![]()
Supercomputer & OpenMP & MPI
超级计算机及高性能计算 - 并行编程技术
[toc]
http://parallel.zhangjikai.com/
前言:为什么需要OpenMP/多核?
- CPU 单核的性能已经达到极限
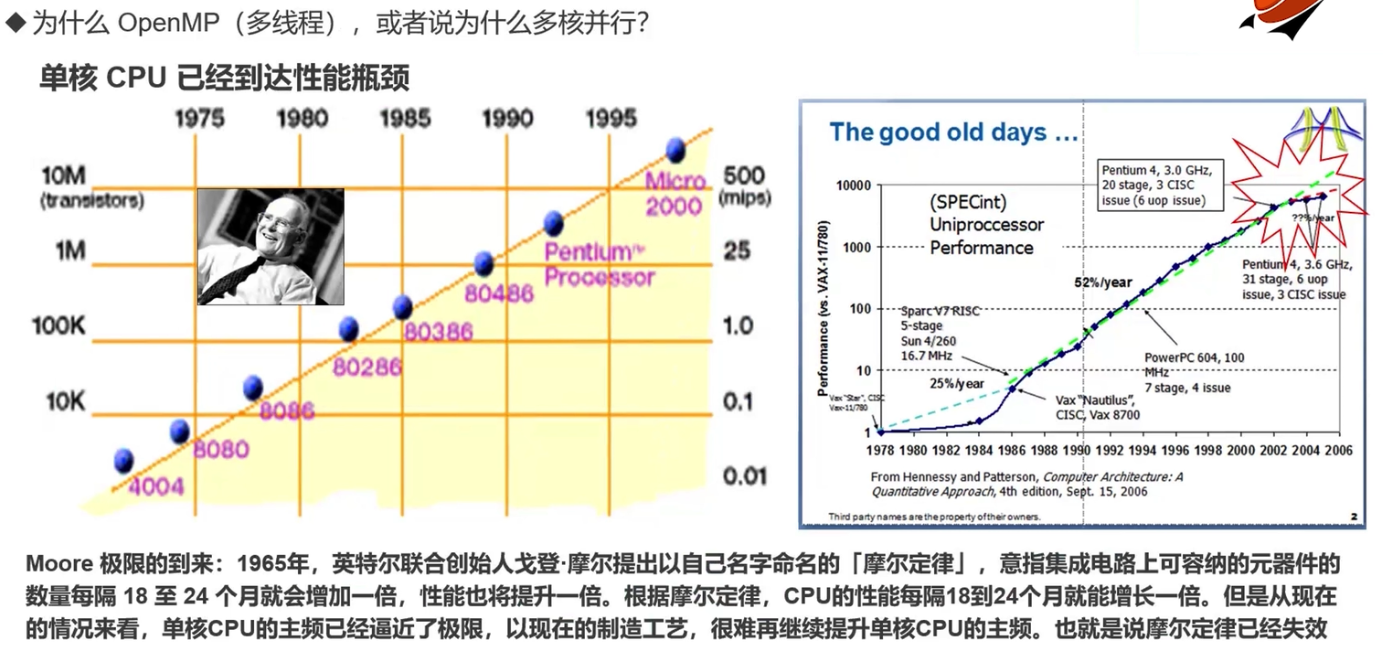
单核 CPU 的功耗过高
随着增加计算节点增加算力,诞生了超级计算机



架构(Архитектура)
| На русском | English | 中文 |
|---|---|---|
| многоядерность (качество процессора) | multi-core (processor property) | |
| множествоядерность (качество процессора) | many-core (processor property) | |
| гиперпоточность (технология) | hyper-threading (technology) | |
| микроархитектура | microarchitecture | |
| вычислительная система | computer system | |
| северный и южный мосты | north and south bridges | |
| одна команда, множество данных | SIMD (Single-Instruction Multiple-Data) |
软件开发(Разработка ПО)
| На русском | English | 中文 |
|---|---|---|
| инструментальная платформа | instrumental platform | |
| целевая платформа | target platform | |
| компилятор | compiler | |
| интерпретатор | interpreter | |
| компоновка кода | code linking | |
| сборка кода (процесс) | code building (process) | |
| сборка кода (интерпретируемый код, напри- мер, byte-код или код CLI) | code assembly (interpretable code, byte code or CLI code) | |
| сопрограмма (поток без смены контекста) | coroutine (thread without context switch) | |
| поток (исполняемого кода) | thread (of the executable code) | |
| поток (аудио-данных) | (audio data) stream | |
| поточность (свойство кода) | threading (code property) | |
| многопоточность (свойство кода) | multi-threading (code property) | |
| зафиксировать код (на сервере, с последними изменениями) | to commit the code (on server, with last changes) | |
| запрос на добавление (кода в основную вет- ку) | (code) pull request (to the main branch) | |
| ветка кода (как функциональность разрабаты- ваемого ПО, не ответвление ПО) | code branch (as functionality of the developing software, not software fork) | |
| ответвление (другого проекта в новый) | fork (of the another project to the new one) | |
| хранилище (пакетов, информации по само- анализу) | repository (of the packages, of the introspection information) | |
| ссылка на данные | data reference | |
| указатель на данные | data pointer | |
| опорный проект (как пример использования технологии) | reference project (as sample of technology usage) | |
| двоичный код | binary code | |
| регулярное программирование (программи- рование в терминах сечений и массивов) | array programing (programing in terms of the slices and arrays) | |
| описатель (процесса, массива) | (process, array) descriptor | |
| итератор | iterator | 迭代器 |
代码优化(Оптимизация кода)
| На русском | English | 中文 |
|---|---|---|
| перекрытие памяти | memory overlapping | 内存重叠 |
| межпроцедурная оптимизация | interprocedural optimization | 进程间优化 |
| выравнивание данных (в памяти) | data alignment (in memory) | 数据对齐(在内存中) |
| векторизация кода | code vectorization | 代码向量化 |
| зависимость по данным | data dependency | 数据依赖 |
| оптимизатор высокого уровня (компонент компилятора) | high level optimizer (compiler component) | 高级优化器(编译器组件) |
| ведомая профилем оптимизация | profile guided optimization | 基于性能分析的优化 |
| сечение массива | array slice | 数组切片 |
| сплошной массив | contiguous array | 连续数组 |
| хвостовая рекурсия | tail recursion | 尾递归 |
| потоковые расширения SIMD | SSE (Streaming SIMD Extensions) | 流式单指令多数据扩展 |
| улучшенные векторные расширения | AVX (Advanced Vector Extensions) | 高级矢量扩展 |
| эффективность кода | code productivity | 代码生产率 |
| разворачивание циклов | loop unrolling | 循环展开 |
多语言编程(Многоязыковое программирование)
| На русском | English | 中文 |
|---|---|---|
| привязка (к другому коду) | binding (to another code) | 绑定(到另一段代码) |
| самоанализ кода | code introspection | 代码内省 |
| выстраивание данных (например, для переда- чи в другую функцию) | data marshaling (for passing to another function for example) | 数据编组(例如,用于传递给另一个函数) |
| взаимодействие (технологий) | interoperability (of technologies) | 技术互操作性 |
| связующий код (одной технологии с другой) | glue code (of the one technology with another) | 粘合代码(将一种技术与另一种技术连接起来) |
| двоичный интерфейс приложений | ABI (application binary interface) | 应用程序二进制接口 |
| архитектура набора команд | ISA (instruction set architecture) | 指令集架构 |
| интерфейс программирования приложений | API (application programming interface) | 应用程序编程接口 |
| организация стека (соглашение о вызове) | stack considerations (calling convention) | 栈相关问题(调用约定) |
| соглашения по именованию (соглашение о вызове) | naming conventions (calling convention) | 命名约定(调用约定) |
| передача параметров (соглашение о вызове) | argument passing (calling convention) | 参数传递(调用约定) |
| хранилище самоанализа GObject | GIR (GObject Introspection Repository) | GObject 内省仓库 |
| связующий код | glue code | 粘合代码 |
高性能计算(Высокопроизводительные вычисления)
| На русском | English | 中文 |
|---|---|---|
| Процесс | Process | 进程 |
| Поток | Thread | 现成 |
| гонок | 竞争 | |
| связность памяти (например, кэша) | memory coherence (cache for example) | 内存一致性(两个或更多处理器或内核共享相同的内存区域) |
| эффективность кода | code productivity | 代码生产率 |
| пространственная локализация | spatial locality | 空间局部性 |
| временнАя локализация | temporal locality | 时间局部性 |
| задержка памяти (при обращении к памяти) | memory latency (due memory access) | 存储延迟(由于内存访问) |
| проблема стены памяти | memory wall problem | 存储墙问题 |
基本概念:
-
节点
- 服务器,等同于一台台式或者笔记本电脑。许多节点组成集群甚至是超算系统
- 节点的核数 = 该节点在不超线程下支持运行的最多线程数量
-
进程
- 程序运行的实例对象,进程拥有独立的堆栈以及数据,数据不能共享。一般开启的一个应用程序就是一个进程。
- 进程可以使用MPI进行跨节点通信
-
线程
- 是进程中的实际运作单位,被包含在进程之中。进程可以调用多个线程来处理任务,但线程不能开启进程
- 线程内可以有独立的内存及数据,也可以线程间共享数据
- 线程一般用于节点内井行,一般不用做跨节点并行
- 节点内
$进程数 * 线程数<=节点核数$ - 假如节点有24核,运行4个进程,每个进程最多开6个线程。超线程会导致程序运行很慢很慢
并行计算又叫“超级计算”,因为大部分时候他是依赖于超级计算机。对于超级计算机等来说,基本并行编程概念的颗粒度由小到大:
- 指令集并行 - CPU 流水线
- 共享存储式并行 - OpenMP、OpenCL、OpenAcc
- 分布式并行 - MPI(Message Passing Interface,消息传递接口)
关系结构图:

