This is a solution to the TGS Salt Identification Challenge competition which ran on Kaggle in 2018.
This solution has an accompanying presentation, which is available on SlideShare.
Several areas of Earth with large accumulations of oil and gas also have huge deposits of salt below the surface.
But unfortunately, knowing where large salt deposits are precisely is very difficult. Professional seismic imaging still requires expert human interpretation of salt bodies. This leads to very subjective, highly variable renderings. More alarmingly, it leads to potentially dangerous situations for oil and gas company drillers.
To create the most accurate seismic images and 3D renderings, TGS (the world’s leading geoscience data company) is hoping Kaggle’s machine learning community will be able to build an algorithm that automatically and accurately identifies if a subsurface target is salt or not.
This solution trains various image segmentation models on the training data provided by TGS as part of the competition. Then, it uses the trained models to predict segmentation masks for the 18,000 test images also provided by TGS, and generate the CSV submission files for the competition.
-
A machine with a fast GPU card and at least 16 GB of RAM (32 GB recommended). Alternatively you can use the cloud - for example spin up a Microsoft Azure N-Series VM.
NOTE: Click here to get a free Azure trial. A valid credit card is required, but you will not be charged.
-
The Anaconda distribution with Python 3.6 or later. If you want to use a pre-configured machine in Azure, you can opt for the Data Science Virtual Machine.
-
The Git client.
-
(Optional) A code editor - you can have your pick between Visual Studio Code, PyCharm, Spyder or others.
-
(Optional) A free Kaggle account - required only if you want to score your models on Kaggle's test data.
-
(Optional) An Azure Machine Learning workspace - required only if you want to scale out to multiple machines, so you can train multiple models in parallel, or train on many data folds, etc. with the least amount of server management required.
-
Download and install Anaconda.
-
Create a new conda environment:
conda create --name tgschallenge python=3.6 -
Activate the new environment:
- on Windows, run
activate tgschallenge - on Linux or MacOS, run
source activate tgschallenge
- on Windows, run
-
Navigate to a folder where you want to host the solution code.
-
Clone this repository in that folder:
git clone https://github.com/neaorin/kaggle-tgs-challenge -
Inside the solution folder, create a subfolder to store the train and test data:
cd kaggle-tgs-challengemkdir data -
Download the train and test image data from Kaggle. You can use the Download link on that page, or the Kaggle API as described in the same page.
You will need to unpack the data inside your locally-created
datafolder. You should end up with the following folder structure:kaggle-tgs-challenge └--- data └--- test └--- images └--- (*).png (18,000 files) └--- train └--- images └--- (*).png (4,000 files) └--- masks └--- (*).png (4,000 files) depths.csv sample_submission.csv train.csv -
Navigate to the
codefolder:cd code -
Install the Python prerequisites:
pip install -r requirements.txt
In order to train a model, you will use the train_fold.py script. The script takes the following parameters as input:
-
--config-file- JSON file containing run configuration. There are example files inside thecode/train-configfolder for various neural network architectures which could be used for this problem. -
--cv-currentfold- The number of the specific cross-validation fold to use in this training run. This controls the specific training / validation split of data. As an example, for a 4-fold cross-validation strategy, you would want to train four separate models - that is, run thetrain-fold.pyscript four times, using0,1,2, and3for the--cv-currentfoldparameter, and then average the predictions. If you don't want to do cross-validation, and go with a single test/validation split, you can omit this parameter. In the latter case, your model might not generalize as well. -
--data-folder- Folder containing the input data (default is thedatafolder) -
--outputs-folder- Folder where outputs should be saved (default is theoutputsfolder which will be created automatically if it doesn't exist)
To train a relatively simple U-Net with ResNet blocks, you can issue the following command from the code folder:
python train_fold.py --config-file train-config/unet-resnet.json
Wait until the training run is complete. Depending on the number of training epochs (you can configure them in the unet-resnet.json file), and the hardware you have available, it may take multiple hours to finish training.
