Working in a command line environment is recommended for ease of use with git and dvc. If on Windows, WSL1 or 2 is recommended.
- Download and install conda if you don’t have it already.
- Use the supplied requirements file to create a new environment, or
- conda create -n [envname] "python=3.8" scikit-learn dvc pandas numpy pytest jupyter jupyterlab fastapi uvicorn -c conda-forge
- Install git either through conda (“conda install git”) or through your CLI, e.g. sudo apt-get git.
conda create -n udacity-c3-project "python=3.8" scikit-learn dvc pandas numpy pytest jupyter jupyterlab fastapi uvicorn -c conda-forgeconda activate udacity-c3-projectpip3 install -r requirements.txt
- Create a directory for the project and initialize Git and DVC.
- As you work on the code, continually commit changes. Trained models you want to keep must be committed to DVC.
- Connect your local Git repository to GitHub.
- In your CLI environment install the AWS CLI tool.
- In the navigation bar in the Udacity classroom select Open AWS Gateway and then click Open AWS Console. You will not need the AWS Access Key ID or Secret Access Key provided here.
- From the Services drop down select S3 and then click Create bucket.
- Give your bucket a name, the rest of the options can remain at their default.
To use your new S3 bucket from the AWS CLI you will need to create an IAM user with the appropriate permissions. The full instructions can be found here, what follows is a paraphrasing:
- Sign in to the IAM console here or from the Services drop down on the upper navigation bar.
- In the left navigation bar select Users, then choose Add user.
- Give the user a name and select Programmatic access.
- In the permissions selector, search for S3 and give it AmazonS3FullAccess
- Tags are optional and can be skipped.
- After reviewing your choices, click create user.
- Configure your AWS CLI to use the Access key ID and Secret Access key.