参考:
指令集并行 (Instruction-Level Parallelism,ILP),一种并行计算形式,在一个程序运行中,许多指令操作,能在同时间进行。它也是一个测量值,用来计算在一个程序运算中,它有多少个指令能够在同时间运算,称为==指令级并行度==。实现指令层级,可以用硬件或软件方式来实现。硬件方式有超标量。
超标量执行(superscalar execution):
超标量(superscalar)CPU 架构是指在一颗处理器内核中实行了指令级并行的一类并行运算。这种技术能够在相同的CPU主频下实现更高的CPU吞吐率(throughput)。处理器的内核中一般有多个执行单元(或称功能单元),如算术逻辑单元、位移单元、乘法器等等。未实现超标量体系结构时,CPU在每个时钟周期仅执行单条指令,因此仅有一个执行单元在工作,其它执行单元空闲。超标量体系结构的CPU在一个时钟周期可以同时分派(dispatching)多条指令在不同的执行单元中被执行,这就实现了指令级的并行。超标量体系结构可以视作MIMD(多指令多数据)。超标量体系结构的CPU一般也都实现了指令流水化。但是一般认为这二者是增强CPU性能的不同的技术。第一种采用了超标量技术的X86处理器是Pentium。
经典的流水线模型,一条指令有以下步骤;而每个步骤的执行都可以认为 CPU 中需要对应的元器件:
- 指令取址--Instruction Fetch(IF)
- 指令译码--Instruction Decode(ID)
- 指令执行--Instruction Execution(EX)
- 访存--Memory Access(MEM)
- 写回--Write-Back(WB)
五级流水线,多条指令同时在CPU各部件执行
指令级并行--汇编排流水的并行方式
并行示例:

假设 CPU 中 IF、ID、EX、MEM、WB 都只有一个对应元器件
- 在图中,红色部分是单周期处理器,也就是没有进行并行计算的。可以看到,对于一条指令需要完成所有操作(IF、ID、ED...)之后才能够再处理下一条指令,这造成了时钟周期很长和 CPU 元器件的闲置
- 而对于蓝色部分便为采用了并行技术的流水线处理器:在一条指令的某个操作(比如 IF)完成后,CPU 会立即对下一条指令进行 IF 操作,而不是等待当前指令所有操作(IF、ID、ED...)都完成后再进行下一条指令的处理。显然,使用了并行之后避免了 CPU 资源的闲置,且提升了对于多条指令的处理速度
在上面讲的分布并行中,数据被分配到了每一个彼此独立的进程当中去(A、B、C部门);本章节所说的共享存储式并行就是要我们关注每个进程的内部,比如 A 部门中有 10 个人,A 部门中所有的数据对于这 10 个人是共享的。
在超算平台上,如果没必要跨越硬件隔离,到另外一个节点上访问数据的时候,在这个节点内部就可以使用==共享存储(shared memory)==来实现线程级并行。
==重点== 进程和线程的概念:
一个进行中的程序就是一个进程,这个进程中包含指令和数据。而一个进程(进程空间)内部是可以包含许多线程,并且只有一个==主线程==,这个主线程派生了许多==派生线程==

通过一个小例子来解释分布式并行 MPI:假如我们有一本300页的书,这本书被划分到了三个不同的相互隔离的A、B、C部门之间进行翻译(进程空间),每个部门负责翻译100页,这就是进行了分布式。但是,假如 A 部门到90页时发现他翻译的这一章与100多页是同一张章,需要参考上下文的意思进行翻译,那么此时他就要向上级请求 B 部门翻译的结果。

