Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte
Computer Vision Lab, CAIDAS, University of Würzburg | MegaStudyEdu, South Korea
TLDR: Photorealistic super-resolution of compressed images using transformers / neural networks.
At AISP there is more work on image processing, low-level vision and computational photography.
News 🚀🚀
- [06/2023] Researchers from the Technion–Israel Institute of Technology use Swin2SR in a novel work "Deep Optimal Transport: A Practical Algorithm for Photo-realistic Image Restoration"
- [06/2023] After 7 months, the online app reached 1.8 million runs on replicate! Try it out
- [01/2023] Swin2SR is integrated into Stable Difussion webui by AUTOMATIC1111
- [10/2022] Demos on Kaggle, Collab and Huggingface Spaces 🤗 are ready!
- [09/2022] Ongoing website and multiple demos creation. Feel free to contact us. Paper will be presented at the Advances in Image Manipulation (AIM) workshop, ECCV 2022, Tel Aviv.

This is the official repository and PyTorch implementation of Swin2SR. We provide the supplementary material, code, pretrained models and demos. Swin2SR represents a possible improvement of the famous SwinIR by Jingyun Liang (kudos for such an amazing contribution ✋). Our model achieves state-of-the-art performance in:
- classical, lighweight and real-world image super-resolution (SR)
- color JPEG compression artifact reduction
- compressed input super-resolution: top solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video" organized by Ren Yang and Radu Timofte
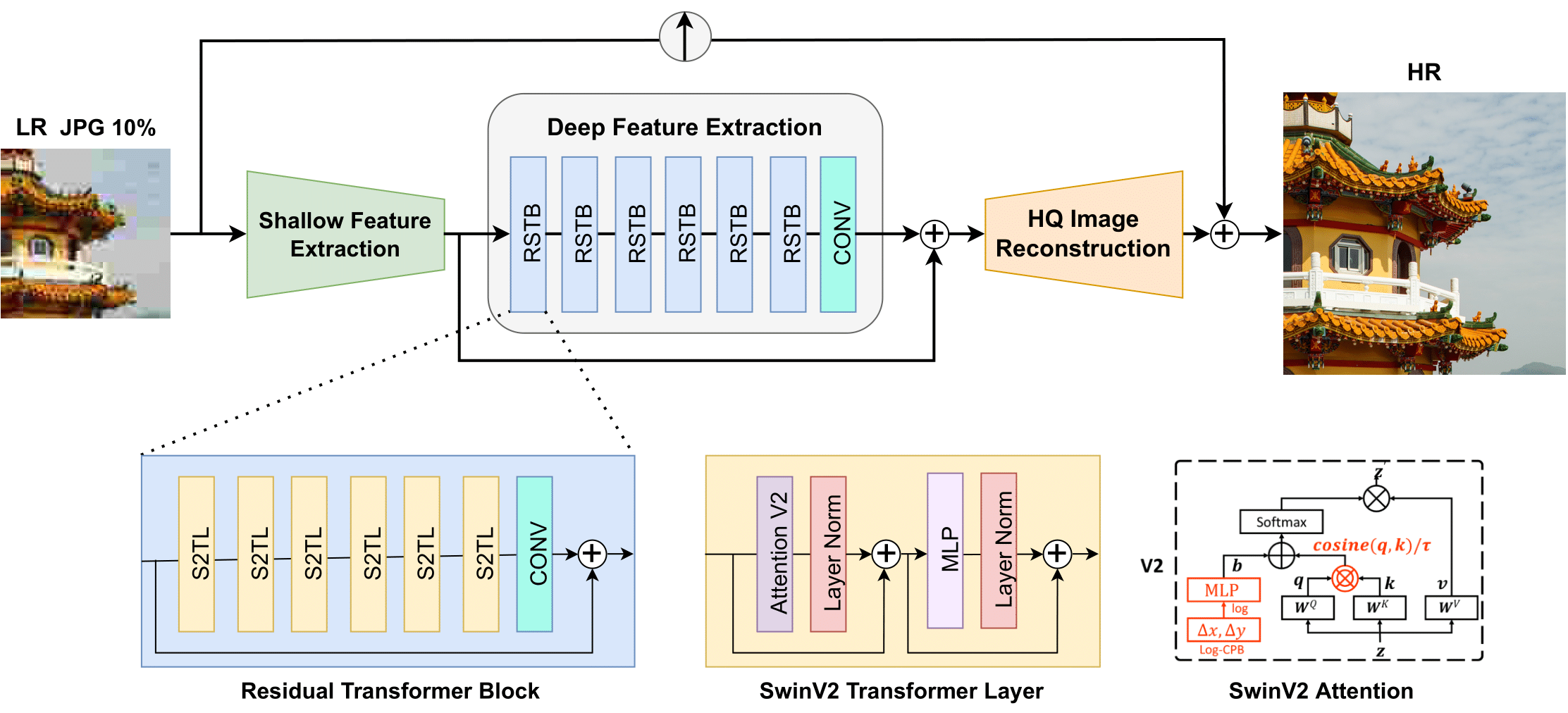
Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks. In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video".
The training code is at KAIR. We follow the same training setup as SwinIR by Jingyun Liang. We are working on KAIR integration 👀 More details about the training setup in our paper.
Why moving to Swin Transformer V2 ??
 Especially in the case of lightweight super-resolution, we noticed how our model convergence was approximately x2 faster using the same experimental setup as SwinIR. We provide the details in the paper Section 3 and 4.2
Especially in the case of lightweight super-resolution, we noticed how our model convergence was approximately x2 faster using the same experimental setup as SwinIR. We provide the details in the paper Section 3 and 4.2
Please check our demos ready to run 🚀
We achieved state-of-the-art performance on classical, lightweight and real-world image Super-Resolution (SR), JPEG compression artifact reduction, and compressed input super-resolution. We use mainly the DIV2K Dataset and Flickr2K datasets for training, and for testing: RealSRSet, 5images/Classic5/Set5, Set14, BSD100, Urban100 and Manga109
🌎 All visual results of Swin2SR can be downloaded here. We also provide links to download the original datasets. More details in our paper.
| Compressed inputs | Swin2SR output |
|---|---|
 |
 |
 |
 |
 |
 |


