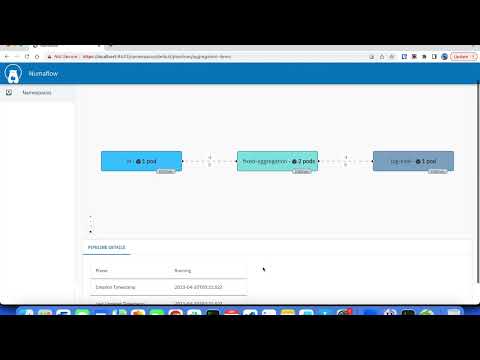
Numaflow is a Kubernetes-native tool for running massively parallel stream processing. A Numaflow Pipeline is implemented as a Kubernetes custom resource and consists of one or more source, data processing, and sink vertices.
Numaflow installs in a few minutes and is easier and cheaper to use for simple data processing applications than a full-featured stream processing platforms.
- Real-time data analytics applications.
- Event driven applications such as anomaly detection, monitoring, and alerting.
- Streaming applications such as data instrumentation and data movement.
- Workflows running in a streaming manner.
- Kubernetes-native: If you know Kubernetes, you already know how to use Numaflow.
- Language agnostic: Use your favorite programming language.
- Exactly-Once semantics: No input element is duplicated or lost even as pods are rescheduled or restarted.
- Auto-scaling with back-pressure: Each vertex automatically scales from zero to whatever is needed.
- Minimally provide at-least-once semantics
- Provide exactly-once semantics for unbounded and near real-time data sources
- Preserving order is not required
- Numaflow UI with CRUD and 1.0 Release (11/01/2023)