- CUDA optimized forward computation
- CUDA optimized backward computation
- Testing
- Training language models
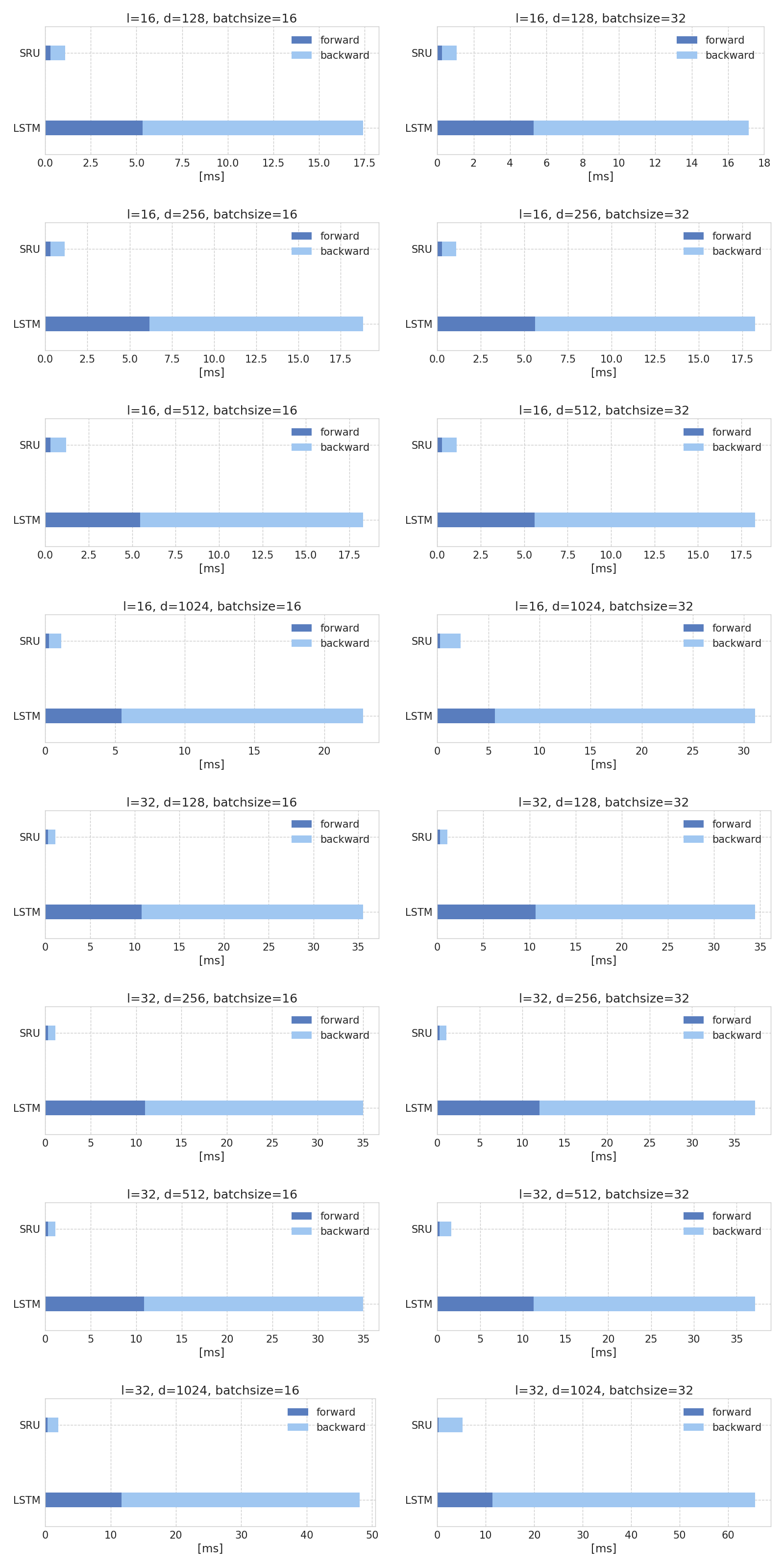
- Benchmark
- Multi-GPU
- Chainer 2+
- CuPy
- Python 2 or 3
cd examples/ptb
python3 train.py -b 32 -nf 128 -l 35 -opt msgd -lr 1 -g 0 -e 300 -lrd 30 -nl 2 -m 128x2.hdf5 -dos 0.5 -dor 0.2 -tanh
python3 train.py -b 32 -nf 320 -l 35 -opt msgd -lr 1 -g 0 -e 300 -lrd 30 -nl 2 -m 320x2.hdf5 -dos 0.5 -dor 0.2 -tanh
| Model | #layers | d | Perplexity |
|---|---|---|---|
| LSTM | 2 | 640 | 89 |
| SRU | 2 | 640 | 92 |
| SRU | 2 | 320 | 92 |
| LSTM | 2 | 320 | 93 |
| SRU | 2 | 128 | 110 |
| LSTM | 2 | 128 | 117 |