🤗 Models & Datasets | 📖 Blog | 📃 Paper
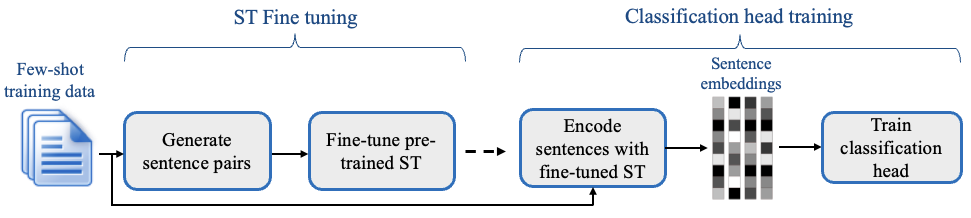
SetFit is an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers. It achieves high accuracy with little labeled data - for instance, with only 8 labeled examples per class on the Customer Reviews sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯!
Compared to other few-shot learning methods, SetFit has several unique features:
- 🗣 No prompts or verbalisers: Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that's suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
- 🏎 Fast to train: SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with.
- 🌎 Multilingual support: SetFit can be used with any Sentence Transformer on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint.
Download and install setfit by running:
python -m pip install setfitIf you want the bleeding-edge version, install from source by running:
python -m pip install git+https://github.com/huggingface/setfit.gitThe examples below provide a quick overview on the various features supported in setfit. For more examples, check out the notebooks folder.
setfit is integrated with the Hugging Face Hub and provides two main classes:
SetFitModel: a wrapper that combines a pretrained body fromsentence_transformersand a classification head from eitherscikit-learnorSetFitHead(a differentiable head built uponPyTorchwith similar APIs tosentence_transformers).SetFitTrainer: a helper class that wraps the fine-tuning process of SetFit.
Here is an end-to-end example using a classification head from scikit-learn:
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer, sample_dataset
# Load a dataset from the Hugging Face Hub
dataset = load_dataset("sst2")
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
eval_dataset = dataset["validation"]
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for constrastive learning
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate()
# Push model to the Hub
trainer.push_to_hub("my-awesome-setfit-model")
# Download from Hub and run inference
model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"]) Here is an end-to-end example using SetFitHead:
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
# Load a dataset from the Hugging Face Hub
dataset = load_dataset("sst2")
# Simulate the few-shot regime by sampling 8 examples per class
num_classes = 2
train_dataset = dataset["train"].shuffle(seed=42).select(range(8 * num_classes))
eval_dataset = dataset["validation"]
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-mpnet-base-v2",
use_differentiable_head=True,
head_params={"out_features": num_classes},
)
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=16,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for constrastive learning
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
# Train and evaluate
trainer.freeze() # Freeze the head
trainer.train() # Train only the body
# Unfreeze the head and freeze the body -> head-only training
trainer.unfreeze(keep_body_frozen=True)
# or
# Unfreeze the head and unfreeze the body -> end-to-end training
trainer.unfreeze(keep_body_frozen=False)
trainer.train(
num_epochs=25, # The number of epochs to train the head or the whole model (body and head)
batch_size=16,
body_learning_rate=1e-5, # The body's learning rate
learning_rate=1e-2, # The head's learning rate
l2_weight=0.0, # Weight decay on **both** the body and head. If `None`, will use 0.01.
)
metrics = trainer.evaluate()
# Push model to the Hub
trainer.push_to_hub("my-awesome-setfit-model")
# Download from Hub and run inference
model = SetFitModel.from_pretrained("lewtun/my-awesome-setfit-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"]) Based on our experiments, SetFitHead can achieve similar performance as using a scikit-learn head. We use AdamW as the optimizer and scale down learning rates by 0.5 every 5 epochs. For more details about the experiments, please check out here. We recommend using a large learning rate (e.g. 1e-2) for SetFitHead and a small learning rate (e.g. 1e-5) for the body in your first attempt.
To train SetFit models on multilabel datasets, specify the multi_target_strategy argument when loading the pretrained model:
from setfit import SetFitModel
model = SetFitModel.from_pretrained(model_id, multi_target_strategy="one-vs-rest")This will initialise a multilabel classification head from sklearn - the following options are available for multi_target_strategy:
one-vs-rest: use aOneVsRestClassifierhead.multi-output: use aMultiOutputClassifierhead.classifier-chain: use aClassifierChainhead.