- Setup GitHub Actions on your repository. You can use one of the pre-made GitHub Actions if at a minimum it runs pytest and flake8 on push and requires both to pass without error.
- Make sure you set up the GitHub Action to have the same version of Python as you used in development.
- Add your AWS credentials to the Action.
- Set up DVC in the action and specify a command to
dvc pull.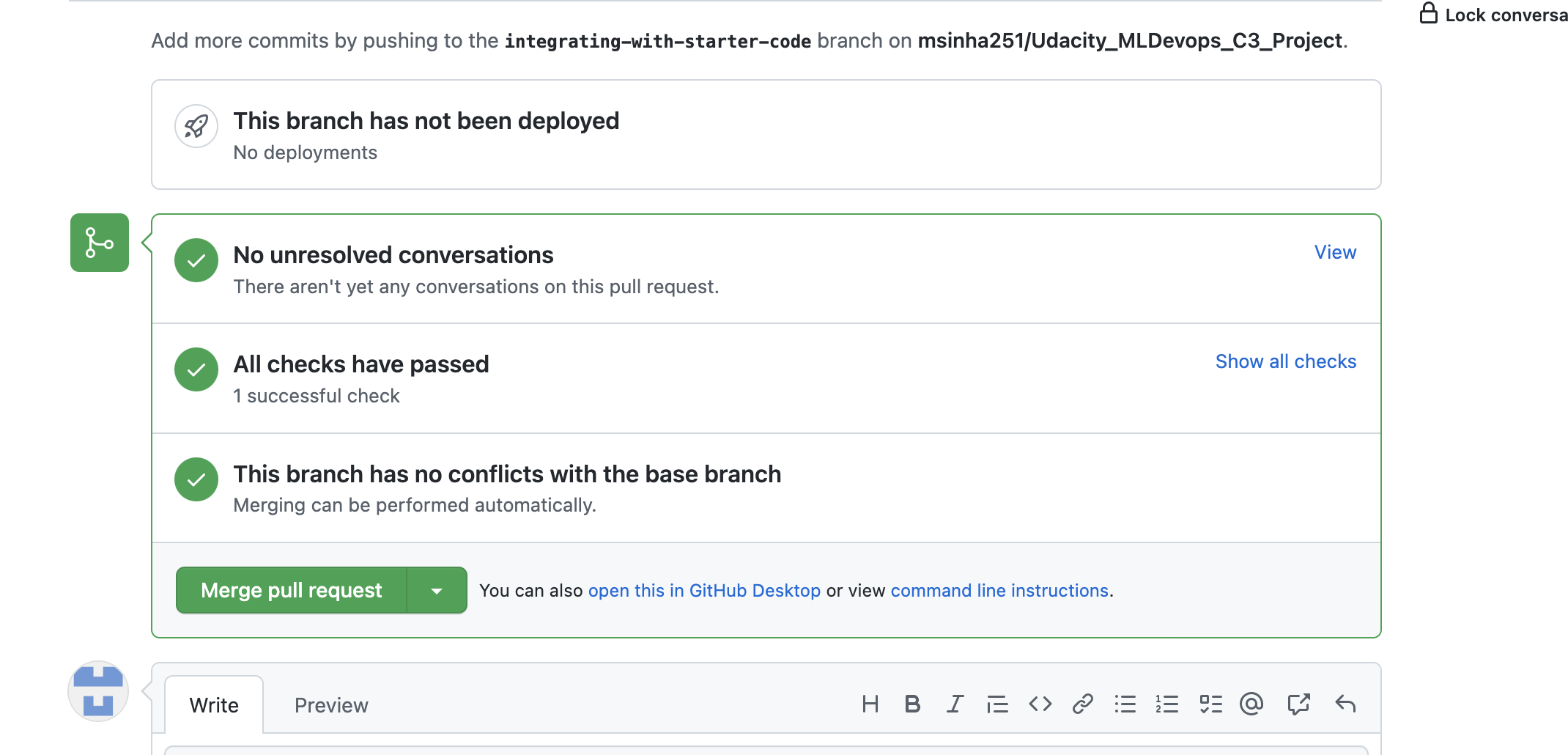

- Download census.csv from the data folder in the starter repository.
- Information on the dataset can be found here.
- Create a remote DVC remote pointing to your S3 bucket and commit the data.
- This data is messy, try to open it in pandas and see what you get.
- To clean it, use your favorite text editor to remove all spaces.
- Commit this modified data to DVC under a new name (we often want to keep the raw data untouched but then can keep updating the cooked version).


- Using the starter code, write a machine learning model that trains on the clean data and saves the model. Complete any function that has been started.
- Write unit tests for at least 3 functions in the model code.
- Write a function that outputs the performance of the model on slices of the data.
- Suggestion: for simplicity, the function can just output the performance on slices of just the categorical features.
- Write a model card using the provided template. Model Card
- Create a RESTful API using FastAPI this must implement:
- GET on the root giving a welcome message.
- POST that does model inference.
- Type hinting must be used.
- Use a Pydantic model to ingest the body from POST. This model should contain an example.
- Hint: the data has names with hyphens and Python does not allow those as variable names. Do not modify the column names in the csv and instead use the functionality of FastAPI/Pydantic/etc to deal with this.
- Write 3 unit tests to test the API (one for the GET and two for POST, one that tests each prediction).