🌎 All the qualitative samples can be downloaded here
-
create a folder
inputsand put there the input images. The model expects low-quality and low-resolution JPEG compressed images. -
select
--scalestandard is 4, this means we will increase the resolution of the image x4 times. For example for a 1MP image (1000x1000) we will upscale it to near 4K (4000x4000). -
run our model using
main_test_swin2sr.pyand--save_img_only. The pre-trained models are included in our repo, you can download them from here or check the repo releases. It is important to select the proper--task, by default we do compressed input super-resolutioncompressed_s. -
we process the images in
inputs/and the outputs are stored inresults/swin2sr_{TASK}_x{SCALE}where TASK and SCALE are the selected options. You can just navigate throughresults/
python main_test_swin2sr.py --task compressed_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swin2sr/Swin2SR_CompressedSR_X4_48.pth --folder_lq ./inputs --save_img_only
to reproduce results, calculate metrics and further evaluation, please check the following section Testing.
🔥 🚀 ✅ Kaggle kernel demo ready to run! easy to follow includes testing for multiple SR applications.
Clicke here to see how the Kaggle demo looks like

Super-Resolution Demo Swin2SR Official is also available in Google Colab
We also have an interactive demo, no login required! in Huggingface Spaces 🤗 just click and upload images.

We are working on more interactive demos 👀 Contact us if you have ideas!
The original evaluation datasets can be downloaded from the following Kaggle Dataset

Classical image super-resolution (SR) Set5 + Set14 + BSD100 + Urban100 + Manga109 - download here
real-world image SR RealSRSet and 5images- download here
grayscale/color JPEG compression artifact reduction Classic5 +LIVE1 - download here
We follow the same evaluation setup as SwinIR by Jingyun Liang
🚀 You can check this evaluation process (and the followinf points) in our interactive kernel Official Swin2SR Demo Results
python main_test_swin2sr.py --task classical_sr --scale 2 --training_patch_size 64 --model_path model_zoo/swin2sr/Swin2SR_ClassicalSR_X2_64.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
python main_test_swin2sr.py --task classical_sr --scale 4 --training_patch_size 64 --model_path model_zoo/swin2sr/Swin2SR_ClassicalSR_X4_64.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
python main_test_swin2sr.py --task lightweight_sr --scale 2 --training_patch_size 64 --model_path model_zoo/swin2sr/Swin2SR_Lightweight_X2_64.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
python main_test_swin2sr.py --task real_sr --scale 4 --model_path model_zoo/swin2sr/Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR.pth --folder_lq testsets/RealSRSet+5images
python main_test_swin2sr.py --task compressed_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swin2sr/Swin2SR_CompressedSR_X4_48.pth --folder_gt path/to/DIV2K_Valid_HR --folder_lq /path/to/DIV2K_Valid_LR/Compressed_X4
python main_test_swin2sr.py --task jpeg_car --jpeg 10 --model_path model_zoo/swin2sr/Swin2SR_Jpeg_dynamic.pth --folder_gt /path/to/classic5
python main_test_swin2sr.py --task jpeg_car --jpeg 20 --model_path model_zoo/swin2sr/Swin2SR_Jpeg_dynamic.pth --folder_gt /path/to/classic5
python main_test_swin2sr.py --task jpeg_car --jpeg 30 --model_path model_zoo/swin2sr/Swin2SR_Jpeg_dynamic.pth --folder_gt /path/to/classic5
python main_test_swin2sr.py --task jpeg_car --jpeg 40 --model_path model_zoo/swin2sr/Swin2SR_Jpeg_dynamic.pth --folder_gt /path/to/classic5
SwinIR: Image Restoration Using Swin Transformer by Liang et al, ICCVW 2021.
AISP: AI Image Signal Processing by Marcos Conde, Radu Timofte and collaborators, 2022.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video organized by Ren Yang.
Swin Transformer V2: Scaling Up Capacity and Resolution by Liu et al, CVPR 2022.
@inproceedings{conde2022swin2sr,
title={{S}win2{SR}: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration},
author={Conde, Marcos V and Choi, Ui-Jin and Burchi, Maxime and Timofte, Radu},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV) Workshops},
year={2022}
}
@article{liang2021swinir,
title={SwinIR: Image Restoration Using Swin Transformer},
author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
journal={arXiv preprint arXiv:2108.10257},
year={2021}
}
This project is released under the Apache 2.0 license. The codes are heavily based on Swin Transformer and SwinV2 Transformer by Ze Liu. We also refer to codes in KAIR, BasicSR and SwinIR. Please also follow their licenses. Thanks for their awesome works.
Marcos Conde (marcos.conde@uni-wuerzburg.de) and Ui-Jin Choi (choiuijin1125@gmail.com) are the contact persons. Please add in the email subject "swin2sr".