


Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g., BERT) to support topic modeling. See the papers for details:
- Bianchi, F., Terragni, S., & Hovy, D. (2021). Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence. ACL. https://aclanthology.org/2021.acl-short.96/
- Bianchi, F., Terragni, S., Hovy, D., Nozza, D., & Fersini, E. (2021). Cross-lingual Contextualized Topic Models with Zero-shot Learning. EACL. https://www.aclweb.org/anthology/2021.eacl-main.143/
![]()
Table of Contents
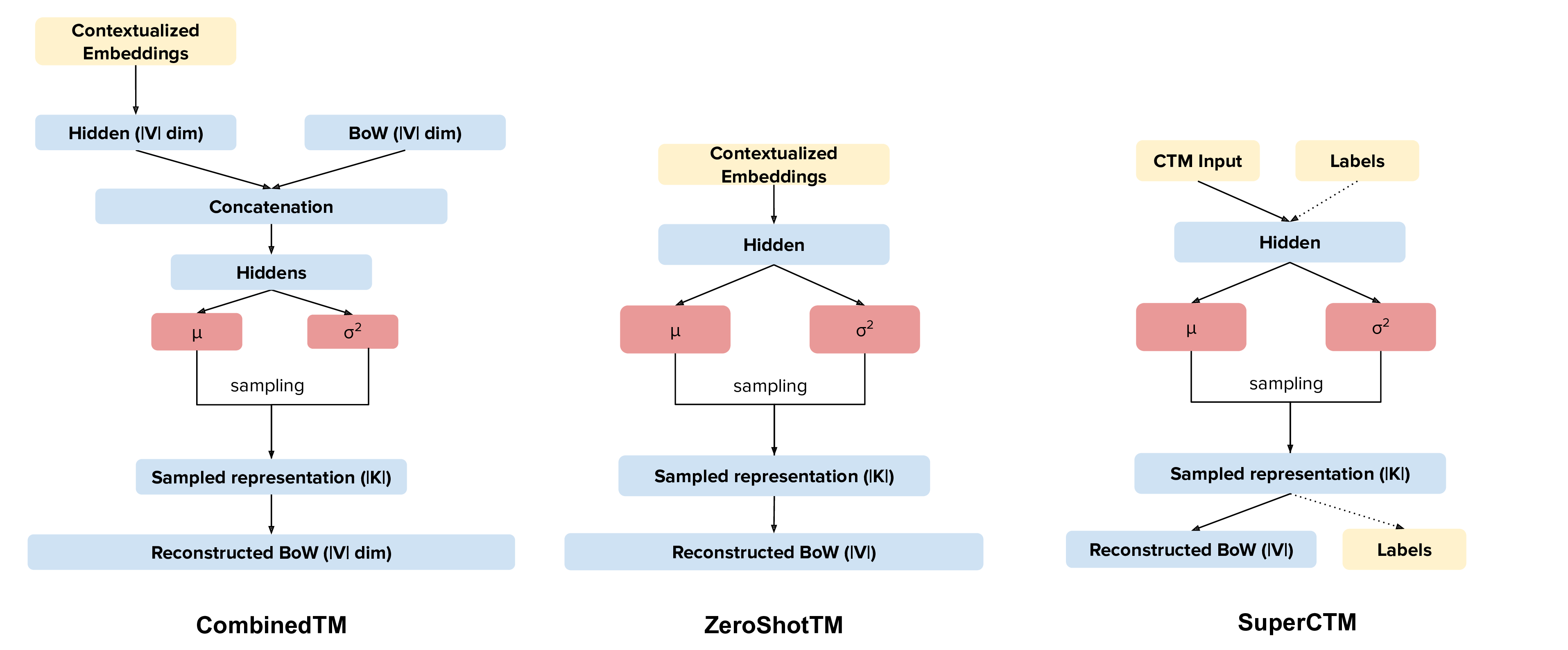
Our new topic modeling family supports many different languages (i.e., the one supported by HuggingFace models) and comes in two versions: CombinedTM combines contextual embeddings with the good old bag of words to make more coherent topics; ZeroShotTM is the perfect topic model for task in which you might have missing words in the test data and also, if trained with muliglingual embeddings, inherits the property of being a multilingual topic model!