Once the training run is complete, you will find the results in the outputs folder:
-
figures- charts for the various training run metrics. -
models- the trained models. There may be multiple stages employed during training, therefore each run might produce multiple models. -
submissions- CSV files which contain predictions for all the 18,000 test images, and can be submitted to Kaggle to check the performance on the test data -
tb_logs- TensorBoard log data.
You can use Azure Machine Learning to train multiple models in parallel, or train the same model on multiple data folds (cross-validation) without the headaches involved in managing multiple Virtual Machines, and the associated cost-control implications.
Azure Machine Learning allows you to define compute resources for training models. You have a choice of multiple types of resources, from single VMs to Batch AI Clusters which can scale automatically up and down to meet the demand for capacity.
Azure Machine Learning allows you to submit training jobs to your compute resources via Python, and track those runs and their metrics in the Azure portal or with code.
Azure Machine Learning also allows you to deploy your trained models as Docker containers to individual servers or Kubernetes clusters, in order to be consumed by external applications - although this feature is not used here.
-
Create an Azure ML Workspace. You could name it
tgschallenge.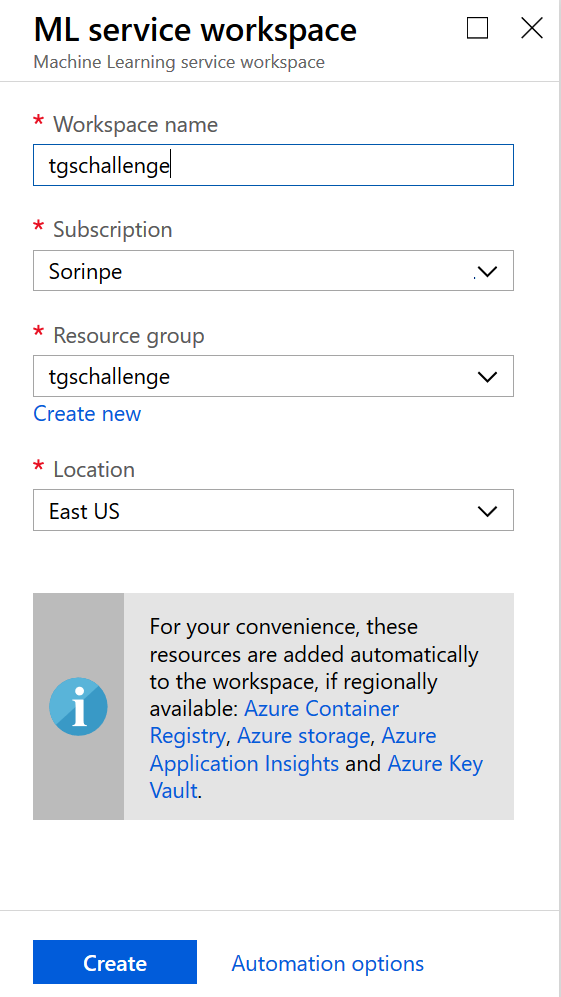
-
Configure your local evironment to use the workspace. You need to create or update the
aml_config/config.jsonfile with the correct workspace identification data:{ "subscription_id": "(GUID)", "resource_group": "(resource group name)", "workspace_name": "(workspace name)" }Test that your setup is correct by using the following code:
python aml_config/test.py -
Upload the training data to the workspace - this may take a while depending on your upload bandwidth:
python aml_config/upload-data.py -
Create a Batch AI Cluster with auto-scale and four maximum nodes with GPUs (N-Series VMs).
python aml_config/create-cluster.pyAlternatively, from the workspace main page in the Azure Portal, you can use the web wizard to create the cluster - below is an example. Make sure you name the cluster tgschallenge.