From here, you can instantiate a SetFitTrainer using the same example above, and train it as usual.
Note: If you use the differentiable head, it will automatically use softmax with argmax when num_classes is greater than 1.
SetFit can also be applied to scenarios where no labels are available. To do so, create a synthetic dataset of training examples:
from datasets import Dataset
from setfit import add_templated_examples
candidate_labels = ["negative", "positive"]
dummy_dataset = Dataset.from_dict({})
train_dataset = add_templated_examples(dummy_dataset, candidate_labels=candidate_labels, sample_size=8)This will create examples of the form "This sentence is {}", where the {} is filled in with one of the candidate labels. From here you can train a SetFit model as usual:
from setfit import SetFitModel, SetFitTrainer
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset
)
trainer.train()We find this approach typically outperforms the zero-shot pipeline in 🤗 Transformers (based on MNLI with Bart), while being 5x faster to generate predictions with.
SetFitTrainer provides a hyperparameter_search() method that you can use to find good hyperparameters for your data. To use this feature, first install the optuna backend:
python -m pip install setfit[optuna]To use this method, you need to define two functions:
model_init(): A function that instantiates the model to be used. If provided, each call totrain()will start from a new instance of the model as given by this function.hp_space(): A function that defines the hyperparameter search space.
Here is an example of a model_init() function that we'll use to scan over the hyperparameters associated with the classification head in SetFitModel:
from setfit import SetFitModel
def model_init(params):
params = params or {}
max_iter = params.get("max_iter", 100)
solver = params.get("solver", "liblinear")
params = {
"head_params": {
"max_iter": max_iter,
"solver": solver,
}
}
return SetFitModel.from_pretrained("sentence-transformers/paraphrase-albert-small-v2", **params)Similarly, to scan over hyperparameters associated with the SetFit training process, we can define a hp_space() function as follows:
def hp_space(trial): # Training parameters
return {
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
"num_epochs": trial.suggest_int("num_epochs", 1, 5),
"batch_size": trial.suggest_categorical("batch_size", [4, 8, 16, 32, 64]),
"seed": trial.suggest_int("seed", 1, 40),
"num_iterations": trial.suggest_categorical("num_iterations", [5, 10, 20]),
"max_iter": trial.suggest_int("max_iter", 50, 300),
"solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
}Note: In practice, we found num_iterations to be the most important hyperparameter for the contrastive learning process.
The next step is to instantiate a SetFitTrainer and call hyperparameter_search():
from datasets import Dataset
from setfit import SetFitTrainer
dataset = Dataset.from_dict(
{"text_new": ["a", "b", "c"], "label_new": [0, 1, 2], "extra_column": ["d", "e", "f"]}
)
trainer = SetFitTrainer(
train_dataset=dataset,
eval_dataset=dataset,
model_init=model_init,
column_mapping={"text_new": "text", "label_new": "label"},
)
best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=20)Finally, you can apply the hyperparameters you found to the trainer, and lock in the optimal model, before training for a final time.
trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
trainer.train()We provide scripts to reproduce the results for SetFit and various baselines presented in Table 2 of our paper. Check out the setup and training instructions in the scripts/ directory.
To run the code in this project, first create a Python virtual environment using e.g. Conda:
conda create -n setfit python=3.9 && conda activate setfitThen install the base requirements with:
python -m pip install -e '.[dev]'This will install datasets and packages like black and isort that we use to ensure consistent code formatting.
We use black and isort to ensure consistent code formatting. After following the installation steps, you can check your code locally by running:
make style && make quality
├── LICENSE
├── Makefile <- Makefile with commands like `make style` or `make tests`
├── README.md <- The top-level README for developers using this project.
├── notebooks <- Jupyter notebooks.
├── final_results <- Model predictions from the paper
├── scripts <- Scripts for training and inference
├── setup.cfg <- Configuration file to define package metadata
├── setup.py <- Make this project pip installable with `pip install -e`
├── src <- Source code for SetFit
└── tests <- Unit tests
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}}