CombinedTM has been accepted at ACL2021 and ZeroShotTM has been accepted at EACL2021!
If you want to replicate our results, you can use our code. You will find the W1 dataset in the colab and here: https://github.com/vinid/data, if you need the W2 dataset, send us an email (it is a bit bigger than W1 and we could not upload it on github).
Note: Thanks to Camille DeJarnett (Stanford/CMU), Xinyi Wang (CMU), and Graham Neubig (CMU) we found out that with the current version of the package and all the dependencies (e.g., the sentence transformers embedding model, CUDA version, PyTorch version), results with the model distiluse-base-multilingual-cased are lower than what appears in the paper. We suggest to use paraphrase-multilingual-mpnet-base-v2 which is a newer multilingual model that has results that are higher than those in the paper.
See for example the results on the matches metric for Italian in the following table.
| Model Name | Matches |
|---|---|
| paraphrase-multilingual-mpnet-base-v2 | 0.67 |
| distiluse-base-multilingual-cased | 0.57 |
| paper | 0.62 |
Thus, if you use ZeroShotTM for a multilingual task, we suggest the use of paraphrase-multilingual-mpnet-base-v2.
You can look at our medium blog post or start from one of our Colab Tutorials:
| Name | Link |
|---|---|
| Combined TM on Wikipedia Data (Preproc+Saving+Viz) (stable v2.0.0) | |
| Zero-Shot Cross-lingual Topic Modeling (Preproc+Viz) (stable v2.0.0) | |
| SuperCTM and β-CTM (High-level usage) (stable v2.1.0) |
- In CTMs we have two models. CombinedTM and ZeroShotTM, which have different use cases.
- CTMs work better when the size of the bag of words has been restricted to a number of terms that does not go over 2000 elements. This is because we have a neural model that reconstructs the input bag of word, Moreover, in CombinedTM we project the contextualized embedding to the vocab space, the bigger the vocab the more parameters you get, with the training being more difficult and prone to bad fitting. This is NOT a strict limit, however, consider preprocessing your dataset. We have a preprocessing pipeline that can help you in dealing with this.
- Check the contextual model you are using, the multilingual model one used on English data might not give results that are as good as the pure English trained one.
- Preprocessing is key. If you give a contextual model like BERT preprocessed text, it might be difficult to get out a good representation. What we usually do is use the preprocessed text for the bag of word creating and use the NOT preprocessed text for BERT embeddings. Our preprocessing class can take care of this for you.
Important: If you want to use CUDA you need to install the correct version of the CUDA systems that matches your distribution, see pytorch.
Install the package using pip
pip install -U contextualized_topic_modelsAn important aspect to take into account is which network you want to use: the one that combines BERT and the BoW or the one that just uses BERT. It's easy to swap from one to the other:
ZeroShotTM:
ZeroShotTM(bow_size=len(qt.vocab), contextual_size=embedding_dimension, n_components=number_of_topics)CombinedTM:
CombinedTM(bow_size=len(qt.vocab), contextual_size=embedding_dimension, n_components=number_of_topics)But remember that you can do zero-shot cross-lingual topic modeling only with the ZeroShotTM model. See cross-lingual-topic-modeling
If you find this useful you can cite the following papers :)
ZeroShotTM
@inproceedings{bianchi-etal-2021-cross,
title = "Cross-lingual Contextualized Topic Models with Zero-shot Learning",
author = "Bianchi, Federico and Terragni, Silvia and Hovy, Dirk and
Nozza, Debora and Fersini, Elisabetta",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.eacl-main.143",
pages = "1676--1683",
}
CombinedTM
@inproceedings{bianchi-etal-2021-pre,
title = "Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence",
author = "Bianchi, Federico and
Terragni, Silvia and
Hovy, Dirk",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.96",
doi = "10.18653/v1/2021.acl-short.96",
pages = "759--766",
}
Some of the examples below use a multilingual embedding model paraphrase-multilingual-mpnet-base-v2. This means that the representations you are going to use are mutlilinguals. However you might need a broader coverage of languages. In that case, you can check SBERT to find a model you can use.