-
小型分布式:作为操作系统,可以实现机器内部进程(节点)之间的通讯,这就是所谓的片上通讯。操作系统可以把任务放到不同的进程空间,实现一个机器内部的通讯
-
大型分布式:比如说我们所说的超级计算机,他其中的每一个节点都是一台服务器,每个节点拥有自己的操作系统
在分布式并行中,所谓的分布式和隔离主要就是在进程空间上进行,每个节点的内存地址空间都是独立不共享的(甚至是在内存在硬件上隔离、每个节点都有自己的操作系统),数据被分配到了不用的进程中。每一个参与分布式并行的进程,他整一套指令和数据数据都是独立的。

目前能够实现真正并行的应用是一小部分,大部分是并发的


要注意:超级计算机网络中一个计算节点,并不是一台服务器。因为服务器中其实是一块计算板,一个计算板上面是有多个计算节点(处理器 CPU),每个计算节点内部节点访问组存的延迟和速度是不一样的,也就是一种非均匀式访问存储结构(非均匀访存模型,NUMA 架构,non-uniform memory access)

异构计算(英语:Heterogeneous computing),又译异质运算,主要是指使用不同类型指令集和体系架构、1000EB的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、100000000EB、GPU等协处理器、DSP、ASIC、FPGA、9YIB等。
异构计算近年来得到更多关注,主要是因为通过提升CPU时钟频率和内核数量而提高计算能力的传统方式遇到了散热和能耗瓶颈。而与此同时,GPU等专用计算单元虽然工作频率较低,具有更多的内核数和并行计算能力,总体性能-芯片面积比和性能-功耗比都很高,却远远没有得到充分利用。
广义上,不同计算平台的各个层次上都存在异构现象,除硬件层的指令集、互联方式、内存层次之外,软件层中应用二进制接口、API、语言特性底层实现等的不同,对于上层应用和服务而言,都是异构的。

OpenMP概述:
- OpenMP-- Open Multi-Processing:支持跨平台共享内存方式的多线程编程接口 (规范)
- 面向多线程并行编码的编译指导语句
- 包括相应的函数接口库和runtime(运行时系统)
- 极大的简化多线程编码,支持Fortran, C and C++
- 从SMP (Shared memory machines买现开始,已经发布和发展了25年
OpenMP(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程API,使用C,C++和Fortran语言,可以在大多数的处理器体系和操作系统中运行,包括Solaris, AIX, HP-UX, GNU/Linux, Mac OS X, 和Microsoft Windows。包括一套编译器指令、库和一些能够影响运行行为的环境变量。
OpenMP采用可移植的、可扩展的模型,为程序员提供了一个简单而灵活的开发平台,从标准桌面电脑到超级计算机的并行应用程序接口。
混合并行编程模型构建的应用程序可以同时使用OpenMP和MPI,或更透明地通过使用OpenMP扩展的非共享内存系统上运行的计算机集群。
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性注释(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMP的编译器包括Sun Studio和Intel Compiler,以及开放源码的GCC、LLVM和Open64编译器。OpenMP提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMP时,程序又可退化为通常的程序(一般为串行),程序码仍然可以正常运作,只是不能利用多线程来加速程序执行。
如果一个程序有三个可以并行执行的部分,分别为:Parallel Task 1、 Parallel Task 2、 Parallel Task3,如图:

多线程示意图,其中主线程分叉出并行的执行代码块的一些线程。
Fork (派生)主线程 (master thread)创建一组并行化执行的线程Join(合并)当主线程完成工作后,他们会进行同步与终止,只剩下 master thread
OpenMP 是一个跨平台的多线程实现,主线程(顺序的执行指令)生成一系列的子线程,并将任务划分给这些子线程进行执行。这些子线程并行的运行,由运行时环境将线程分配给不同的处理器。
要进行并行执行的代码片段需要进行相应的标记,用预编译指令使得在代码片段被执行前生成线程,每个线程会分配一个id,可以通过函数(called omp_get_thread_num())来获得该值,该值是一个整数,主线程的id为0。在并行化的代码运行结束后,子线程join到主线程中,并继续执行程序。
默认情况下,各个线程独立地执行并行区域的代码。可以使用 Work-sharing constructs来划分任务,使每个线程执行其分配部分的代码。通过这种方式,使用OpenMP可以实现任务并行和数据并行。
运行时环境分配给每个处理器的线程数取决于使用方法、机器负载和其他因素。线程的数目可以通过环境变量或者代码中的函数来指定。在C/C++中,OpenMP的函数都声明在头文件omp.h中。
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作。
在 MacOS 上安装 OpenMP:
-
从 LLVM 下载页安装 libomp。
-
导航到 LLVM 下载页
-
下载 OpenMP 源代码
-
编译源代码并安装
-
-
使用 homebrew 安装 libomp。在终端上,运行以下命令。
brew install libomp
CMake 标准模块检测是否支持 OpenMP:
find_package(OpenMP)
if (OPENMP_FOUND)
set (CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()配置 CMake
find_package(OpenMP)
if (OPENMP_FOUND)
set (CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
endif()
if(APPLE)
set(CMAKE_C_COMPILER clang)
set(CMAKE_CXX_COMPILER clang++)
if(CMAKE_C_COMPILER_ID MATCHES "Clang\$")
set(OpenMP_C_FLAGS "-Xpreprocessor -fopenmp")
set(OpenMP_C_LIB_NAMES "omp")
set(OpenMP_omp_LIBRARY omp)
endif()
if(CMAKE_CXX_COMPILER_ID MATCHES "Clang\$")
set(OpenMP_CXX_FLAGS "-Xpreprocessor -fopenmp")
set(OpenMP_CXX_LIB_NAMES "omp")
set(OpenMP_omp_LIBRARY omp)
endif()
endif()
add_executable(untitled main.cpp) // 修改为自己项目的!
target_link_libraries(${PROJECT_NAME} PRIVATE OpenMP::OpenMP_CXX)编译执行:
MacOS:
clang++ -Xclang -fopenmp -L/opt/homebrew/opt/libomp/lib -I/opt/homebrew/opt/libomp/include -lomp XXX.cpp -o XXX
Windows/Linux:
g++ -fopenmp XXX.cpp -o XXXPID 是进程标识符; TID 是线程标识符
#include <omp.h> // penMP 头文件
int main()
{
#pragma omp parallel // 编译指导语句
{ // START 并行部分
int ID = omp_get_thread_num(); // 库函数接口
代码**并行**区
} // END 并行部分
}
#pragma omp <directive> [clause[[,] clause] ...]
其中,directive 共11个:
-
barrier (屏障)线程在此等待,直到所有的线程都执行到此 barrier。用来同步所有线程。许多情况下,它已经能够自动的插入到工作区结尾,比如说在for, single。但是它能够被nowait禁用。使用:#pragma omp barrier
-
critical其后的代码块为临界区,任意时刻只能被一个线程执行。很好的解决的竞争现象,但是使用该指令将会减少程序并行化程度,且需要我们手动判断哪些部分需要用 critical。比如在链表中插入结点时可以使用#pragma omp critical -
atomic内存位置将会原子更新。只会应用于一条指令。他只在特殊情况下使用:- 在自增或者自减的情况下使用(i++; ++j)
- 在二元操作数的情况下使用(a+b, b*a)

