Karl Pertsch1, Youngwoon Lee1, Joseph Lim1
1CLVR Lab, University of Southern California
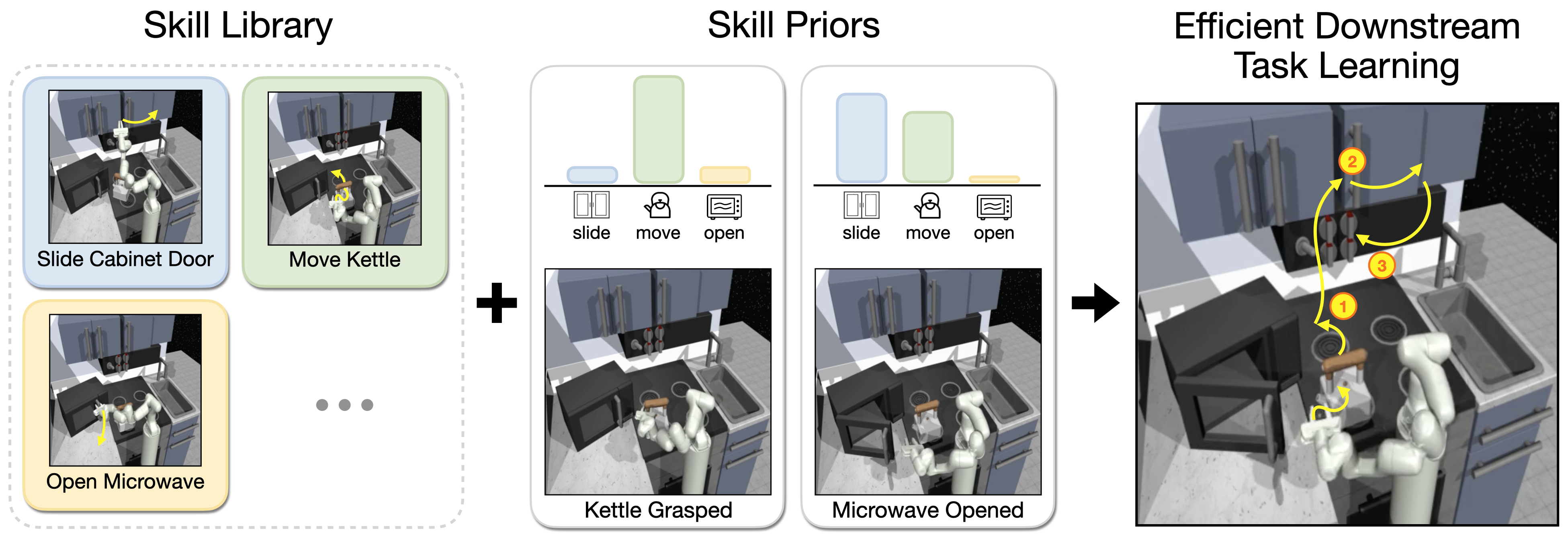
This is the official PyTorch implementation of the paper "Accelerating Reinforcement Learning with Learned Skill Priors" (CoRL 2020).
- [Apr 2021]: extended improved SPiRL version to support image-based observations (see example commands)
- [Mar 2021]: added an improved version of SPiRL with closed-loop skill decoder (see example commands)
- python 3.7+
- mujoco 2.0 (for RL experiments)
- Ubuntu 18.04
Create a virtual environment and install all required packages.
cd spirl
pip3 install virtualenv
virtualenv -p $(which python3) ./venv
source ./venv/bin/activate
# Install dependencies and package
pip3 install -r requirements.txt
pip3 install -e .
Set the environment variables that specify the root experiment and data directories. For example:
mkdir ./experiments
mkdir ./data
export EXP_DIR=./experiments
export DATA_DIR=./data
Finally, install our fork of the D4RL benchmark repository by following its installation instructions. It will provide both, the kitchen environment as well as the training data for the skill prior model in kitchen and maze environment.
To train a skill prior model for the kitchen environment, run:
python3 spirl/train.py --path=spirl/configs/skill_prior_learning/kitchen/hierarchical --val_data_size=160
Results can be visualized using tensorboard in the experiment directory: tensorboard --logdir=$EXP_DIR.
