PYDFMerger
A tiny winy PDF merging tool for all and sundry.
Idea
My girlfriend needed a simple PDF merging tool. Unlike macOS Windows does not offer this possibility. So I created PYDFMerger. The idea is to create an executable (or use the one in the Download folder) from this little Python script with e. g. PyInstaller that can run in the folder with the PDF files.
Like so.
How To
- Run the executable or
pydfmerger.pyin the folder the PDFs are located that you want to merge. - Naming conventions: The PDFs need a file name pattern like this:
- Starting with
01_: Files need to start with a number and a underscore. 1. The number is needed to sort the files. So01_will be merged before02_. 1. The underscore tellsPYDFMergerthat the number ends here. More undersocres in the file name are no problem. 1. The number has to be the first information in the file name. Soappendix01_asdf.pdfwon't work. - Page information with
[1-2;3-4]: If you want to tell the merger which pages you want to merge, you can do this with square brackets. 1. Please use these brackets only for page information in the file name. 1.02_bachelorthesis[1-3].pdfwill only merge the pages 1 and 3. 1. If you leave the brackets out (02_bachelorthesis.pdf) the whole document will be merged. - Output: After the tool finished the job you will find a file named
XX_merge.pdfin the folder. If you ran the script again the file will be overwritten. So do not name anything importantXX_merge.pdfand place it in folder of the script. Thank you.
Example
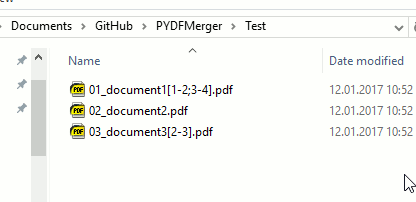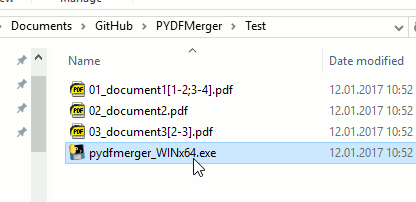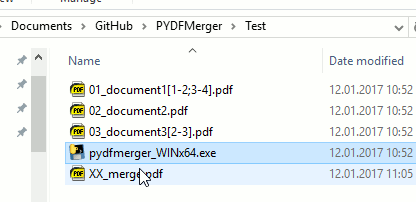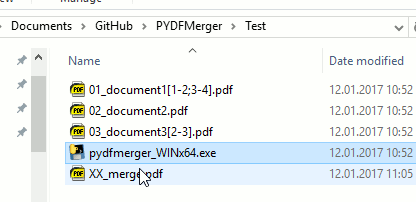
If the script runs in a folder with the three files 01_document1[1-2;3-4].pdf, 02_document2.pdf and 03_document3[2-3].pdf the output file XX_merge.pdf will contain the following:
- Pages 1 to 2 from
01_document1[1-2;3-4].pdf - Pages 3 to 4 from
01_document1[1-2;3-4].pdf - All pages from
02_document2.pdf - Pages 2 to 3 from
03_document3[2-3].pdf
Known Problems
- If the page numbering of the PDF starts with roman numbers I-IV the script won't work properly.
- If there are PDF files that do not match the file name pattern the script will crash.
Executables
- There is a Windows .exe in the
Downloadfolder which runs the script without the need of Python 3.5. It was build on a 64 bit Windows machine. - There is also a Ubuntu/Linux executable build on a 64 bit Ubuntu machine.