If you are doing topic modeling in English, you SHOULD use an English sentence-bert model, for example paraphrase-distilroberta-base-v2. In that case, it's really easy to update the code to support monolingual English topic modeling. If you need other models you can check SBERT for other models.
qt = TopicModelDataPreparation("paraphrase-distilroberta-base-v2")In general, our package should be able to support all the models described in the sentence transformer package and in HuggingFace. You need to take a look at HuggingFace models and find which is the one for your language. For example, for Italian, you can use UmBERTo. How to use this in the model, you ask? well, just use the name of the model you want instead of the english/multilingual one:
qt = TopicModelDataPreparation("Musixmatch/umberto-commoncrawl-cased-v1")Here is how you can use the CombinedTM. This is a standard topic model that also uses contextualized embeddings. The good thing about CombinedTM is that it makes your topic much more coherent (see the paper https://arxiv.org/abs/2004.03974).
from contextualized_topic_models.models.ctm import CombinedTM
from contextualized_topic_models.utils.data_preparation import TopicModelDataPreparation
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
qt = TopicModelDataPreparation("paraphrase-distilroberta-base-v2")
training_dataset = qt.fit(text_for_contextual=list_of_unpreprocessed_documents, text_for_bow=list_of_preprocessed_documents)
ctm = CombinedTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics()Advanced Notes: Combined TM combines the BoW with SBERT, a process that seems to increase the coherence of the predicted topics (https://arxiv.org/pdf/2004.03974.pdf).
Our ZeroShotTM can be used for zero-shot topic modeling. It can handle words that are not used during the training phase. More interestingly, this model can be used for cross-lingual topic modeling (See next sections)! See the paper (https://www.aclweb.org/anthology/2021.eacl-main.143)
from contextualized_topic_models.models.ctm import ZeroShotTM
from contextualized_topic_models.utils.data_preparation import TopicModelDataPreparation
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
text_for_contextual = [
"hello, this is unpreprocessed text you can give to the model",
"have fun with our topic model",
]
text_for_bow = [
"hello unpreprocessed give model",
"fun topic model",
]
qt = TopicModelDataPreparation("paraphrase-multilingual-mpnet-base-v2")
training_dataset = qt.fit(text_for_contextual=text_for_contextual, text_for_bow=text_for_bow)
ctm = ZeroShotTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics(2)As you can see, the high-level API to handle the text is pretty easy to use; text_for_bert should be used to pass to the model a list of documents that are not preprocessed. Instead, to text_for_bow you should pass the preprocessed text used to build the BoW.
Advanced Notes: in this way, SBERT can use all the information in the text to generate the representations.
Once the model is trained, it is very easy to get the topics!
ctm.get_topics()The transform method will take care of most things for you, for example the generation of a corresponding BoW by considering only the words that the model has seen in training. However, this comes with some bumps when dealing with the ZeroShotTM, as we will se in the next section.
You can, however, manually load the embeddings if you like (see the Advanced part of this documentation).
If you use CombinedTM you need to include the test text for the BOW:
testing_dataset = qt.transform(text_for_contextual=testing_text_for_contextual, text_for_bow=testing_text_for_bow)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentIf you use ZeroShotTM you do not need to use the testing_text_for_bow because if you are using a different set of test documents, this will create a BoW of a different size. Thus, the best way to do this is to pass just the text that is going to be given in input to the contexual model:
testing_dataset = qt.transform(text_for_contextual=testing_text_for_contextual)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20)Once you have trained the ZeroShotTM model with multilingual embeddings, you can use this simple pipeline to predict the topics for documents in a different language (as long as this language is covered by paraphrase-multilingual-mpnet-base-v2).
