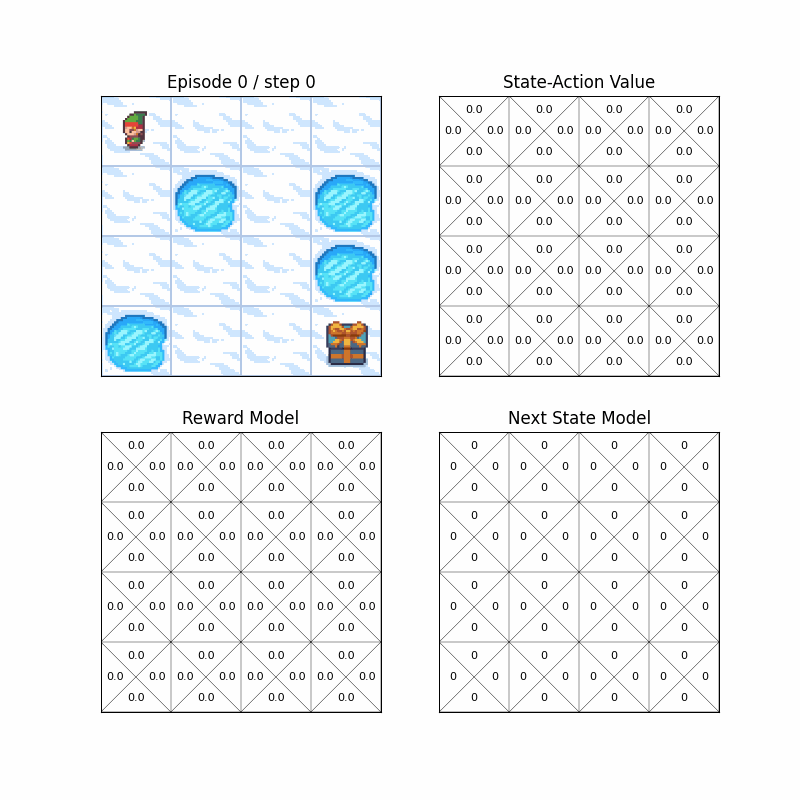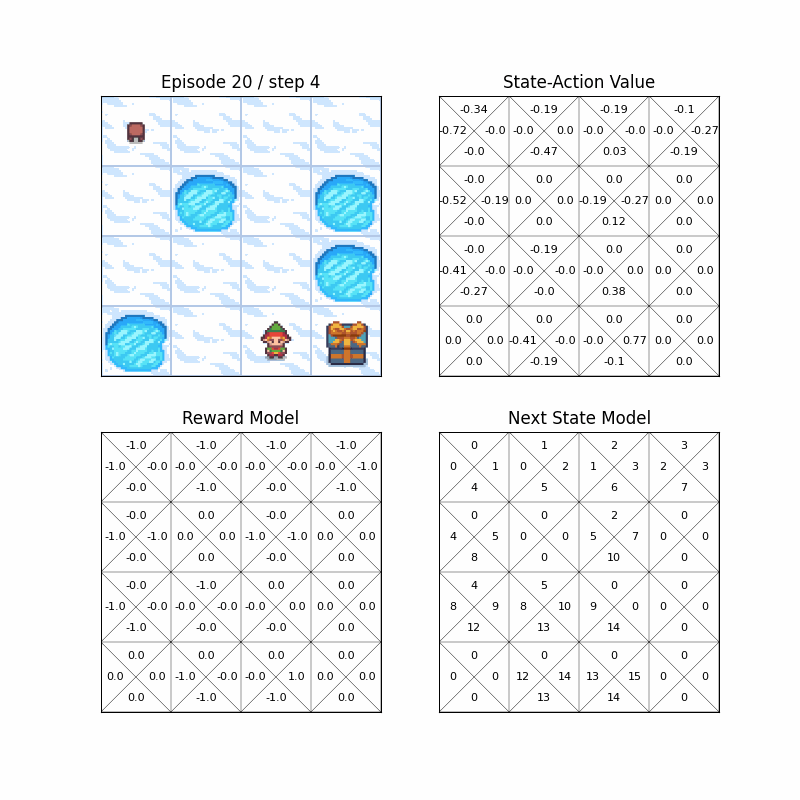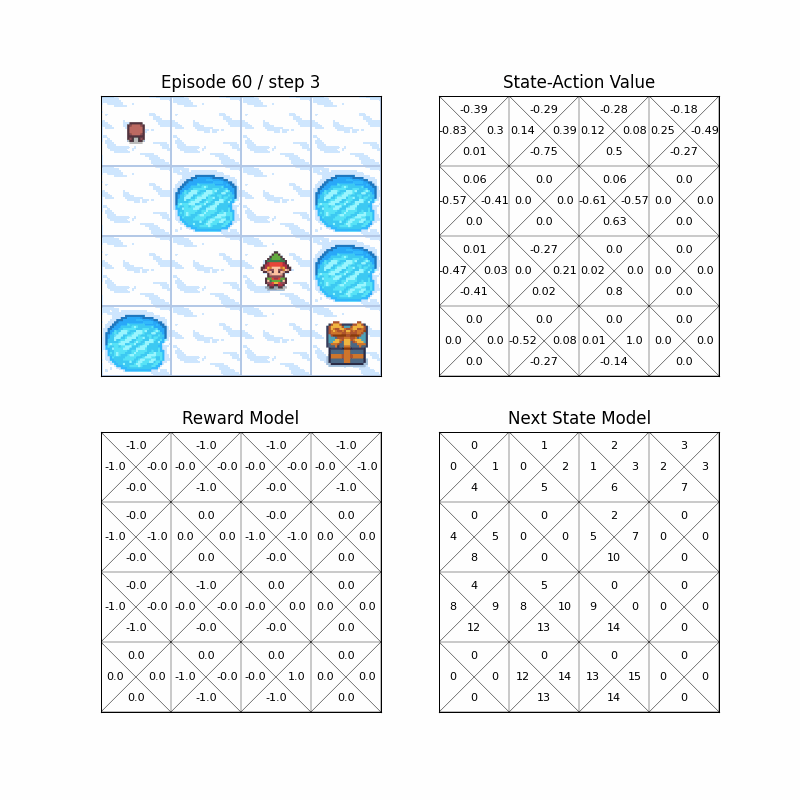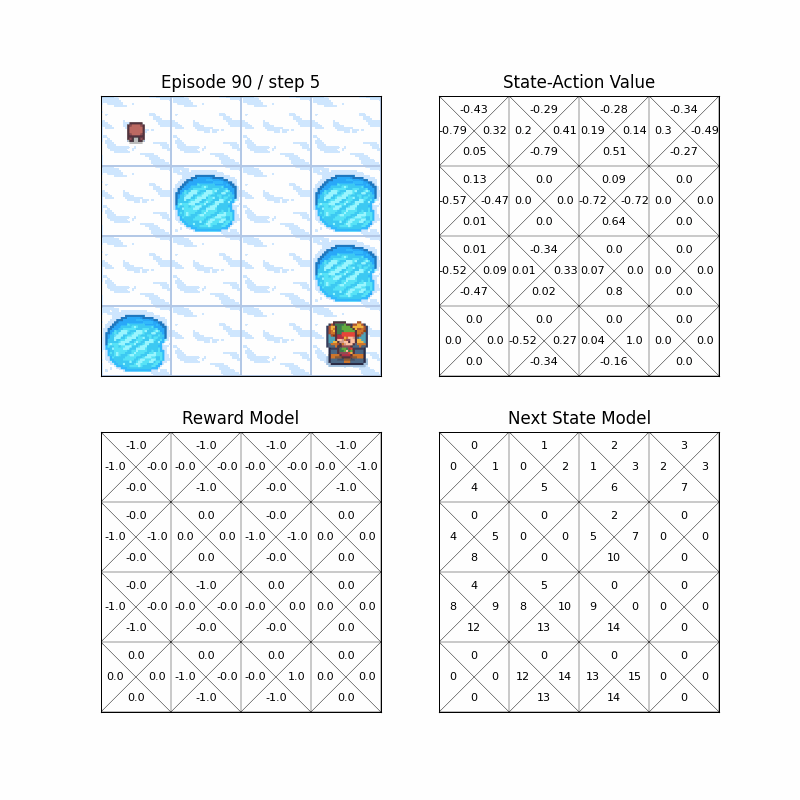

- python >= 3.6
- gymnasium >= 0.26.1
- pygame >= 2.3.1
- tensorflow >= 2.8 (for Chapter 7)
- tensorflow-probability >= 0.22.1 (for Chapter 7)
- ipykernel
- ipython
- numpy
- matplotlib
You can install the requirements by using Poetry.
git clone https://github.com/moripiri/Reinforcement-Learning-on-FrozenLake.git
cd Reinforcement-Learning-on-FrozenLake
poetry install #--with ch7 #(If you want to run chapter7.ipynb, optional tensorflow dependency have to be installed.
poetry run python -m ipykernel install --user --name [virtualEnv] --display-name "[displayKernelName]"where [virtualEnv] is the name of the python environment(ex. rl-introduction-py3.9) and "[displayKernelName]" is the jupyter kernel name you want (ex. frozenlake).
Then run
poetry run jupyter notebookto run jupyter files.
If you run any jupyter file in google colab, run the following commands first.
!git clone https://github.com/moripiri/Reinforcement-Learning-on-FrozenLake.git
%cd Reinforcement-Learning-on-FrozenLake/
!pip install gymnasium[classic_control]==0.26.3- Policy iteration
- Value iteration
- Monte-Carlo Prediction
- TD(0)
- On-policy Monte-Carlo Control
- SARSA
- Q-learning
- SARSA(λ)
- REINFORCE
- Actor-Critic
- Dyna-Q