Official repository | arXiv:2010.02302 | NeurIPS 2020 Spotlight
10m video presentation from NeurIPS
The implementation is based on PyTorch. Logging works on wandb.ai. See docker/Dockerfile.
After training, the resulting models will be saved as models/dqn.pt, models/predictor.pt etc.
For evaluation, models will be loaded from the same filenames.
To reproduce LWM results from Table 2:
cd atari
python -m train --env MontezumaRevenge --seed 0
python -m eval --env MontezumaRevenge --seed 0See default.yaml for detailed configuration.
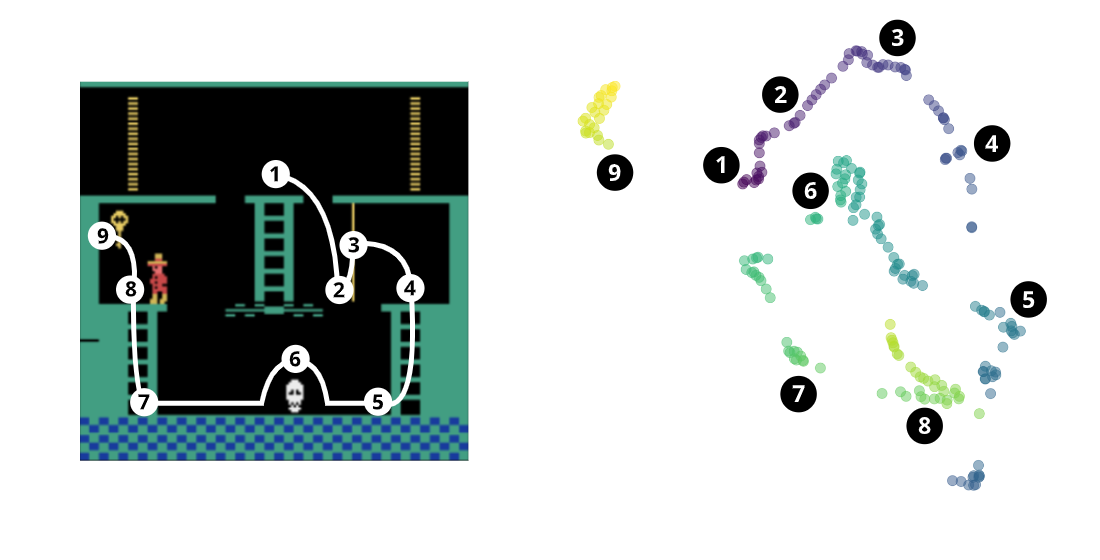
To get trajectory plots as on Figure 3:
cd atari
# first train encoders for random agent
python -m train_emb
# next play the game with keyboard
python -m emb_vis
# see plot_*.pngTo reproduce scores from Table 1:
cd pol
# DQN agent
python -m train --size 3
python -m eval --size 3
# DQN + WM agent
python -m train --size 3 --add_ri
python -m eval --size 3 --add_ri
# random agent
python -m eval --size 3 --randomCode of the environment is in pol/pol_env.py, it extends gym.Env and can be used as usual:
from pol_env import PolEnv
env = PolEnv(size=3)
obs = env.reset()
action = env.observation_space.sample()
obs, reward, done, infos = env.step(action)
env.render()
#######
# # #
# ### #
# #@ #
# # # #
# # #
#######