PyTorch implementation for Vision Transformer[Dosovitskiy, A.(ICLR'21)] modified to obtain over 90% accuracy(, I know, which is easily reached using CNN-based architectures.) FROM SCRATCH on CIFAR-10 with small number of parameters (= 6.3M, originally ViT-B has 86M). If there is some problem, let me know kindly :) Any suggestions are welcomed!
- Install packages
$git clone https://github.com/omihub777/ViT-CIFAR.git
$cd ViT-CIFAR/
$bash setup.sh- Train ViT on CIFAR-10
$python main.py --dataset c10 --label-smoothing --autoaugment- (Optinal) Train ViT on CIFAR-10 using Comet.ml
If you have a Comet.ml account, this automatically logs experiments by specifying your api key.(Otherwise, your experiments are automatically logged usingCSVLogger.)
$python main.py --api-key [YOUR COMET API KEY] --dataset c10| Dataset | Acc.(%) | Time(hh:mm:ss) |
|---|---|---|
| CIFAR-10 | 90.92 | 02:14:22 |
| CIFAR-100 | 66.54 | 02:14:17 |
| SVHN | 97.31 | 03:24:23 |
- Number of parameters: 6.3 M
- Device: V100 (single GPU)
- Mixed Precision is enabled
-
Accucary
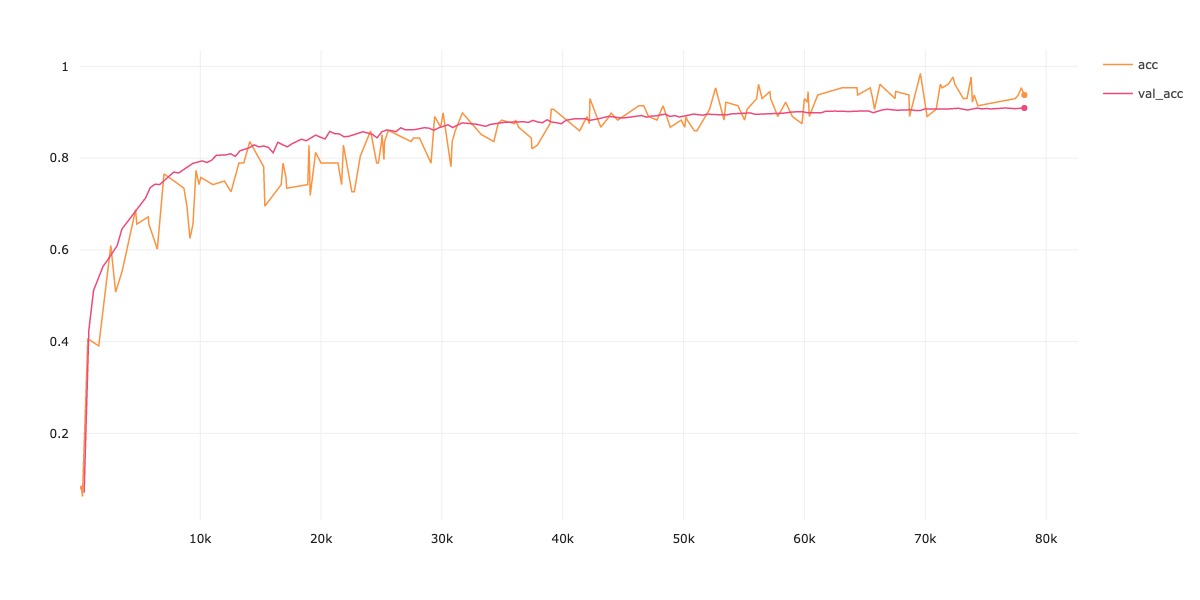
-
Loss
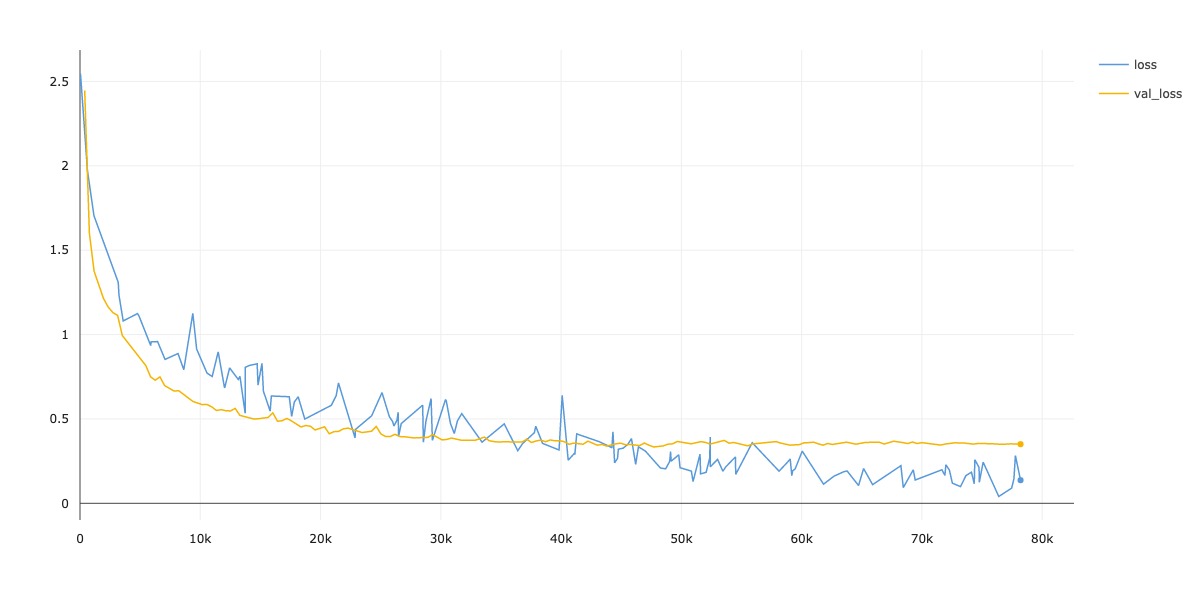


-
Accuracy
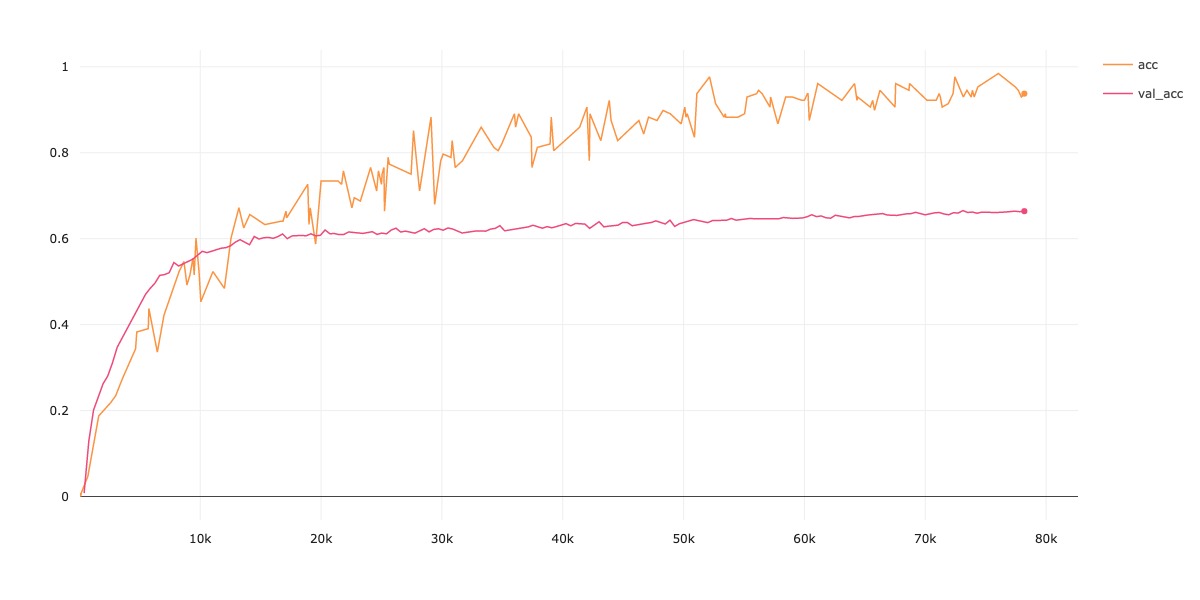
-
Loss
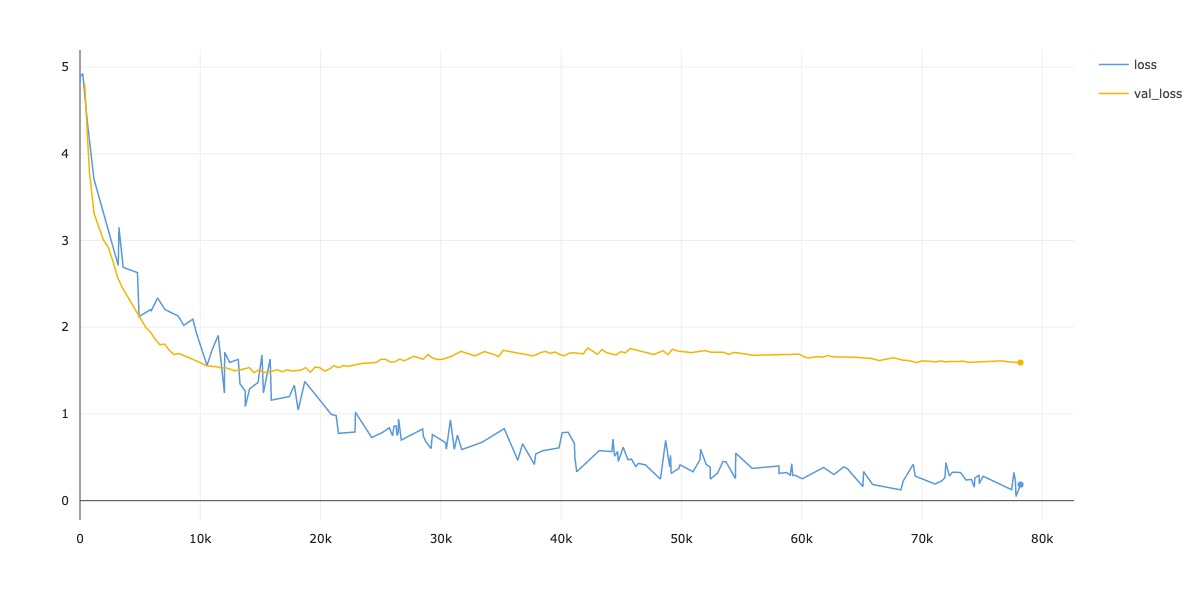


-
Accuracy
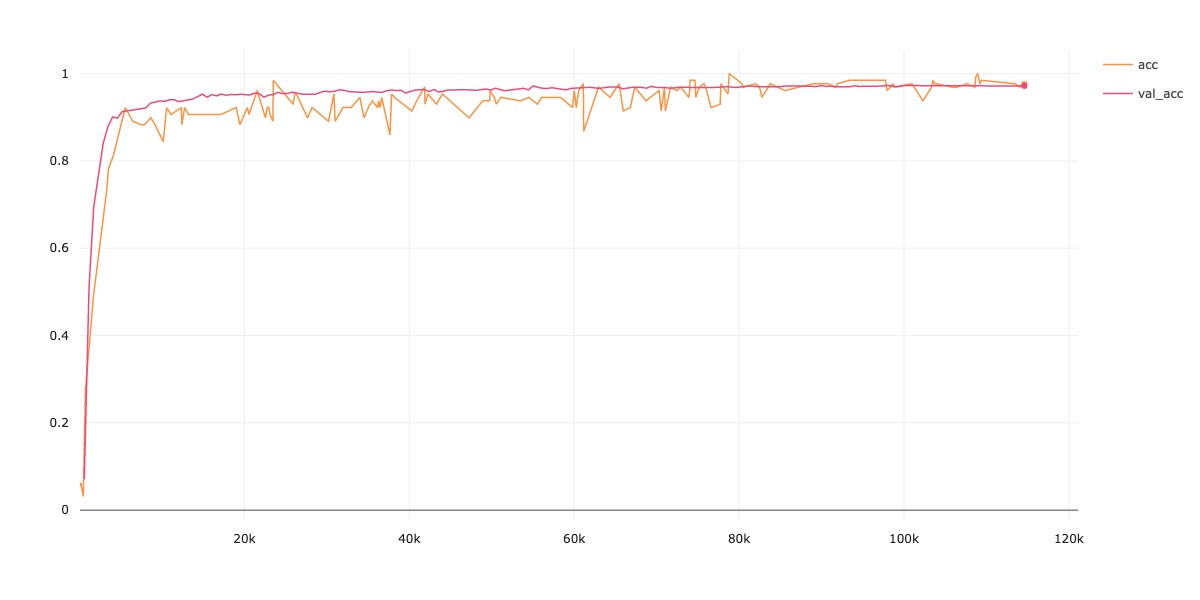
-
Loss
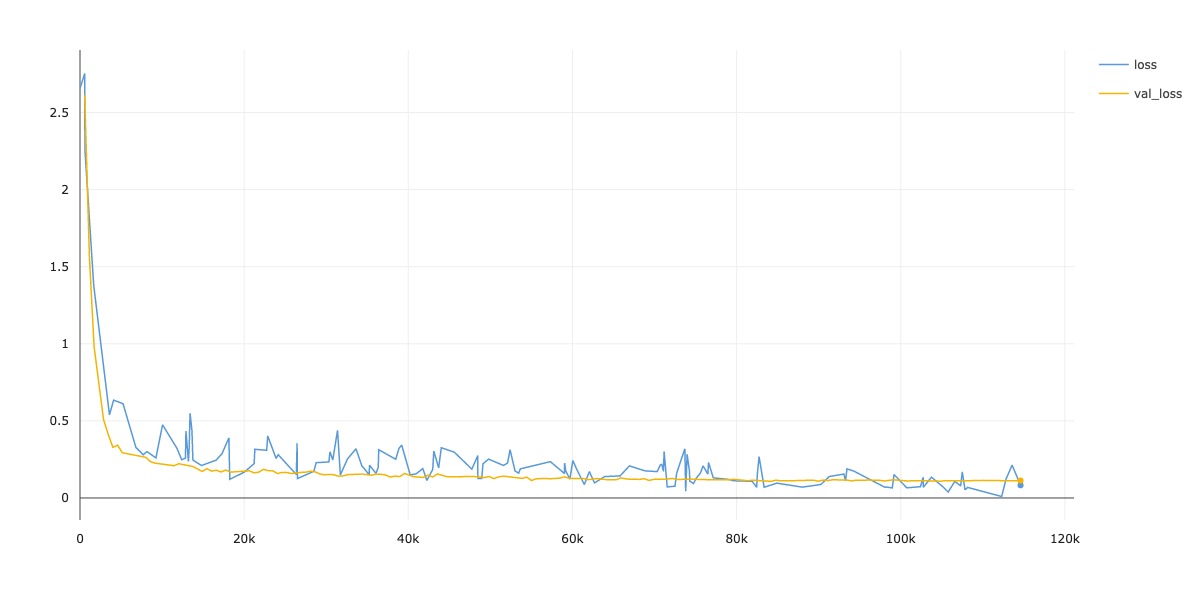


| Param | Value |
|---|---|
| Epoch | 200 |
| Batch Size | 128 |
| Optimizer | Adam |
| Weight Decay | 5e-5 |
| LR Scheduler | Cosine |
| (Init LR, Last LR) | (1e-3, 1e-5) |
| Warmup | 5 epochs |
| Dropout | 0.0 |
| AutoAugment | True |
| Label Smoothing | 0.1 |
| Heads | 12 |
| Layers | 7 |
| Hidden | 384 |
| MLP Hidden | 384 |
- Longer training gives performance boost.
- ViT doesn't seem to converge in 200 epochs.
- More extensive hyperparam search(e.g. InitLR/LastLR/Weight Decay/Label Smoothing/#heads...etc) definitely gives performance gain.
-
- Vision Transformer paper.
-
"TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., et. al, (2021)
- This repo is inspired by the discriminator of TransGAN.
-
- Some tricks comes from this paper.