The goal of this task is to automatically identify which posts are truly relevant to flooding incidents in the specific area of Northeastern Italy, by using their text, images, and other metadata.
- 31 July 2020: The development set is now available to download.
- 14 October 2020: The task schedule has been updated.
- 19 October 2020: The test set is now available to download.
- 17 December 2020: The final version of the test set and the respective ground truth is now available to download.
- 31 July: Development set release
10 October19 October: Test set release23 October9 November: Runs due- 16 November: Results returned
- 30 November: Working notes paper
- 11, 14-15 December: MediaEval 2020 Workshop
The Flood-related Multimedia Task tackles the analysis of social multimedia from Twitter for flooding events. In this task, the participants receive a set of Twitter posts (tweets) and their associated images, which contain keywords related to floods in a specific area of interest, specifically, the Eastern Alps partition in Northeastern (NE) Italy. However, the relevance of the tweets to actual flooding incidents in that area is ambiguous. The objective of the task is to build an information retrieval system or a classifier that is able to distinguish whether or not a tweet is relevant to a flooding event in the examined area.
The dataset of the task consists of Italian-language tweets, motivated by the common flood events in the cities of Eastern Alps (e.g., Venice, Vicenza, Trieste) and surrounding areas. Participants can tackle the task using text features, image features, or a combination of both. We choose Italian for this task in order to encourage researchers to move away from a focus on English.
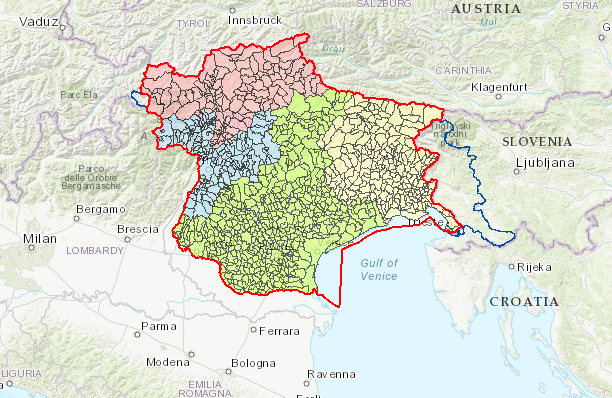
The area of interest: Eastern Alps partition in North-East Italy
Participation in this task involves the following steps:
- Download the development data and design your approach.
- When the test set is released, run your system on the test data and submit up to 5 runs.
- Receive your evaluation results (in terms of the official evaluation metric of the task), which you must report in the working notes paper.
- Write and submit your working notes paper; different runs must all be described.
The dataset consists of 5,419 Tweet IDs (dev-set) and 2,288 Tweet IDs (test-set) that have been collected from Twitter between 2017 and 2019, by searching for Italian flood-related keywords (e.g., “allagamento”, “alluvione”) inside the tweet text. All tweets contain an attached image and should be still online at the time of releasing the dataset. In order to be compliant with the Twitter Developer Policy, only the IDs of the tweets can be distributed, but an additional tool to download the complete tweets and embedded images is provided (developed by Benjamin Bischke for the Multimedia Satellite Task at MediaEval 2018).
The ground truth data of the dataset consists of one class label for the relevancy of each Tweet ID and has been collected with human annotation, by the Alto Adriatico Water Authority (AAWA), who are experts on flood risk management in the Eastern Alps partition of NE Italy. It should be noted here that only tweets that refer to floods in this specific region have been annotated as relevant.
Ground truth is provided to participants in a JSON file devset_tweets_gt.json, which contains key-value pairs of Tweet ID and ground truth label for the relevancy (0=not relevant/1=relevant). An example is presented below:
[{"912629686458568704": 0},
{"992823890928984065": 0},
...
{"956404575585619968": 0}]
The following files are provided:
devset_tweets_ids.jsoncontains the Tweet IDs of the development set and can be found heredevset_tweets_gt.jsoncontains the Ground Truth labels for relevancy for all tweets and can be found heretestset_tweets_ids.jsoncontains the Tweet IDs of the test set and can be found here
The script found here and developed by Benjamin Bischke provides you support for downloading tweets and embedded images using the distributed files of Tweet IDs, since we are not allowed, unfortunately, to distribute the original tweets and images. Please follow the instructions below. If you have any questions or problems, please contact andreadisst@iti.gr.
- Install Python on your system (https://www.python.org/downloads/) if you do not already use it. The script works for both versions - Python 2.7 and Python 3.