# here we have a Spanish document
testing_text_for_contextual = [
"hola, bienvenido",
]
# since we are doing multilingual topic modeling, we do not need the BoW in
# ZeroShotTM when doing cross-lingual experiments (it does not make sense, since we trained with an english Bow
# to use the spanish BoW)
testing_dataset = qt.transform(testing_text_for_contextual)
# n_sample how many times to sample the distribution (see the doc)
ctm.get_doc_topic_distribution(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentAdvanced Notes: We do not need to pass the Spanish bag of word: the bag of words of the two languages will not be comparable! We are passing it to the model for compatibility reasons, but you cannot get the output of the model (i.e., the predicted BoW of the trained language) and compare it with the testing language one.
We have developed two extensions to CTM, one that supports supervision and another one that uses a weight on the KL loss to generate disentangled representations.
NOTE: both model haven't been thoroughly validated. Use them with care and let us know if you find something cool!
Inspiration for SuperCTM has been taken directly from the work by Card et al., 2018 (you can read this as "we essentially implemented their approach in our architecture"). SuperCTM should give better representations of the documents - this is somewhat expected, since we are using the labels to give more information to the model - and in theory should also make the model able to find topics more coherent with respect to the labels. The model is super easy to use and requires minor modifications to the already implemented pipeline:
from contextualized_topic_models.models.ctm import ZeroShotTM
from contextualized_topic_models.utils.data_preparation import TopicModelDataPreparation
text_for_contextual = [
"hello, this is unpreprocessed text you can give to the model",
"have fun with our topic model",
]
text_for_bow = [
"hello unpreprocessed give model",
"fun topic model",
]
labels = [0, 1] # we need to have a label for each document
qt = TopicModelDataPreparation("paraphrase-multilingual-mpnet-base-v2")
# training dataset should contain the labels
training_dataset = qt.fit(text_for_contextual=text_for_contextual, text_for_bow=text_for_bow, labels=labels)
# model should know the label size in advance
ctm = CombinedTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50, label_size=len(set(labels)))
ctm.fit(training_dataset) # run the model
ctm.get_topics(2)We also implemented the intuition found in the work by Higgins et al., 2018, where a weight is applied to the KL loss function. The idea is that giving more weight to the KL part of the loss function helps in creating disentangled representations by forcing independence in the components. Again, the model should be straightforward to use:
ctm = CombinedTM(bow_size=len(qt.vocab), contextual_size=768, n_components=50, loss_weights={"beta" : 3})We support pyLDA visualizations with few lines of code!
import pyLDAvis as vis
lda_vis_data = ctm.get_ldavis_data_format(tp.vocab, training_dataset, n_samples=10)
