Este projeto foi desenvolvido como parte da conclusão da disciplina de Técnicas de Programação 1 do curso de Engenharia de Dados da Ada Tech em parceria com o Santander Coders. O objetivo é criar um módulo de Data Quality utilizando Programação Orientada a Objetos (POO), que será importado em um Jupyter Notebook para gerar relatórios de análise de datasets.
O módulo desenvolvido permitirá realizar análises de qualidade em qualquer conjunto de dados (dataset) apenas em csv e excel a princípio. As principais funcionalidades incluem:
- Contagem de Nulos: Identificação e contagem de valores nulos em cada coluna do dataset.
- Contagem de Valores Únicos: Cálculo da quantidade de valores únicos presentes em cada coluna.
- Análise de Colunas Categóricas: Geração de
value_countspara colunas categóricas, proporcionando uma visão clara da distribuição de categorias. - Estatísticas Descritivas: Uso do método
describe()nas colunas numéricas para fornecer estatísticas como média, mediana, mínimo e máximo. - Visualizações:
- Gráficos de distribuição para colunas categóricas, permitindo a visualização da frequência de cada categoria.
- Gráficos de distribuição para colunas numéricas, oferecendo insights sobre a dispersão e a forma dos dados.
Abaixo está a estrutura de arquivos do projeto:
├── .gitignore
├── data_quality.py
├── notebook.ipynb
├── input
-
Clone o repositório:
git clone https://github.com/naiieandrade/DataQuality.git
-
Instale as dependências: Certifique-se de ter o Python e o Jupyter Notebook instalados. Você pode instalar as dependências necessárias usando:
pip install -r requirements.txt
-
Execute o Jupyter Notebook: Navegue até o diretório do projeto e inicie o Jupyter Notebook:
jupyter notebook notebook.ipynb
-
Recomenda-se o uso de ambiente virtual (venv, conda ou docker):
git clone https://github.com/naiieandrade/DataQuality.git
-
Instale as dependências: Certifique-se de ter o Python e o Jupyter Notebook instalados. Você pode instalar as dependências necessárias usando:
pip install -r requirements.txt
-
Execute o Streamlit: Navegue até o diretório do projeto e inicie o streamlit e clique no link que ele mostrar que irá abrir no navegador:
streamlit run data_streamlit.py
-
Abra o arquivo CSV: A tela fica igual a imagem mostrada. Clique no botão "Browser files" e adicione o arquivo csv.
-
Relatório de Qualidade: Será mostrado o relatório sobre os dados, como mostra a imagem.
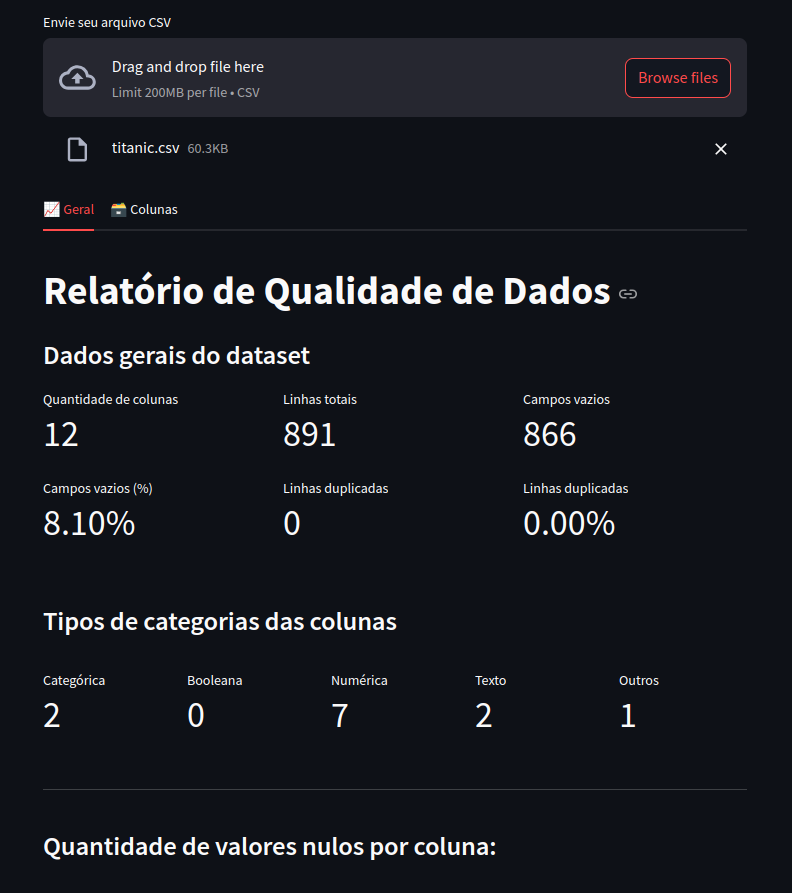


Contribuições são bem-vindas! Se você deseja contribuir, sinta-se à vontade para abrir uma issue ou enviar um pull request.
Este projeto está licenciado sob a MIT License.