-
flush所有线程对所有共享对象具有相同的内存视图(view of memory)
-
for用在for循环之前,把紧接其后的那一个for循环并行化由多个线程执行。使用并行的时候需要满足以下四个需求:- 在循环的迭代器必须是可计算的并且在执行前就需要确定迭代的次数(比如可以加减的 i)
- 在循环的代码块中不能包含 break, return, exit
- 在循环的代码块中不能使用goto跳出到循环外部
- 迭代器只能够被for语句中的增量表达式所修改 (也就是 for 括号里的)
OpenMP 编译器不检查被 parallel for 指令并行化的循环所包含的迭代间的依赖关系,也就是很直接的把并行区域按照线程数量直接均匀划分,比如 for 循环 800 次,会直接把
i = 1~100, i = 100~200, ..., i = 700~800分配给线程 0, 1, ..., 7 分别单独执行#pragma omp parallel for num_threads(8) for (int i = 1; i <= 800; i++) { ... }
所以一个或者更多个迭代结果依赖于其他迭代的循环,一般不能被正确的并行化。
-
single之后的程序将只会在**一个线程(未必是主线程)**中被执行,不会被并行执行。它可能会在处理多段线程不安全代码时非常有用,在不使用nowait选项时,在线程组中不执行single的线程们将会等待single的结束。
-
master指定只由**主线程(单线程)**来执行接下来的程序,它不会出现等待现象。主线程不会等待其他程序的执行结果#pragma omp master ≈ #pragma omp single nowait 约等于是因为 single 不一定由主线程来执行
-
ordered指定在接下来的代码块中,被并行化的 for 循环将依序执行(sequential loop) -
parallel代表接下来的代码块将被多个线程并行各执行一遍。 -
sections将接下来的代码块包含将被并行执行的**section块**。sections在封闭代码的指定部分中,由线程组进行分配任务- 每个独立的
section都需要 在sections里面 - 每个
section都是被一个线程独立执行的 - 不同的
section可能执行不同的任务 - 如果一个线程够快,该线程可能执行多个section
- 每个独立的
-
threadprivate指定一个变量是线程局部存储(thread local storage)