For training a SPIRL agent on the kitchen environment using the pre-trained skill prior from above, run:
python3 spirl/rl/train.py --path=spirl/configs/hrl/kitchen/spirl --seed=0 --prefix=SPIRL_kitchen_seed0
Results will be written to WandB. Before running RL, create an account and then change the WandB entity and project name at the top of rl/train.py to match your account.
In both commands, kitchen can be replaced with maze / block_stacking to run on the respective environment. Before training models
on these environments, the corresponding datasets need to be downloaded (the kitchen dataset gets downloaded automatically)
-- download links are provided below.
Additional commands for training baseline models / agents are also provided below.
- Train Single-step action prior:
python3 spirl/train.py --path=spirl/configs/skill_prior_learning/kitchen/flat --val_data_size=160
- Run Vanilla SAC:
python3 spirl/rl/train.py --path=spirl/configs/rl/kitchen/SAC --seed=0 --prefix=SAC_kitchen_seed0
- Run SAC w/ single-step action prior:
python3 spirl/rl/train.py --path=spirl/configs/rl/kitchen/prior_initialized/flat_prior/ --seed=0 --prefix=flatPrior_kitchen_seed0
- Run BC + finetune:
python3 spirl/rl/train.py --path=spirl/configs/rl/kitchen/prior_initialized/bc_finetune/ --seed=0 --prefix=bcFinetune_kitchen_seed0
- Run Skill Space Policy w/o prior:
python3 spirl/rl/train.py --path=spirl/configs/hrl/kitchen/no_prior/ --seed=0 --prefix=SSP_noPrior_kitchen_seed0
Again, all commands can be run on maze / block stacking by replacing kitchen with the respective environment in the paths
(after downloading the datasets).
The default hyperparameters are defined in the respective model files, e.g. in skill_prior_mdl.py
for the SPIRL model. Modifications to these parameters can be defined through the experiment config files (passed to the respective
command via the --path variable). For an example, see kitchen/hierarchical/conf.py.
All code that is dataset-specific should be placed in a corresponding subfolder in spirl/data.
To add a data loader for a new dataset, the Dataset classes from data_loader.py need to be subclassed
and the __getitem__ function needs to be overwritten to load a single data sample. The output dict should include the following
keys:
dict({
'states': (time, state_dim) # state sequence (for state-based prior inputs)
'actions': (time, action_dim) # action sequence (as skill input for training prior model)
'images': (time, channels, width, height) # image sequence (for image-based prior inputs)
})
All datasets used with the codebase so far have been based on HDF5 files. The GlobalSplitDataset provides functionality to read all
HDF5-files in a directory and split them in train/val/test based on percentages. The VideoDataset class provides
many functionalities for manipulating sequences, like randomly cropping subsequences, padding etc.
To add a new RL environment, simply define a new environent class in spirl/rl/envs that inherits from the environment interface
in spirl/rl/components/environment.py.
Start by defining a model class in the spirl/models directory that inherits from the BaseModel or SkillPriorMdl class.
The new model needs to define the architecture in the constructor (e.g. by overwriting the build_network() function),
implement the forward pass and loss functions,
as well as model-specific logging functionality if desired. For an example, see spirl/models/skill_prior_mdl.py.
Note, that most basic architecture components (MLPs, CNNs, LSTMs, Flow models etc) are defined in spirl/modules and can be
conveniently reused for easy architecture definitions. Below are some links to the most important classes.
| Component | File | Description |
|---|---|---|
| MLP | Predictor |
Basic N-layer fully-connected network. Defines number of inputs, outputs, layers and hidden units. |
| CNN-Encoder | ConvEncoder |
Convolutional encoder, number of layers determined by input dimensionality (resolution halved per layer). Number of channels doubles per layer. Returns encoded vector + skip activations. |
| CNN-Decoder | ConvDecoder |
Mirrors architecture of conv. encoder. Can take skip connections as input, also versions that copy pixels etc. |
| Processing-LSTM | BaseProcessingLSTM |
Basic N-layer LSTM for processing an input sequence. Produces one output per timestep, number of layers / hidden size configurable. |
| Prediction-LSTM | RecurrentPredictor |
Same as processing LSTM, but for autoregressive prediction. |
| Mixture-Density Network | MDN |
MLP that outputs GMM distribution. |
| Normalizing Flow Model | NormalizingFlowModel |
Implements normalizing flow model that stacks multiple flow blocks. Implementation for RealNVP block provided. |
The core RL algorithms are implemented within the Agent class. For adding a new algorithm, a new file needs to be created in
spirl/rl/agents and BaseAgent needs to be subclassed. In particular, any required
networks (actor, critic etc) need to be constructed and the update(...) function needs to be overwritten. For an example,
see the SAC implementation in SACAgent.