example.png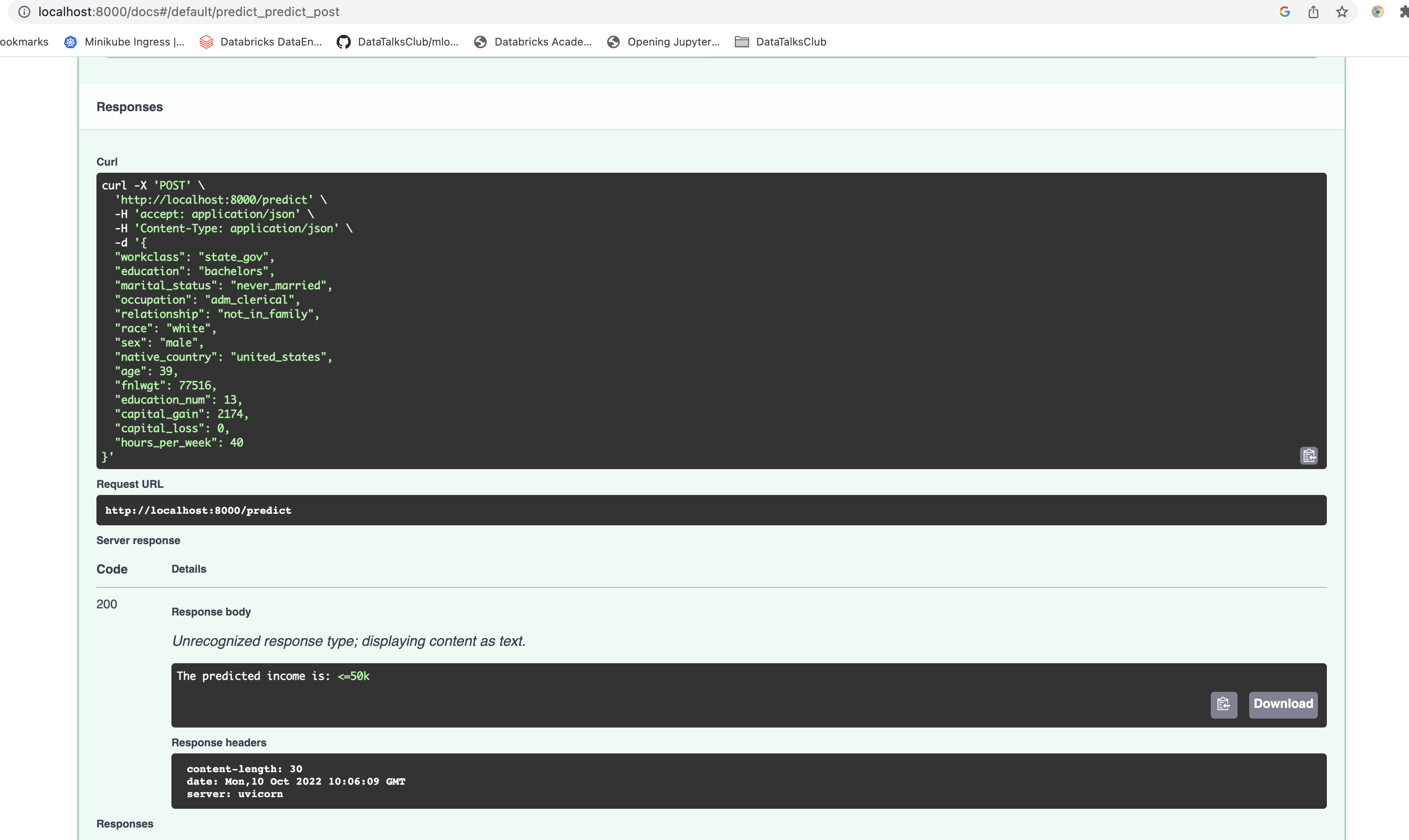

live_get.png

live_post.png

- Create a free Heroku account (for the next steps you can either use the web GUI or download the Heroku CLI).
- Create a new app and have it deployed from your GitHub repository.
- Enable automatic deployments that only deploy if your continuous integration passes.
- Hint: think about how paths will differ in your local environment vs. on Heroku.
- Hint: development in Python is fast! But how fast you can iterate slows down if you rely on your CI/CD to fail before fixing an issue. I like to run flake8 locally before I commit changes.
