Here is a prototype on productionizing a ML model pipeline, and monitoring it for drift, for subsequent retraining and deployment.
This uses glassware manufacturing dataset, which is synthesized to showcase model drift.
To review the code in notebook format using HTML https://joelcthomas.github.io/modeldrift
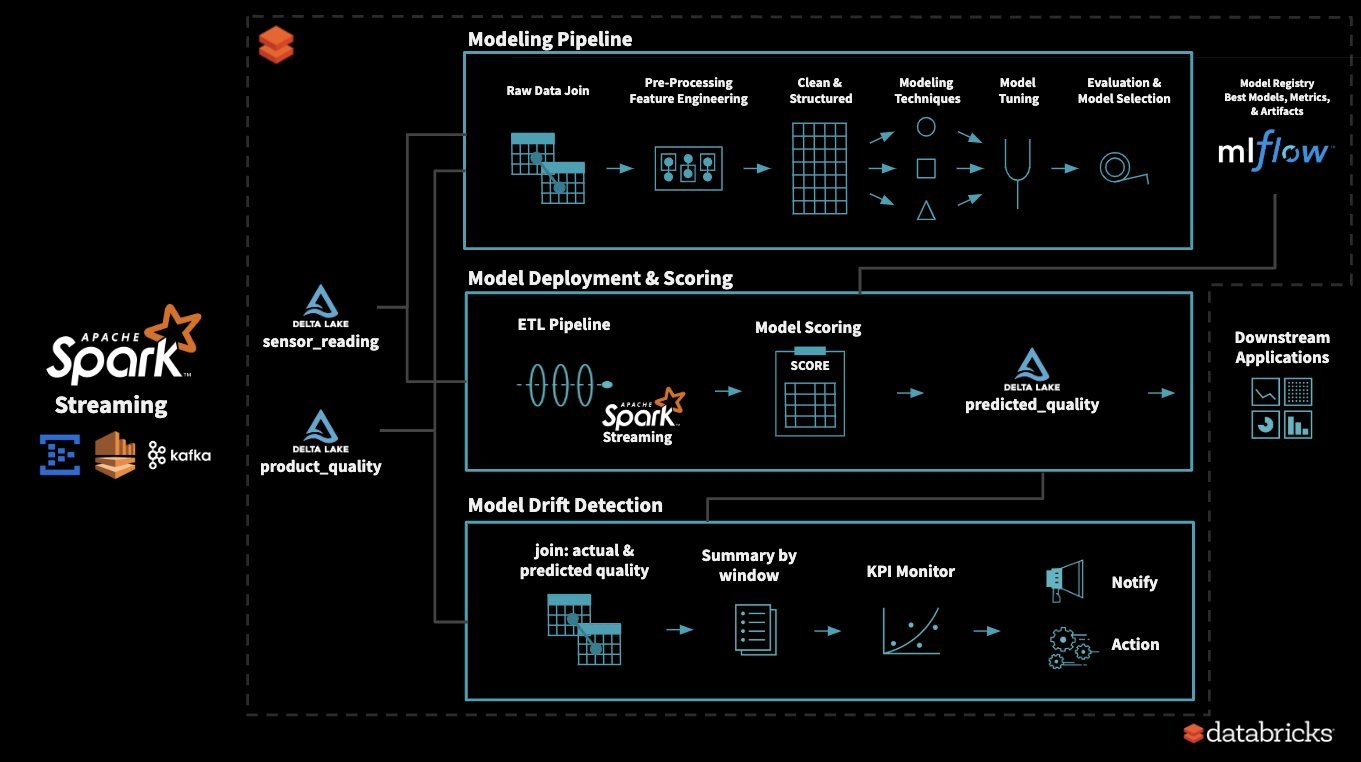
- To understand the data, we start with EDA (Exploratory Data Analysis)
- Using historical data, we explore various modeling methods, tune its hyperparameters, and identify our best model
- All the experiment runs are tracked using MLflow and we tag the best model for production use
- While scoring in a streaming pipeline, production model is accessed from MLflow
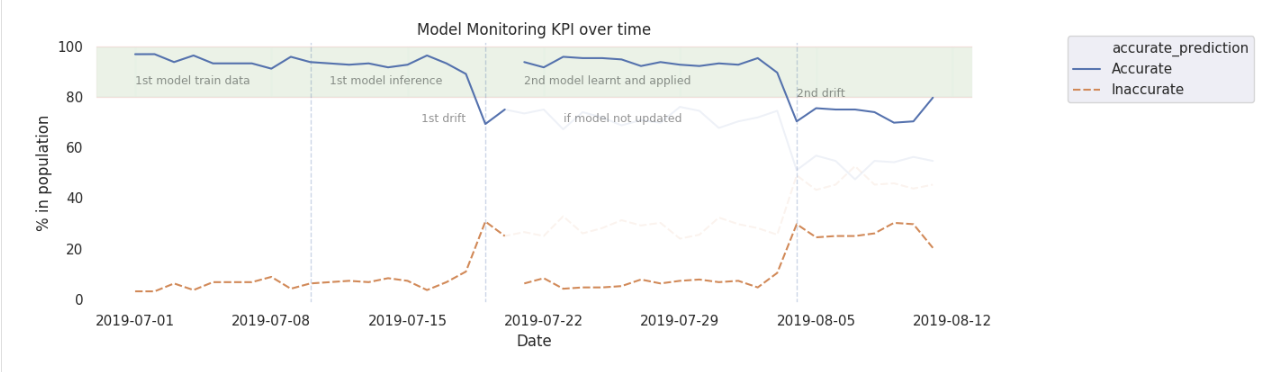
- Model is stable for first ‘x’ days
- Model Drift KPIs
- KPIs and its margin depends on the model and business problem
- Sometimes more than 1 KPI maybe needed at times to capture behavior changes
- After ‘y’ days, we see model drift occur, as identified by tracking KPIs
- This triggers re-training process
- Once again, we explore various modeling methods, tune its hyperparameters, and identify our new best model
- The new model is tagged as current production model in MLflow
- We once again observe that KPIs are back within acceptable range
- Over time, based on business demands, it may be needed to update KPIs and its acceptable limits
To reproduce this example, please import attached model_drift_webinar.dbc file to databricks workspace.
Instructions on how to import notebooks in databricks
For more information on using databricks
https://docs.databricks.com/