
HyperQueue (HQ) lets you build a computation plan consisting of a large amount of tasks and then execute it transparently over a system like SLURM/PBS. It dynamically groups jobs into SLURM/PBS jobs and distributes them to fully utilize allocated notes. You thus do not have to manually aggregate your tasks into SLURM/PBS jobs.
-
Performance
- The inner scheduler can scale to hundreds of nodes
- The overhead per one task is below 0.1ms.
- HQ allows streaming outputs from tasks to avoid creating many small files on a distributed filesystem
-
Easy deployment
- HQ is provided as a single, statically linked binary without any dependencies
- No admin access to a cluster is needed
-
Download the latest binary distribution from this link.
-
Unpack the downloaded archive:
$ tar -xvzf hq-<version>-linux-x64.tar.gz
If you want to try the newest features, you can also download a nightly build.
-
Start a server (e.g. on a login node or in a cluster partition)
$ hq server start & -
Submit a job (command
echo 'Hello world'in this case)$ hq submit echo 'Hello world'
-
Ask for computing resources
-
Start worker manually
$ hq worker start & -
Automatic submission of workers into PBS/SLURM
-
PBS:
$ hq alloc add pbs --time-limit 1h -- -q <queue>
-
Slurm:
$ hq alloc add slurm --time-limit 1h -- -p <partition>
-
-
Manual request in PBS
-
Start worker on the first node of a PBS job
$ qsub <your-params-of-qsub> -- hq worker start
-
Start worker on all nodes of a PBS job
$ qsub <your-params-of-qsub> -- `which pbsdsh` hq worker start
-
-
Manual request in SLURM
-
Start worker on the first node of a Slurm job
$ sbatch <your-params-of-sbatch> --wrap "hq worker start"
-
Start worker on all nodes of a Slurm job
$ sbatch <your-params-of-sbatch> --wrap "srun hq worker start"
-
-
-
Monitor the state of jobs
$ hq job list --all
Check out the documentation.
-
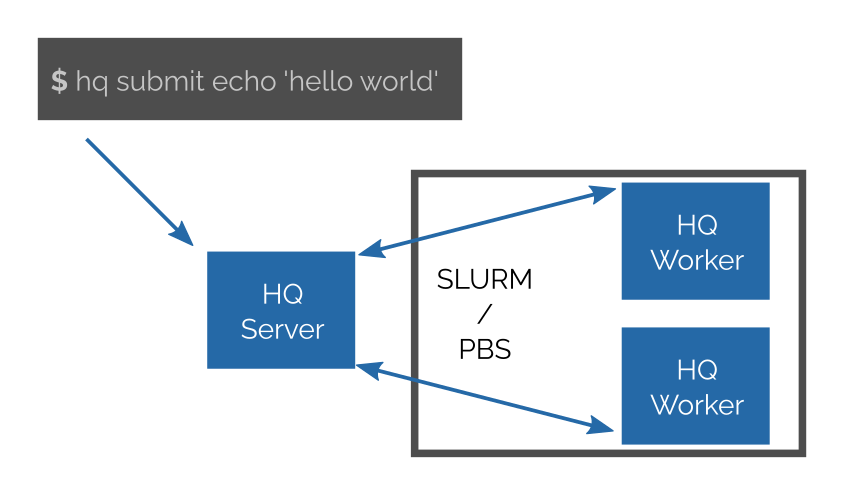
How HQ works?
You start a HQ server somewhere (e.g. login node, cloud partition of a cluster). Then you can submit your jobs to the server. You may have hundreds of thousands of jobs; they may have various CPUs and other resource requirements.
Then you can connect any number of HQ workers to the server (either manually or via SLURM/PBS). The server will then immediately start to assign jobs to them.
Workers are fully and dynamically controlled by server; you do not need to specify what jobs are executed on a particular worker or preconfigure it in any way.
HQ provides a command line tool for submitting and controlling jobs.
-
What is a job in HQ?
Right now, we support running arbitrary external programs or bash scripts. We plan to support Python defined workflows (with a Dask-like API).
-
How to deploy HQ?
HQ is distributed as a single, self-contained and statically linked binary. It allows you to start the server, the workers, and it also serves as CLI for submitting and controlling jobs. No other services are needed. (See example below).
-
Do I need to SLURM or PBS to run HQ?
No. Even though HQ is designed to smoothly work on systems using SLURM/PBS, they are not required for HQ to work.
-
Is HQ a replacement for SLURM or PBS?
Definitely no. Multi-tenancy is out of the scope of HQ, i.e. HQ does not provide user isolation. HQ is light-weight and easy to deploy; on a HPC system each user (or a group of users that trust each other) may run her own instance of HQ.
-
Do I need an HPC cluster to run HQ?
No. None of functionality is bound to any HPC technology. Communication between all components is performed using TCP/IP. You can also run HQ locally.
-
Is it safe to run HQ on a login node shared by other users?
Yes. All communication is secured and encrypted. The server generates a secret file and only those users that have access to it file may submit jobs and connect workers. Users without access to the secret file will only see that the service is running.
-
What is the difference between HQ and Snakemake?
In cluster mode, Snakemake submits each Snakemake job as one job into SLURM/PBS. If your jobs are too small, you will have to manually aggregate them to avoid exhausting SLURM/PBS resources. Manual job aggregation is often quite arduous and since the aggregation is static, it might also waste resources because of poor load balancing.
In the case of HQ, you do not have to aggregate jobs. You can submit millions of small jobs to HQ and it will take care of assigning them dynamically to individual SLURM/PBS jobs and workers.
-
How many jobs may I submit into HQ?
Our preliminary benchmarks show that overhead of HQ is around 0.1 ms per task. We also support streaming of task outputs into a single file (this file contains metadata, hence outputs for each task can be filtered or ordered). This avoids creating many small files for each task on a distributed file system that may have a large impact on scaling.
-
Does HQ support multi-CPU jobs?
Yes. You can define number of CPUs for each job. HQ is NUMA aware and you can choose the allocation strategy.
-
Does HQ support job arrays?
Yes.
-
Does HQ support jobs with dependencies?
Not yet. It is actually implemented in the scheduling core, but it has no user interface yet. But we consider it as a crucial must-have feature.
-
How is HQ implemented?
HQ is implemented in Rust and uses Tokio ecosystem. The scheduler is work-stealing scheduler implemented in our project Tako, that is derived from our previous work RSDS. Integration tests are written in Python, but HQ itself does not depend on Python.
-
Who stands behind HyperQueue?
We are a group at IT4Innovations, the Czech National Supercomputing Center. We welcome any contribution from outside.

- API for dependencies
- Python API
- Dashboard
- Multi-node tasks
-
This work was supported by the LIGATE project. This project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No 956137. The JU receives support from the European Union’s Horizon 2020 research and innovation programme and Italy, Sweden, Austria, the Czech Republic, Switzerland.
-
This work was supported by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90140).