A question
Melika-Ayoughi opened this issue · 7 comments
I have a question regarding your implementation:
As I understood the original convolutional lstm formulation is as follows:

But in your implementation, u used only one convolution layer. I don't understand how these 2 correspond with each other. because in the formulation, c is only used in the Hadamard product and not in convolutions, but here c and h are both used in convolutions.
in fact, all weights are shared for all 4 formulas, although there are 11 weights in the original formula.
Hi @Melika-Ayoughi,
and thank you for your interest.
I'm not sure I understood your concern.
Is it possibly a duplicate of this issue?
Please forgive me if it's not.
D
No it's not. I don't have problem with the order.
what u are doing is:
i_t = sigmoid(W *(x_t, h_{t-1}, c_{t-1}))
f_t = sigmoid(W *(x_t, h_{t-1}, c_{t-1}))
So first of all W is the same for all lines, so instead of having W_xi, W_xf, W_hi, W_hf, ... u have one W.
second of all the products are not modelled (for instance W_{ci} .* c_{t-1})
Ok, I think I see your point now.
This repo implements the following dynamic:
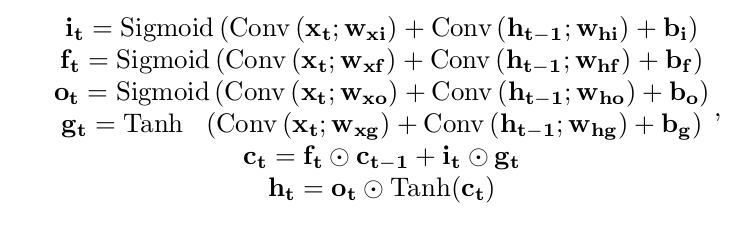
Which is significantly different from the one you reported. Thank you for pointing it out, we should mention it in the README.
D
great! I still don't understand how your implementation has all these weights and not just one weight. can u explain that? because u only convolve x_t and w once. so I assumed there would only be one w and not 8!
Sure!
It's a common trick when dealing with the LSTM family.
- As convolution is a linear operation, you can merge the two convolutions for each gate (horizontally, by reading the equations) by concatenating x_t and h_{t-1} and provide the concatenated tensor as input to a single convolution. This leaves us with 4 convolutions. Now,
- Since each output channel is computed independently (and each convolution acts on the same input tensor, i.e. the concatenated tensor of point 1), you can actually do a single convolution and split channels afterward. This mechanic becomes clearer by looking at the output channels of the conv (they are
4 * self.hidden_dim) and the line in which they are split:
cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.hidden_dim, dim=1)
Does this make sense?
D
I have a question regarding your implementation:
As I understood the original convolutional lstm formulation is as follows:
But in your implementation, u used only one convolution layer. I don't understand how these 2 correspond with each other. because in the formulation, c is only used in the Hadamard product and not in convolutions, but here c and h are both used in convolutions.
in fact, all weights are shared for all 4 formulas, although there are 11 weights in the original formula.
The reported formulation of the ConvLSTM was first introduced in this paper (I believe): https://arxiv.org/pdf/1506.04214.pdf.
The real difference between this implementation and the reported formulation lies in the fact that the paper 'extends' a variant of the LSTM, where each gates gets a contribution from the past cell state.
Hi, I'm curious are there any particular reasons for implementing this variant of the LSTM model? Rather than the original one from the paper https://arxiv.org/pdf/1506.04214.pdf? I'm specifically asking about using
Thank you!