The main SPIRL skill prior regularized RL algorithm is implemented in ActionPriorSACAgent.
spirl
|- components # reusable infrastructure for model training
| |- base_model.py # basic model class that all models inherit from
| |- checkpointer.py # handles storing + loading of model checkpoints
| |- data_loader.py # basic dataset classes, new datasets need to inherit from here
| |- evaluator.py # defines basic evaluation routines, eg top-of-N evaluation, + eval logging
| |- logger.py # implements core logging functionality using tensorboardX
| |- params.py # definition of command line params for model training
| |- trainer_base.py # basic training utils used in main trainer file
|
|- configs # all experiment configs should be placed here
| |- data_collect # configs for data collection runs
| |- default_data_configs # defines one default data config per dataset, e.g. state/action dim etc
| |- hrl # configs for hierarchical downstream RL
| |- rl # configs for non-hierarchical downstream RL
| |- skill_prior_learning # configs for skill embedding and prior training (both hierarchical and flat)
|
|- data # any dataset-specific code (like data generation scripts, custom loaders etc)
|- models # holds all model classes that implement forward, loss, visualization
|- modules # reusable architecture components (like MLPs, CNNs, LSTMs, Flows etc)
|- rl # all code related to RL
| |- agents # implements core algorithms in agent classes, like SAC etc
| |- components # reusable infrastructure for RL experiments
| |- agent.py # basic agent and hierarchial agent classes - do not implement any specific RL algo
| |- critic.py # basic critic implementations (eg MLP-based critic)
| |- environment.py # defines environment interface, basic gym env
| |- normalization.py # observation normalization classes, only optional
| |- params.py # definition of command line params for RL training
| |- policy.py # basic policy interface definition
| |- replay_buffer.py # simple numpy-array replay buffer, uniform sampling and versions
| |- sampler.py # rollout sampler for collecting experience, for flat and hierarchical agents
| |- envs # all custom RL environments should be defined here
| |- policies # policy implementations go here, MLP-policy and RandomAction are implemented
| |- utils # utilities for RL code like MPI, WandB related code
| |- train.py # main RL training script, builds all components + runs training
|
|- utils # general utilities, pytorch / visualization utilities etc
|- train.py # main model training script, builds all components + runs training loop and logging
The general philosophy is that each new experiment gets a new config file that captures all hyperparameters etc. so that experiments themselves are version controllable.
| Dataset | Link | Size |
|---|---|---|
| Maze | https://drive.google.com/file/d/1pXM-EDCwFrfgUjxITBsR48FqW9gMoXYZ/view?usp=sharing | 12GB |
| Block Stacking | https://drive.google.com/file/d/1VobNYJQw_Uwax0kbFG7KOXTgv6ja2s1M/view?usp=sharing | 11GB |
You can download the datasets used for the experiments in the paper with the links above. To download the data via the command line, see example commands here.
If you want to generate more data
or make other modifications to the data generating procedure, we provide instructions for regenerating the
maze and block stacking datasets here.
If you find this work useful in your research, please consider citing:
@inproceedings{pertsch2020spirl,
title={Accelerating Reinforcement Learning with Learned Skill Priors},
author={Karl Pertsch and Youngwoon Lee and Joseph J. Lim},
booktitle={Conference on Robot Learning (CoRL)},
year={2020},
}
The model architecture and training code builds on a code base which we jointly developed with Oleh Rybkin for our previous project on hierarchial prediction.
We also published many of the utils / architectural building blocks in a stand-alone package for easy import into your own research projects: check out the blox python module.