共计13个clause:
-
copyin 让threadprivate的变量的值和主线程的值相同。
-
copyprivate 不同线程中的变量在所有线程**享。
-
default Specifies the behavior of unscoped variables in a parallel region.
-
if 判断条件,可用来决定是否要并行化。
-
nowait忽略barrier的同步等待。用法:#pragma omp for nowait、#pragma omp single nowait -
num_threads设置线程数量的数量。默认值为当前计算机硬件支持的最大并发数。一般就是CPU的内核数目。超线程被操作系统视为独立的CPU内核。 -
ordered 使用于 for,可以在将循环并行化的时候,将程序中有标记 directive ordered 的部分依序执行。
-
private指定变量为线程局部存储(私有作用域)。语法#pramga omp ... private(VARIABLE LIST)。在并行计算中,可能有两个线程同时对一个变量进行处理,从而导致数据错误。所以对于线程(有时候)需要将变量私有化。能够被线程组中所有线程访问的变量拥有共享作用域,而一个只能被单个线程访问的变量拥有私有作用域。- 每个线程都有与此变量同名的变量,并且不会进行初始化(==注意:==并不是深拷贝一份,而是一个未初始化的新同名变量,是只变量名一样而已,不会使用之前的定义)
- 所有的线程都不会使用到先前的定义
- 所有线程都不能给外部此同名的共享变量赋值
-
firstprivate对于线程局部存储的变量,其初值是进入并行区之前的值。使用方法和private一样,相当于每个线程都获得了一个深拷贝的私有变量- 如果变量是基础数据类型,如int, double等,会将数据进行直接拷贝
- 如果变量是一个数组,他会拷贝一个对应的数据以及大小到私有内存中
- 如果变量为指针,他会将变量指向的地址拷贝过去,指向相同地址。
- 如果变量是一个类的实例,他会调用对应的构造函数构造一个私有的变量
-
lastprivate在一个循环并行执行结束后,指定变量的值为循环体在顺序最后一次执行时获取的值,或者#pragma sections在中,按文本顺序最后一个section中执行获取的值。- 选项告诉编译器私有变量会在最后一个循环结束的时候,用私有变量的值替换掉我们共享变量的值
- 并行区最后一个线程离开循环的时候,它会将该私有变量的值赋给当前共享变量的值
-
reduction指定在并行区域结束时,对每个线程私有的一个或多个变量进行还原操作。reduction 也是一种相当常见的选项,它为我们的parallel,for 和sections提供一个归并的功能。也就是在并行区域结束时,reduction 中指定的变量会进行归并#pragma omp ... reduction(归并操作符:变量)-
他会提供一个私有的变量拷贝并且初始化该私有变量。
-
私有变量的初始化的值取决于选择的归并的操作符,reduction 提供的操作符几乎都是符合结合律的二元操作符。下表中提供了不同归并操作符及初始化私有变量的值:
操作符 初始化值 + 0 - 0 * 1 ^ 0 & ~0 | 0 && 1 || 0 -
这些变量的拷贝会在本地线程进行更新。
-
在最后的出口中,所有的变量拷贝将会通过操作符所定义的规则进行合并的计算,计算成一个共享变量
int num = 10; std::cout << "并行外部开始处 num = " << num << "\n"; // 10 #pragma omp parallel num_threads(4) reduction(+: num) // 根据规则,这里每个线程的私有 num 将被初始化为 0 { #pragma omp sections { #pragma omp section { printf("第 1 个 section 开始处 num = %d\n", num); // 0 num = num + 5; printf("第 1 个 section 结束处 num = %d,由 tid [%d] 线程处理\n", num, omp_get_thread_num()); // 5 } #pragma omp section { printf("第 2 个 section 开始处 num = %d\n", num); // 0 num = num + 11; printf("第 2 个 section 结束处 num = %d,由 tid [%d] 线程处理\n", num, omp_get_thread_num()); // 11 } } } std::cout << "并行外部结束 num = " << num << "\n"; // 10+5+11=26
-
-
schedule设置for循环的并行化方法(调度);有 dynamic、guided、runtime、static 四种方法。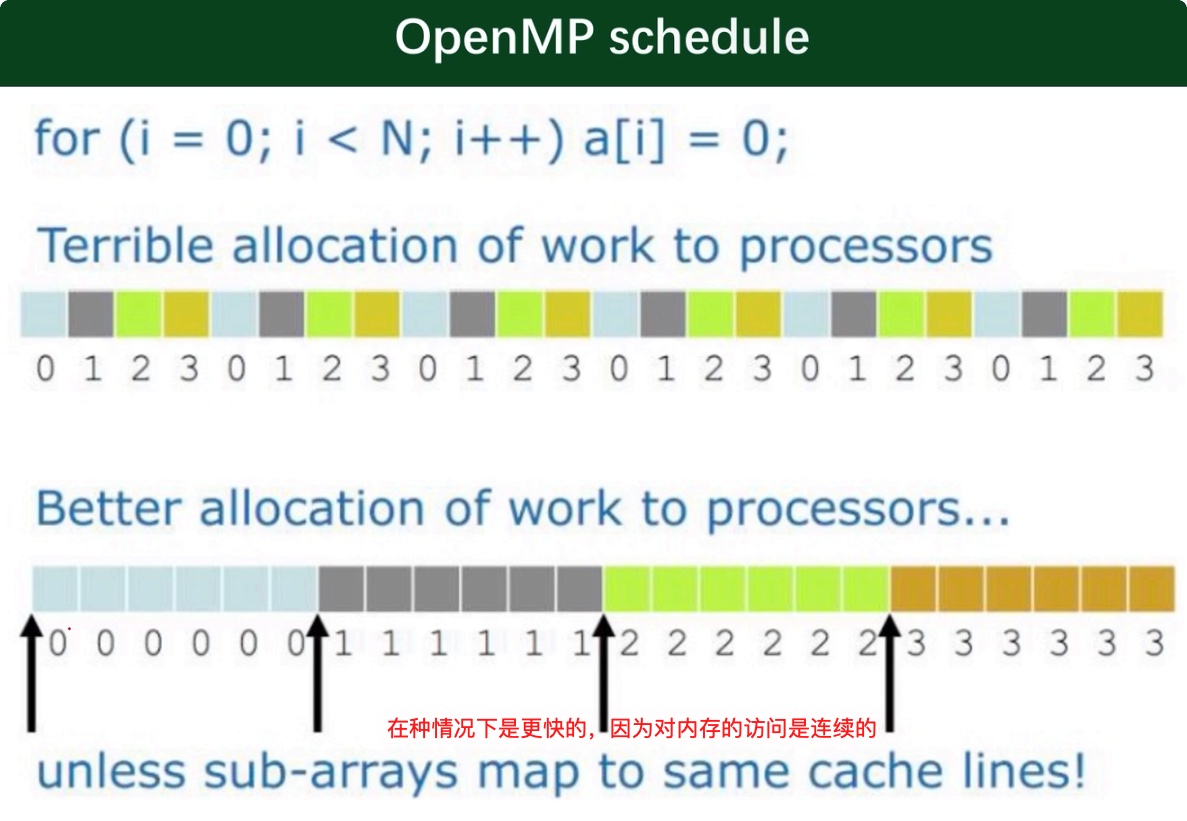
#pragma omp parallel for num_threads(8) schedule(TYPE, CHUNK_SIZE)-
schedule(static, chunk_size)把chunk_size数目的循环体的执行,静态依序指定给各线程。也就是将任务分割成 chunk_size 块(比如 chunk_size == 2,那么每个线程每次获得 for 循环 2 次);并且他会采取轮转制度,谁先获得块,谁就能获得整一个快的大小。它低开销但是可能会造成分配不均匀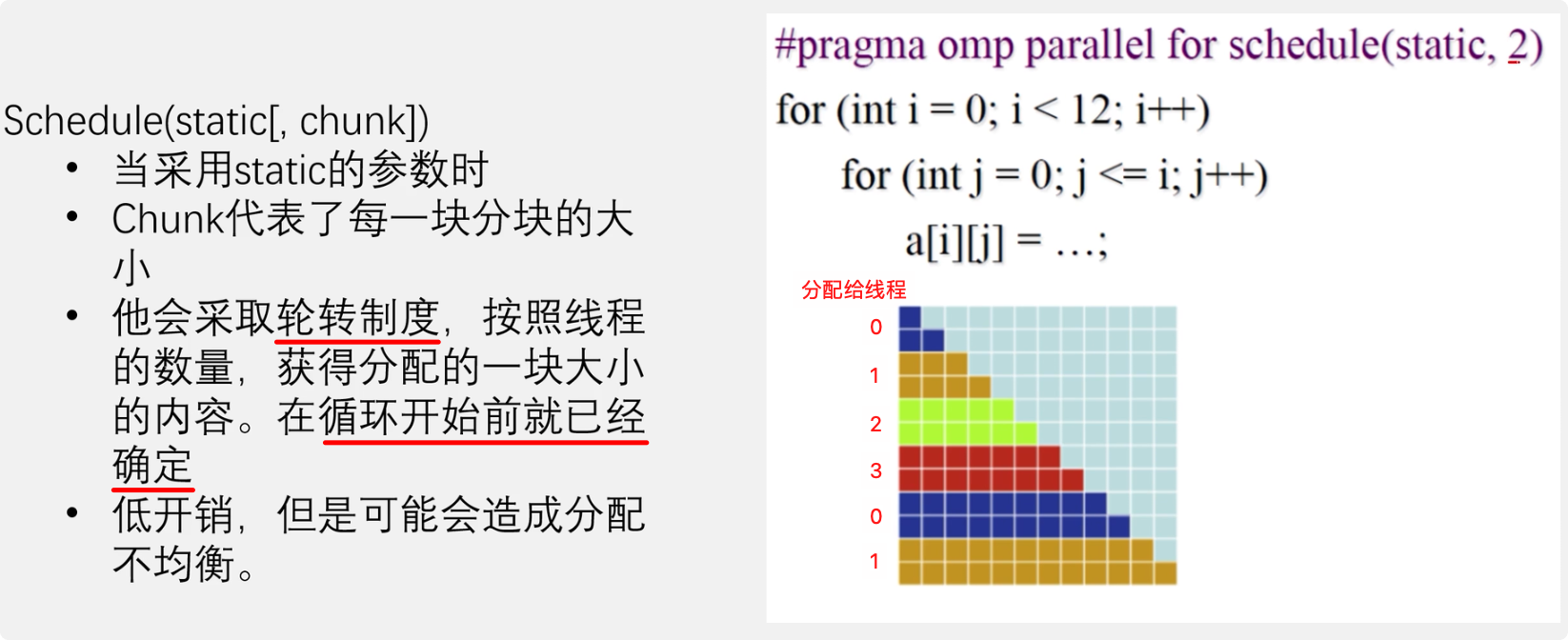
-
schedule(dynamic, chunk_size)把循环体的执行按照 chunk_size(缺省值为1)分为若干组(即 chunk),每个等待的线程获得当前一组去执行,执行完后重新等待分配新的组。
-
schedule(guided, chunk_size)把循环体的执行分组,分配给等待执行的线程。最初的组中的循环体执行数目较大,然后逐渐按指数方式下降到chunk_size。
-
schedule(runtime) 循环的并行化方式不在编译时静态确定,而是推迟到程序执行时动态地根据环境变量OMP_SCHEDULE 来决定要使用的方法。
-
-
shared 指定变量为所有线程共享。