- Make sure all required python packages are installed by executing:
pip install -r requirements.txtin your console. Therequirements.txtcan be found here - If you are using Python 3.7, then install Tweepy library as follows:
pip3 install git+https://github.com/tweepy/tweepy.git
- Create a Twitter Account if you do not already have one. (https://twitter.com/i/flow/signup)
- Follow this guide to retrieve access credentials for the Twitter API. (https://developer.twitter.com/en/docs/basics/authentication/oauth-1-0a/obtaining-user-access-tokens)
- Set your private keys in the beginning of the script
download_tweets.py(lines 65-68)
You can start the download with the following call:
python download_tweets.py -f ./path/to/the/file/devset_tweets_ids.json -o /your/output/directory
With the first option you can specify the path to the distributed Tweet IDs file and with the second option the path to the output folder, in which the Twitter data should be stored.
If you have more than 4 cores available on your system and you want to speed up the download of the images, you can parallelise among more processes by specifying the option -p YourNumberOfProcesses.
For more options please see python download_tweets.py -h.
For this task you may submit up to 5 runs. Please be sure to submit the following types of runs:
- Required run: automated using textual-visual fused
- Optional run: automated using textual information only
- Optional run: automated using visual information only
- General run: everything automated allowed, including using data from external sources
- General run: everything automated allowed, including using data from external sources
Please note that for generating runs 1 to 3 participants are allowed to use only information that can be extracted from the provided tweets (icluding metadata), while for runs 4 & 5 everything is allowed, both from the method point of view and the information sources.
Please submit your runs for the task in the form of a text file, where each line contains one Tweet ID followed by the label for the relevancy (0=not relevant/1=relevant). Tweet IDs and the labels should be comma separated. An example should look like this:
1090969737671131140,0
1186690804921913346,1
...
1199328865484713984,0
Please note that no white spaces or other special characters are allowed. When you create the filenames for your runs, please follow this pattern:
ME20FMT_YYY_ZZZ.txt
where ME20FMT is the code of the task, YYY is the acronym of your team and ZZZ is the number of your run (001, 002, 003, 004, 005).
Please upload your runs in a compressed (zip/rar) file using the following Google form: https://forms.gle/tKBwZw9YEmFE4o7fA
The correctness of retrieved tweets for the two classes relevant and not relevant will be evaluated with the F1-Score metric on the test set.
[1] Moumtzidou, A., Andreadis, S., Gialampoukidis, I., Karakostas, A., Vrochidis, S. and Kompatsiaris, I., 2018, April. Flood relevance estimation from visual and textual content in social media streams. In Companion Proceedings of the The Web Conference 2018 (pp. 1621-1627).
[2] Peters, R. and de Albuquerque, J.P., 2015. Investigating images as indicators for relevant social media messages in disaster management. In ISCRAM.
[3] Li, H., Guevara, N., Herndon, N., Caragea, D., Neppalli, K., Caragea, C., Squicciarini, A.C. and Tapia, A.H., 2015, May. Twitter Mining for Disaster Response: A Domain Adaptation Approach. In ISCRAM.
[4] Imran, M., Castillo, C., Lucas, J., Meier, P. and Vieweg, S., 2014, April. AIDR: Artificial intelligence for disaster response. In Proceedings of the 23rd International Conference on World Wide Web (pp. 159-162).
[5] Brouwer, T., Eilander, D., Van Loenen, A., Booij, M.J., Wijnberg, K.M., Verkade, J.S. and Wagemaker, J., 2017. Probabilistic flood extent estimates from social media flood observations. Natural Hazards & Earth System Sciences, 17(5).
We also recommend to read past years’ task papers in the MediaEval Proceedings:
[1] Proceedings of the MediaEval 2019 Workshop.
[2] Martha Larson, et al. (eds.) 2018. Proceedings of the MediaEval 2018 Workshop, Sophia Antipolis, France, Oct. 29-31, 2018.
[3] Guillaume Gravier et al. (eds.) 2017. Proceedings of the MediaEval 2017 Workshop, Dublin, Ireland, Sept. 13-15, 2017.
Stelios Andreadis, Information Technologies Institute - Centre of Research and Technology Hellas (ITI - CERTH), Greece, andreadisst@iti.gr
Ilias Gialampoukidis, Information Technologies Institute - Centre of Research and Technology Hellas (ITI - CERTH), Greece
Anastasios Karakostas, Information Technologies Institute - Centre of Research and Technology Hellas (ITI - CERTH), Greece
Stefanos Vrochidis, Information Technologies Institute - Centre of Research and Technology Hellas (ITI - CERTH), Greece
Ioannis Kompatsiaris, Information Technologies Institute - Centre of Research and Technology Hellas (ITI - CERTH), Greece
Roberto Fiorin, Alto Adriatico Water Authority (AAWA), Italy
Daniele Norbiato, Alto Adriatico Water Authority (AAWA), Italy
Michele Ferri, Alto Adriatico Water Authority (AAWA), Italy

EOPEN project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement 776019.