![]()
1st solution for AutoDL Challenge@NeurIPS, competition rules can be found at AutoDL Competition.
Generic algorithms for multi-label classification problems in different modalities: image, video, speech, text and tabular data.
Automated deep learning without any human intervention:
-
Generic algorithms for multi-label classification problems in different modalities: image, video, speech, text and tabular data.
-
Feedback-phase leaderboard
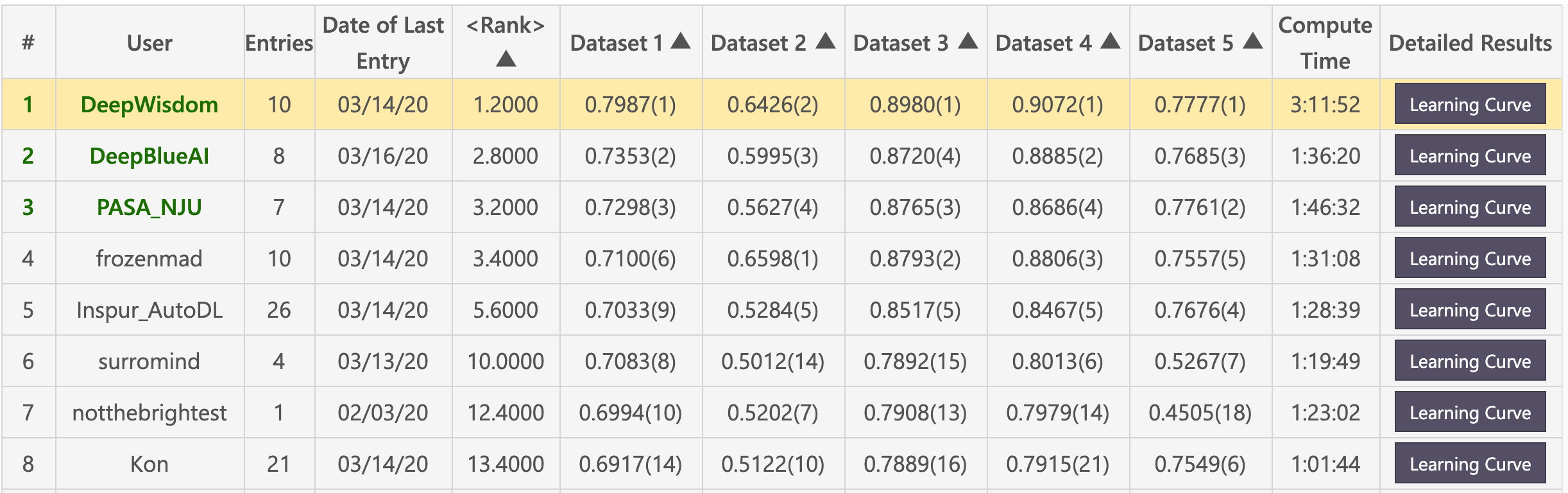
-
Final-phase leaderboard visualization
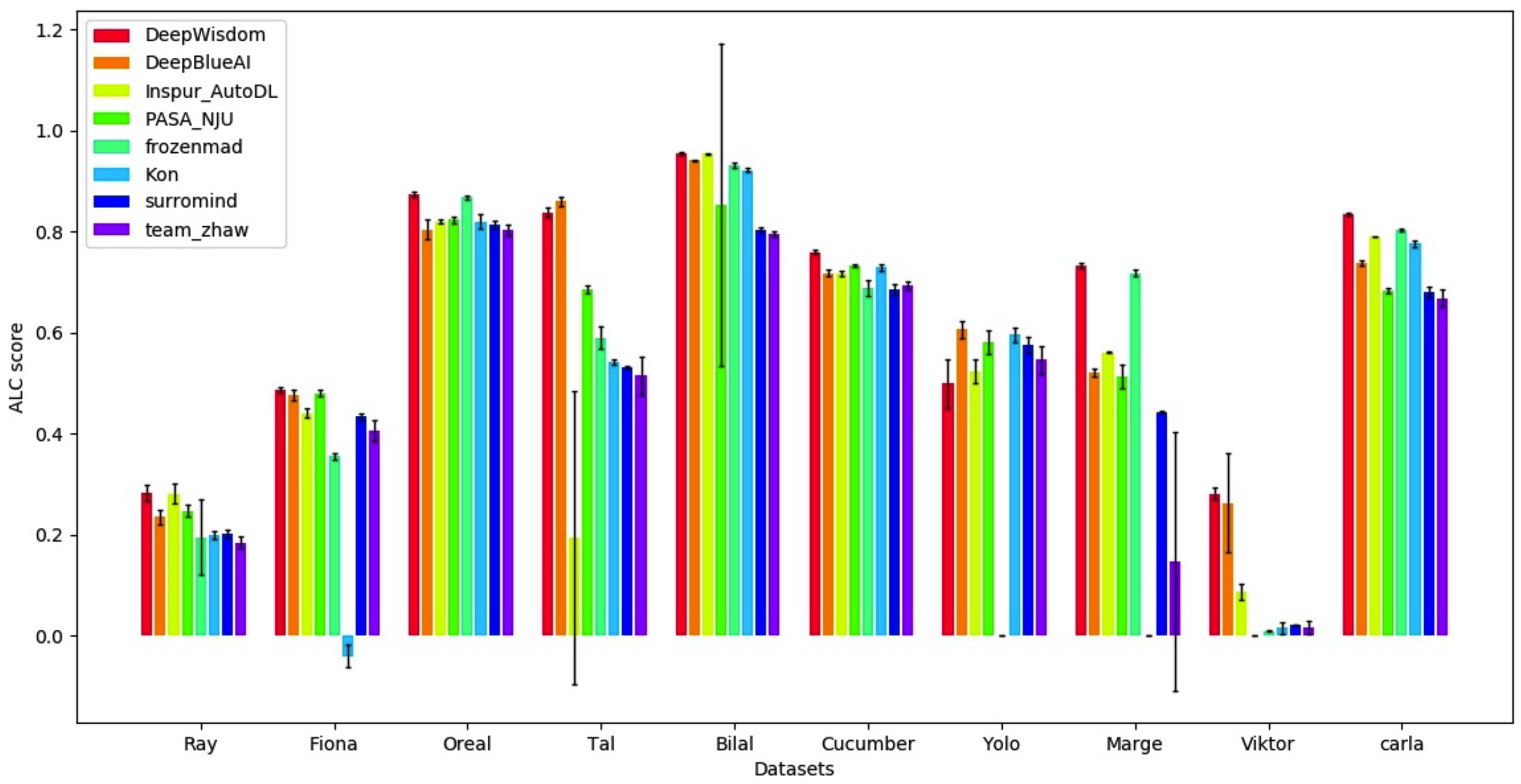


python download_public_datasets.py| # | Name | Type | Domain | Size | Source | Data (w/o test labels) | Test labels |
|---|---|---|---|---|---|---|---|
| 1 | Munster | Image | HWR | 18 MB | MNIST | munster.data | munster.solution |
| 2 | City | Image | Objects | 128 MB | Cifar-10 | city.data | city.solution |
| 3 | Chucky | Image | Objects | 128 MB | Cifar-100 | chucky.data | chucky.solution |
| 4 | Pedro | Image | People | 377 MB | PA-100K | pedro.data | pedro.solution |
| 5 | Decal | Image | Aerial | 73 MB | NWPU VHR-10 | decal.data | decal.solution |
| 6 | Hammer | Image | Medical | 111 MB | Ham10000 | hammer.data | hammer.solution |
| 7 | Kreatur | Video | Action | 469 MB | KTH | kreatur.data | kreatur.solution |
| 8 | Kreatur3 | Video | Action | 588 MB | KTH | kreatur3.data | kreatur3.solution |
| 9 | Kraut | Video | Action | 1.9 GB | KTH | kraut.data | kraut.solution |
| 10 | Katze | Video | Action | 1.9 GB | KTH | katze.data | katze.solution |
| 11 | data01 | Speech | Speaker | 1.8 GB | -- | data01.data | data01.solution |
| 12 | data02 | Speech | Emotion | 53 MB | -- | data02.data | data02.solution |
| 13 | data03 | Speech | Accent | 1.8 GB | -- | data03.data | data03.solution |