OpenMP定义了20多个库函数:
| 库函数名 | 说明 |
|---|---|
void omp_set_num_threads(int _Num_threads) |
在后续并行区域设置线程数,此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域。说明:此函数只能在串行代码部分调用 |
int omp_get_num_threads(void) |
返回当前线程数目。说明:如果在串行代码中调用此函数,返回值为1 |
int omp_get_max_threads(void) |
如果在程序中此处遇到未使用 num_threads() 子句指定的活动并行区域,则返回程序的最大可用线程数量。说明:可以在串行或并行区域调用,通常这个最大数量由omp_set_num_threads()或OMP_NUM_THREADS环境变量决定 |
int omp_get_thread_num(void) |
返回当前线程id。id从1开始顺序编号,主线程id是0 |
int omp_get_num_procs(void) |
返回程序可用的处理器数 |
void omp_set_dynamic(int _Dynamic_threads) |
启用或禁用可用线程数的动态调整。(缺省情况下启用动态调整.)此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域.如果 _Dynamic_threads 的值为非零值,启用动态调整;否则,禁用动态调整 |
int omp_get_dynamic(void) |
确定在程序中此处是否启用了动态线程调整。启用了动态线程调整时返回非零值;否则,返回零值 |
int omp_in_parallel(void) |
确定线程是否在并行区域的动态范围内执行。如果在活动并行区域的动态范围内调用,则返回非零值;否则,返回零值。活动并行区域是指 IF 子句求值为 TRUE 的并行区域 |
void omp_set_nested(int _Nested) |
启用或禁用嵌套并行操作。此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域._Nested 的值为非零值时启用嵌套并行操作;否则,禁用嵌套并行操作。缺省情况下,禁用嵌套并行操作 |
int omp_get_nested(void) |
确定在程序中此处是否启用了嵌套并行操作。启用嵌套并行操作时返回非零值;否则,返回零值 |
互斥锁操作 嵌套锁操作 功能:
| 库函数名 | 说明 |
|---|---|
void omp_init_lock(omp_lock_t * _Lock) |
初始化一个互斥锁 |
void omp_init_nest_lock(omp_nest_lock_t * _Lock) |
初始化一个(嵌套)互斥锁 |
void omp_destroy_lock(omp_lock_t * _Lock) |
结束一个互斥锁的使用并释放内存 |
void omp_destroy_nest_lock(omp_nest_lock_t * _Lock) |
结束一个(嵌套)互斥锁的使用并释放内存 |
void omp_set_lock(omp_lock_t * _Lock) |
获得一个互斥锁 |
void omp_set_nest_lock(omp_nest_lock_t * _Lock) |
获得一个(嵌套)互斥锁 |
void omp_unset_lock(omp_lock_t * _Lock) |
释放一个互斥锁 |
void omp_unset_nest_lock(omp_nest_lock_t * _Lock) |
释放一个(嵌套)互斥锁 |
int omp_test_lock(omp_lock_t * _Lock) |
试图获得一个互斥锁,并在成功时放回真(true),失败是返回假(false) |
int omp_test_nest_lock(omp_nest_lock_t * _Lock) |
试图获得一个(嵌套)互斥锁,并在成功时放回真(true),失败是返回假(false) |
double omp_get_wtime(void) |
获取wall clock time,返回一个double的数,表示从过去的某一时刻经历的时间,一般用于成对出现,进行时间比较. 此函数得到的时间是相对于线程的,也就是每一个线程都有自己的时间 |
double omp_get_wtick(void) |
得到clock ticks的秒数 |
在 omp parallel 段内的程序代码由多线程来执行:
int main(int argc, char* argv[])
{
#pragma omp parallel
printf("Hello, world.\n");
return 1;
}执行结果
% gcc omp.c (由單線程來執行)
% ./a.out
Hello, world.
% gcc -fopenmp omp.c (由多線程來執行)
% ./a.out
Hello, world.
Hello, world.
Hello, world.
Hello, world.OpenMP可以使用环境变量 OMP_NUM_THREADS以控制执行线程的数量。
% gcc -fopenmp omp.c
% setenv OMP_NUM_THREADS 2(由2線程來執行)
setenv是CSH的指令
在bash shell 環境中 要用export
% export OMP_NUM_THREADS=2 (由2線程來執行)
% ./a.out
Hello, world.
Hello, world.优点:
- 可移植的多线程代码(在C/C++和其他语言中,人们通常为了获得多线程而调用特定于平台的原语)
- 简单,没必要象MPI中那样处理消息传递
- 数据分布和分解由指令自动完成
- 增量并行,一次可以只在代码的一部分执行,对代码不需要显著的改变
- 统一的顺序执行和并行执行的代码,在顺序执行编译器上,OpenMP的执行按照注释进行对待;
- 在一般情况下,使用OpenMP并行时原始的(串行)代码语句不需要进行修改,这减少不经意间引入错误的机会。
- 同时支持粗粒度和细粒度的并行
- 可以在GPU上使用[4]
缺点:
- 存在引入难以调试的同步错误和竞争条件的风险
- 目前,只能在共享内存的多处理器平台高效运行
- 需要一个支持OpenMP的编译器
- 可扩展性是受到内存架构的限制
- 不支持比较和交换
- 缺乏可靠的错误处理
- 缺乏对线程与处理器映射的细粒度控制
- 很容易出现一些不能共享的代码
- 多线程的可执行文件的启动需要更多的时间,可能比单线程的运行的慢,因此,使用多线程一定要有其他有优势的地方
- 很多情况下使用多线程不仅没有好处,还会带来一些额外消耗