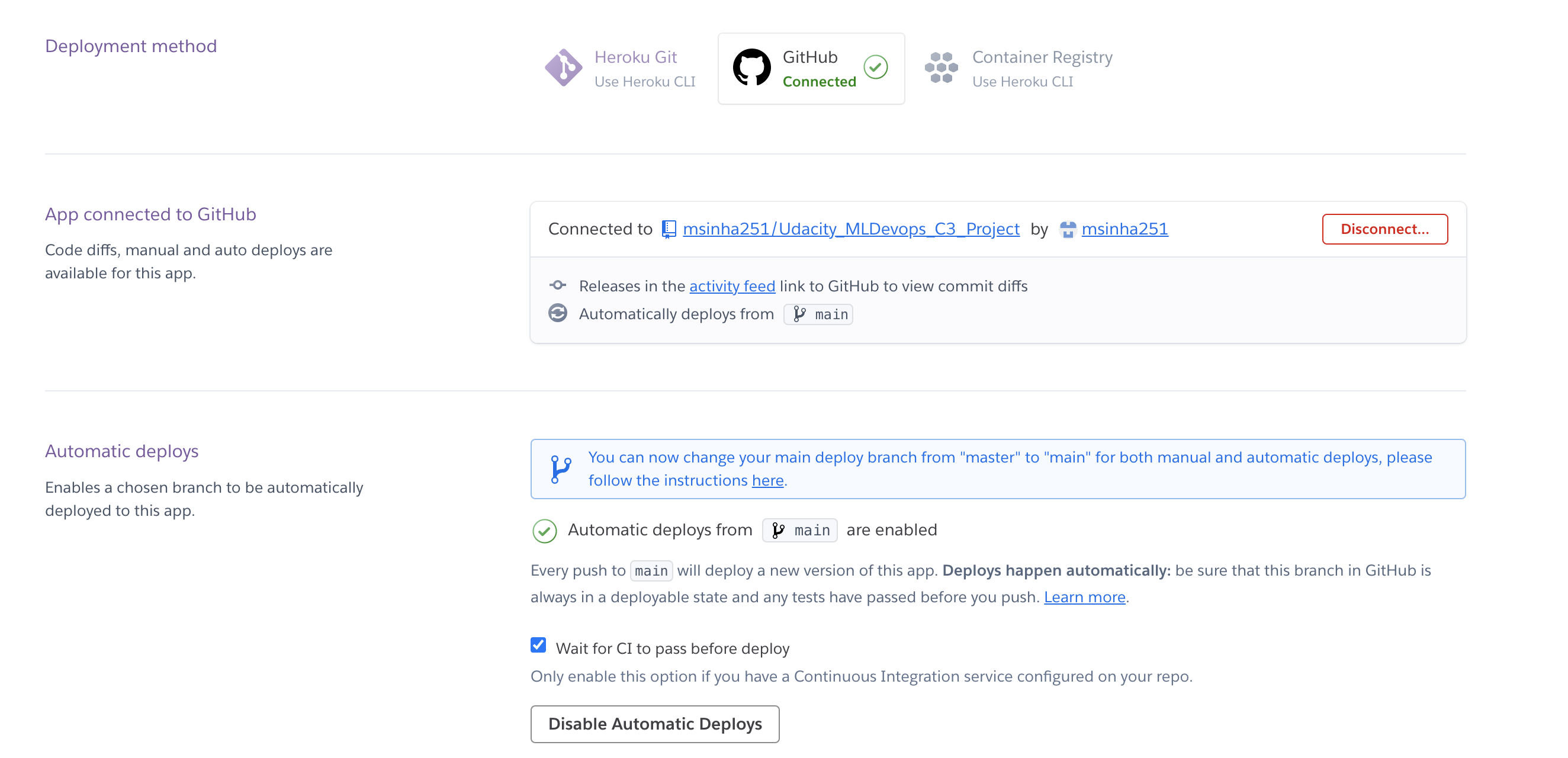
- Set up DVC on Heroku using the instructions contained in the starter directory.
- Set up access to AWS on Heroku, if using the CLI:
heroku config:set AWS_ACCESS_KEY_ID=xxx AWS_SECRET_ACCESS_KEY=yyy - Write a script that uses the requests module to do one POST on your live API.