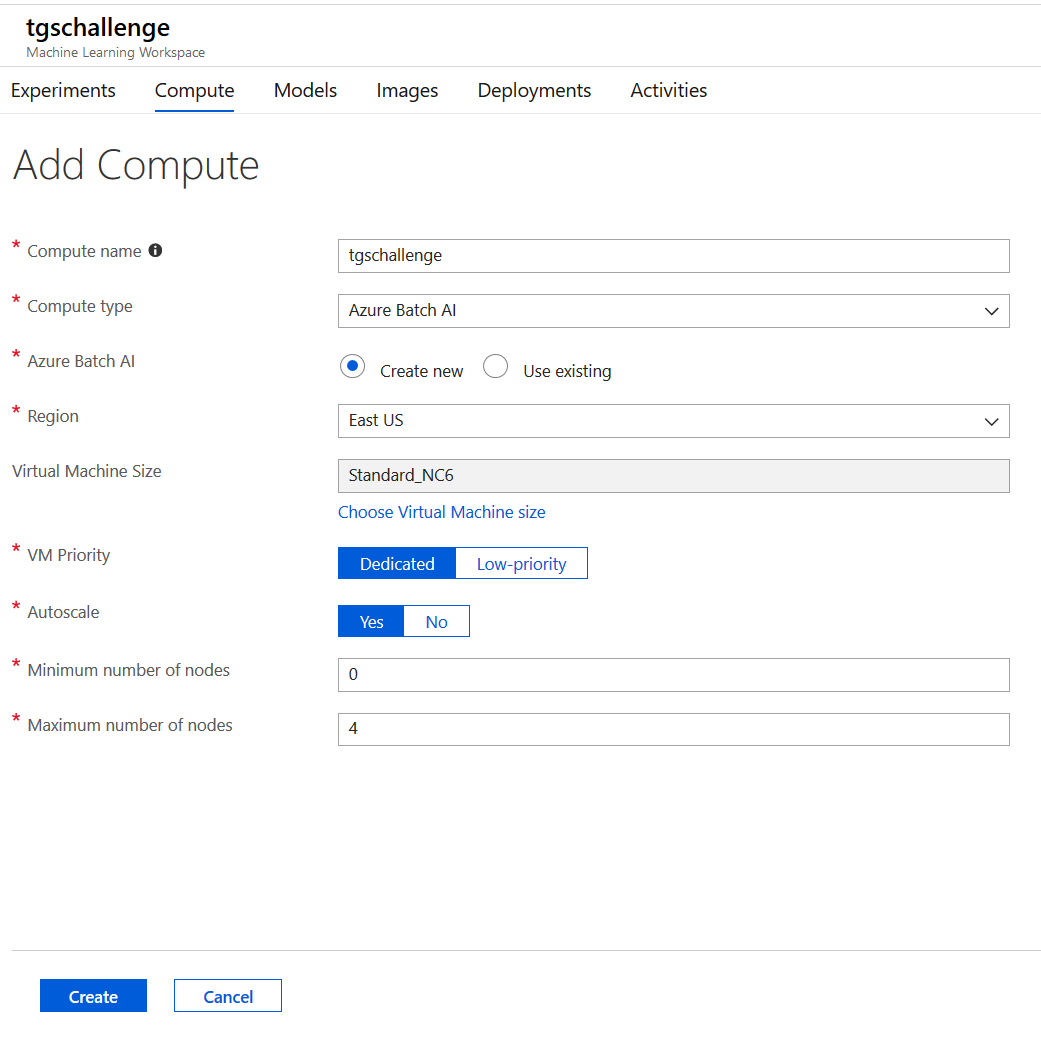


You can now train four models in parallel, on four separate train/validation folds on the data:
python azureml-submit-run.py --config-file train-config\unet-resnet.json --entry-script train-fold.py --experiment-name production
The azureml-submit-run.py script will submit four separate train-fold.py runs to the Azure Machine Learning workspace, which will execute in parallel - provided you have created a Batch AI Cluster with four maximum nodes. Once the jobs are finished, Batch AI will automatically scale down the cluster to zero nodes, which means you won't be charged anything while the cluster is idle.
You can monitor your Azure ML runs in the Azure Portal. You can track job status, job metrics, create additional charts, view log files and download outputs.