ctm_pd = vis.prepare(**lda_vis_data)
vis.display(ctm_pd)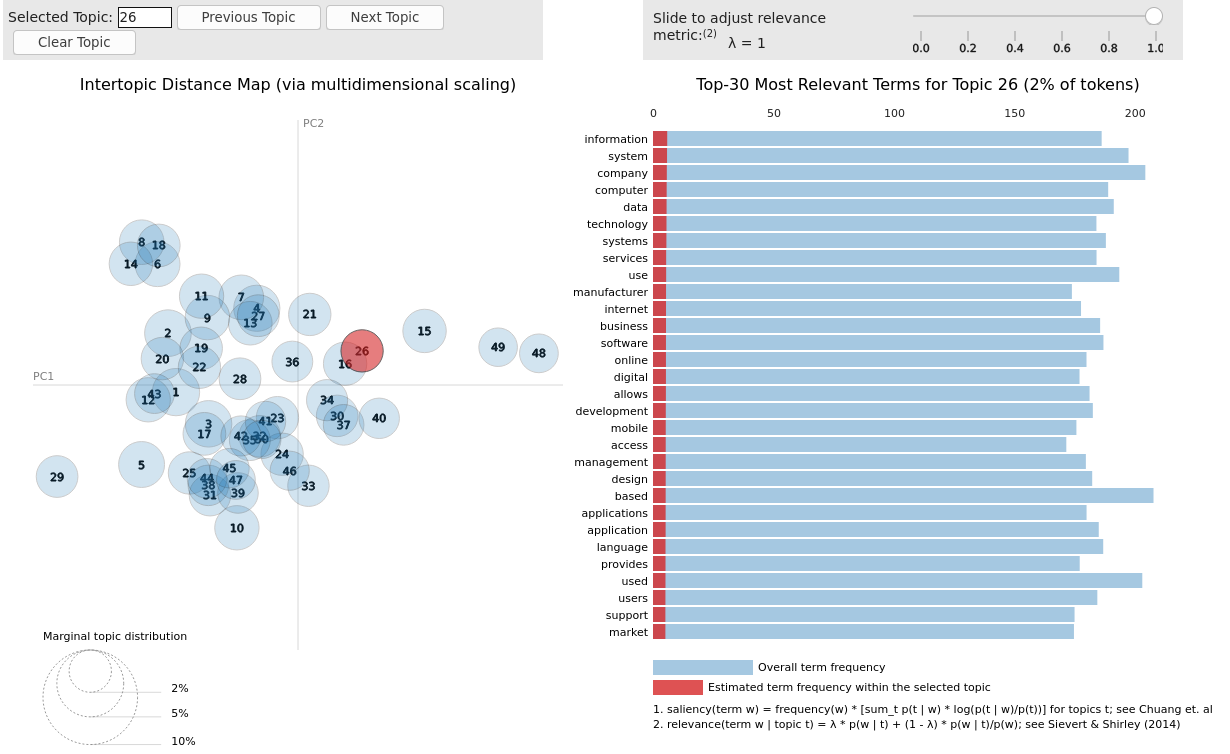
You can also create a word cloud of the topic!
ctm.get_wordcloud(topic_id=47, n_words=15)
Sure, here is a snippet that can help you. You need to create the embeddings (for bow and contextualized) and you also need to have the vocab and an id2token dictionary (maps integers ids to words).
qt = TopicModelDataPreparation()
training_dataset = qt.load(contextualized_embeddings, bow_embeddings, id2token)
ctm = CombinedTM(bow_size=len(vocab), contextual_size=768, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics()You can give a look at the code we use in the TopicModelDataPreparation object to get an idea on how to create everything from scratch. For example:
vectorizer = CountVectorizer() #from sklearn
train_bow_embeddings = vectorizer.fit_transform(text_for_bow)
train_contextualized_embeddings = bert_embeddings_from_list(text_for_contextual, "chosen_contextualized_model")
vocab = vectorizer.get_feature_names()
id2token = {k: v for k, v in zip(range(0, len(vocab)), vocab)}We have also included some of the metrics normally used in the evaluation of topic models, for example you can compute the coherence of your topics using NPMI using our simple and high-level API.
from contextualized_topic_models.evaluation.measures import CoherenceNPMI
with open('preprocessed_documents.txt', "r") as fr:
texts = [doc.split() for doc in fr.read().splitlines()] # load text for NPMI
npmi = CoherenceNPMI(texts=texts, topics=ctm.get_topic_lists(10))
npmi.score()Do you need a quick script to run the preprocessing pipeline? We got you covered! Load your documents and then use our SimplePreprocessing class. It will automatically filter infrequent words and remove documents that are empty after training. The preprocess method will return the preprocessed and the unpreprocessed documents. We generally use the unpreprocessed for BERT and the preprocessed for the Bag Of Word.
from contextualized_topic_models.utils.preprocessing import WhiteSpacePreprocessing
documents = [line.strip() for line in open("unpreprocessed_documents.txt").readlines()]
sp = WhiteSpacePreprocessing(documents, "english")
preprocessed_documents, unpreprocessed_documents, vocab = sp.preprocess()- Federico Bianchi <f.bianchi@unibocconi.it> Bocconi University
- Silvia Terragni <s.terragni4@campus.unimib.it> University of Milan-Bicocca
- Dirk Hovy <dirk.hovy@unibocconi.it> Bocconi University
- Free software: MIT license
- Documentation: https://contextualized-topic-models.readthedocs.io.
- Super big shout-out to Stephen Carrow for creating the awesome https://github.com/estebandito22/PyTorchAVITM package from which we constructed the foundations of this package. We are happy to redistribute this software again under the MIT License.
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template. To ease the use of the library we have also included the rbo package, all the rights reserved to the author of that package.
Remember that this is a research tool :)