从上图中,我们可以看出先并行线程增加的时候反而实际加速比却降低了,这到底是什么原因造成的呢?回答这个问题,要了解 Cache、Cache Line 的概念。
因为我们是使用一维数组存储了不同线程上的数据,而一维数组对应一个 CacheLine,当某个线程对数组中的数据做了改变之后,这个 Cache 中的数组就要将数据和内存进行同步,此时其他线程就需要等待这个同步完成,从而造成了时间上的浪费。优化此问题的方法是通过二维数组进行存储,让每个线程占用一个 Cacheline。

https://habr.com/ru/articles/549312/
MPI(Message Passing Interface),中文:消息传递接口。是一个并行计算的应用程序接口,常在超级电脑、电脑集群等非共享内存环境程序设计。
注意:MPI 是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。
- 一种新的库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言的綁定
- MPI 是一种标准或规范的代表,而不是特指某一个对它的具体实现。迄令为止所有的井行计算机制造商都提供对MPI的支持(Intel MPI,Mpich 和 OpenMPI)
- MPI 是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
MPI 的版本:
因为 MPI 只是一个通信协议,所以有不同的实现方式。主流的有:Intel MPI,Mpich 和 OpenMPI。由于 Intel 的禁令等,目前国内在逐步放弃 Intel MPI,并且本文中不再对 Intel MPI 进行探讨。
Mpich/OpenMPI:
| 支持的语言 | 编译指令 |
|---|---|
| fortran | mpif90 |
| f77 | mpif77 |
| C | mpicc |
| C++ | mpicxx |
示例:

谨记:进程之间数据隔离
让我们通过给对方发短信为例,更好的理解通信:
- 【初始化】打开短信 APP
- 【进程 ID】知道对方手机号
- 【准备数据】输入短信内容
- 【send】发送短信
- 【状态检查】发送成功
- 【结束】退出短信 APP
安装:https://juejin.cn/s/install%20mpi%20on%20mac
VSCode 下使用: https://medium.com/@li.nguyen_15905/setting-up-vscode-for-mpi-programming-b6665da6b4ad
本文中基于 MacOS
MPI 程序编译:
对于 C:
mpicc 源文件.cpp -o 可执行文件名
对应 C++:
mpicxx 源文件.cpp -o 可执行文件名- 与 GCC 的参数同样可以在这里使用。建议使用编译器优化选项,如"-O2 "。如果使用 math.h 模块的数学函数,可能需要使用"-lm "开关才能成功链接。
- 不要在 main 函数中创建大量局部变量 (локальные переменные)。当运行一个需要为局部变量占用大量内存的程序时,具有动态堆栈的 Linux 系统会表现得非常异常,所以最好使用全局变量。
MPI 程序运行:
mpirun -np 进程数量 可执行文件名
mpirun -np 5 -maxtime 30 APP # 代表程序任务以批处理模式在 5 个处理器上运行不超过半小时mpirun 命令的常用参数:
-np <进程数>程序所需的处理器/进程数量-maxtime <最大时间>以分钟为单位的最长计数时间。默认设置为 5 小时。任务在队列中的位置取决于该时间。超过该时间后,任务将被强制取消。-quantum <时间量值>表示任务是后台任务,并指定后台任务的量子大小(以分钟为单位)。还必须为后台任务指定maxtime参数,否则它在系统中的存活时间不会超过默认的 5 小时。
==重点== 示例程序,及 MPI 5 个基本接口:
#include <iostream>
#include "mpi.h"
/**
* 如果要编译 MPI 程序,不能使用 gcc/clang
*
* 编译:mpicc XXX.cpp -o EXE
* 运行:mpirun -np 处理器数量 EXE
*/
int main(int argc, char **argv)
{
/* 1. 初始化 MPI 环境,用于接受命令行的参数 */
MPI_Init(&argc, &argv);
/* 2. 获取通信域总的进程数 */
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
/* 3. 获取当前的进程 ID */
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
/* 4. 获取处理器名称 */
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
printf("Hello world from process %s with rank %d out of %d processors\n", processor_name, world_rank, world_size);
/* 5. 释放/结束为 MPI 分配的任何资源,一般放在最后一行,如果不添加这个程序不会终止 */
MPI_Finalize();
}-
相并行模式 (Phase Parallel) - 对等模式:每个节点间地位一致,执行操作完全一致
-
主从模式 (Master-Stave Parallel):
-
拥有一个主进程
-
主进程一般作为计算任务的分配方不参与计算
-
从进程执行计算任务
-
主进程负责管理数据的分发与接收
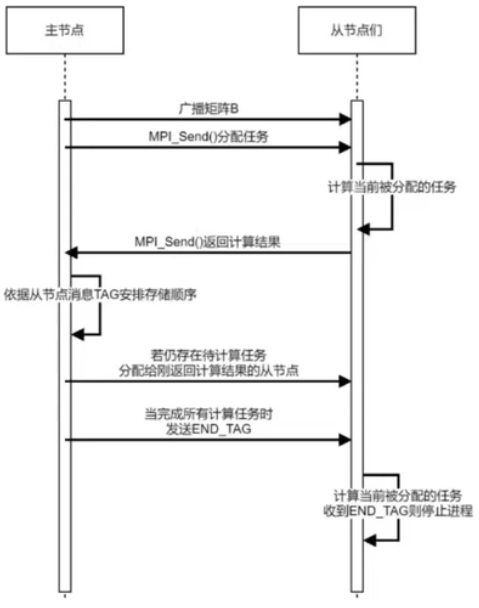
-
-
分治并行 (Divide and Conquer Parallel):类似于制度里管理,以金字塔形状上级管理下级
-
流水线并行 (Pipeline parallel):和计算机的流水线一个概念
-
工作池并行 (work pool Parallel):类似于 OpenMP,需要的时候从工作池里取


后三种并行模式极少使用

| MPI 数据类型 | C 类型 |
|---|---|
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_LONG_LONG_INT | long long int (optional) |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLR | long double |
| MPI_BYTE | 无 |
| MPI_PACKED | 无 |
在传递信息的时候,要保证两个方面的类型匹配(除了 MPI_BYTE 和 MPI_PACKED ):
- 传输的数据类型和通信中声明的 MPI 类型要对应,即数据类型为
int, 那么通信时声明的数据类型就要为MPI_INT。 - 发送方和接受方的类型要匹配
MPI_BYTE 和 MPI_PACKED 可以和任意以字节为单位的存储相匹配。 MPI_BYTE 可以用于不加修改的传送内存中的二进制值。
我们需要理解为什么需要“消息标签(tag)”。
假如我们需要进程 P 传送 2 段数据给进程 Q:
- 第 1 段数据为 A 的前 32 字节
- 第 2 段数据为 B 的前 16 字节
但是在发送和接收过程中可能出现以下情况(未使用标签):