| 14 | data04 | Speech | Genre | 469 MB | -- | data04.data | data04.solution |
| 15 | data05 | Speech | Language | 208 MB | -- | data05.data | data05.solution |
| 16 | O1 | Text | Comments | 828 KB | -- | O1.data | O1.solution |
| 17 | O2 | Text | Emotion | 25 MB | -- | O2.data | O2.solution |
| 18 | O3 | Text | News | 88 MB | -- | O3.data | O3.solution |
| 19 | O4 | Text | Spam | 87 MB | -- | O4.data | O4.solution |
| 20 | O5 | Text | News | 14 MB | -- | O5.data | O5.solution |
| 21 | Adult | Tabular | Census | 2 MB | Adult | adult.data | adult.solution |
| 22 | Dilbert | Tabular | -- | 162 MB | -- | dilbert.data | dilbert.solution |
| 23 | Digits | Tabular | HWR | 137 MB | MNIST | digits.data | digits.solution |
| 24 | Madeline | Tabular | -- | 2.6 MB | -- | madeline.data | madeline.solution |
- Git clone the repo
cd <path_to_your_directory>
git clone https://github.com/DeepWisdom/AutoDL.git
-
Prepare pretrained models. Download model speech_model.h5 and put it to
AutoDL_sample_code_submission/at_speech/pretrained_models/directory. -
Optional: run in the exact same environment as on the challenge platform with docker.
- CPU
cd path/to/autodl/ docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:cpu-latest- GPU
nvidia-docker run -it -v "$(pwd):/app/codalab" -p 8888:8888 evariste/autodl:gpu-latest -
Prepare sample datasets, using the toy data in
AutoDL_sample_dataor download new datasets. -
Run local test
python run_local_test.py
The full usage is
python run_local_test.py -dataset_dir='AutoDL_sample_data/miniciao' -code_dir='AutoDL_sample_code_submission'
Then you can view the real-time feedback with a learning curve by opening the
HTML page in AutoDL_scoring_output/.
Details can be seen in AutoDL Challenge official starting_kit.
Feel free to dive in! Open an issue or submit PRs.
![]()