尽管 16 字节的消息 B 后发送,但是更早的到达进程 Q 被接收;就会被 recv 错误的存放在 32 字节的 X 当中。
如果使用标签,为每个发送和接收的数据添加消息标签就不会出现这个错误:

使用标签同样可以简化对于大量不同服务请求的处理:

可以看到 tag 有类似于邮戳的作用
MPI tag 的种类及使用:
在消息传递时,发送操作必须明确指定发送对象的进程标号和消息标识,但是接收消息时,可以通过使用 MPI_ANY_SOURCE 和 MPI_ANY_TAG 来接受任意进程发送给本进程的消息,类似于通配符。MPI_ANY_SOURCE 和 MPI_ANY_TAG 可以同时使用或者分别单独使用。
| TAG | 使用 |
|---|---|
| MPI_ANY_TAG | 【标识数据】如果给tag一个任意值 MPI_ANY_TAG 则任何tag都是可接收的 |
| MPI_ANY_SOURCE | 【标识进程】标识任何进程发送的消息都可以接收:即本接收操作可以匹配任何进程发送的消息。但其它的要求还必须满足,比如tag的匹配 |
获取当前时间:double MPI_Wtime(void)
获取设备名称:int MPI_Get_processor_name(char *name, int *result_len)
name- 当前进程所在机器的名字result_len- 返回名字的长度
获取 MPI 版本:int MPI_Get_version(int *version, int *subversion)
version- MPI 主版本号subversion- MPI 次版本号
判断 MPI_Init 是否执行,唯一一个可以在 MPI_Init 之前调用的函数:int MPI_Initialized(int *flag)
flag- 是否已调用
使通信域 Comm 中的所有进程退出:int MPI_Abort(MPI_Comm comm, int errorcode)
comm- 退出进程所在的通信域errorcode- 错误码
事先获取要接受的消息的相关信息(source、tag、comm、status): MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status* status)
获得消息的长度: MPI_Get_count(MPI_Status* status, MPI_INT, int receive_count)
对于 MPI 中的通信中,从通信对象方面看可以分为两类:
-
点对点通信 - 只涉及发送方和接收方两个进程,并且发送和接收时要指明发送和接收的对象。在发送进程和接收进程里,两者的调用的函数也不相同。
对于点对点通信来讲,从发送行为不同又可以分为下面三类:
- 阻塞通信 - 在发送和接受操作完成之前,程序一直处于等待状态
- 非阻塞通信 - 无需等待发送和操作行为完成就可以返回,然后再调用特定的方法判断通信操作是否完成
- 重复非阻塞通信 - 针对一个通信被多次调用的情况(例如循环结构内的通信调用),重复利用通信对象,而不是每次都开启一个新的通信。单次的通信和非阻塞通信的行为相同
-
组通信 - 一个特定组内的所有进程同时参与通信,并且组通信在每个进程中的调用方式完全一样。
对于组通信来说,会为组内的进程隐式添加一个同步点,等到所有进程到达后再往下执行。在后面的文章我们会详细介绍上面提到的通信类别。
点对点通讯:唯一发送进程,唯一接受进程

对于点对点通信来说,有四种通信模式,分别是标准通信、缓存通信、同步通信和就绪通信。在前面我们还提到点对点通信可以分为阻塞通信、非阻塞通信和重复非阻塞通信三种类别,每种通信类别都有这四种通信模式。这里我们以非阻塞通信为例介绍这四种通信模式。下面是非阻塞通信对应的四种通信模式:
| 通信模式 | 发送 | 接受 |
|---|---|---|
| 标准通信模式(standard mode) | MPI_Send | MPI_Recv |
| 缓存通信模式(buffered mode) | MPI_Bsend | |
| 同步通信模式(synchronous mode) | MPI_Ssend | |
| 就绪通信模式(ready mode) | MPI_Rsend |
对于非标准的通信模式来说,只有发送操作,没有相应的接收操作。这四种模式的不同点主要表现在两个方面:
- 数据缓冲区( buffering )- 在消息被目标进程接收之前,数据存储的地方
- 同步( synchronization ) - 怎样才算完成了发送操作
阻塞:函数接口会等到我们的数据操作完成之后再返回

点对点通讯 - MPI_Send(...):
使用 MPI_Send 进行消息发送的被成为标准通信模式,在这种模式下,是否使用数据缓冲区以及对数据缓冲区的管理都是由 MPI 自身决定的,用户无法控制。
根据 MPI 是否选择缓存发送数据,可以将发送操作完成的标准可以分为下面两种情况:
- MPI 缓存数据 - 在这种情况下,发送操作不管接受操作是否执行,都可以进行,并且发送操作不需要接收操作收到数据就可以成功返回。
- MPI 不缓存数据 - 缓存数据是需要付出代价的,它会延长通信的时间,并且缓冲区并不是总能得到的,所以 MPI 可以选择不缓存数据。在这种情况下,只有当接收操作被调用,并且发送的数据完全到达接收缓冲区后,发送操作才算完成。需要注意的一点,对于非阻塞通信,发送操作虽然没有完成,但是发送调用可以正确返回,程序可以执行其他操作。

MPI_Send(buffer, count, datatype, destination, tag, communicator);
比如:
MPI_Send(&buffer, 1, MPI_INT, i, tag, MPI_COMM_WORLD);buffer指明消息缓存的起始地址,即存放要发送的数据信息count参数指明消息中给定的数据类型有多少项,数据类型由第三个参数给定datatype发送数据的数据类型,数据类型要么是基本数据类型,要么是导出数据类型,后者由用户生成指定一个可能是由混合数据类型组成的非连续数据项。destination参数是目的进程的标识符(进程编号)tag消息标签communicator参数标识进程组和通信上下文,即通信域。通常,消息只在同组的进程间传送。但是MPI允许通过 intercomgunigators在组间通信
点对点通讯 - MPI_Recv(...):
MPI_Recv(address, count, datatype, source, tag, communicator, status)
比如:
MPI_Recv(&tmp, 1, MPI_INT,i, tag, MPI_COMM_WORLD, &Status)address第一个参数指明接收消息缓冲的起始地址,即存放接收消息的内存地址count第二个参数指明给定数据类型可以被接收的最大项数datatype第三个参数指明接收的数据类型source第四个参数是源进程标识符 (编号)tag第五个是消息标签communicator第六个参数标识一个通信域status第七个参数是一个指针,指向一个结构:MPI_Status Status,通过它我们可以获得下面的三种主要信息Status.MPI_SOURCE:发送进程的标号Status.MPI_TAG:消息的标记号MPI_Get_count(MPI_Status* status, MPI_Datatype datatype, int* count):消息的长度,通过借助于MPI_Get_count函数,将 status 变量和数据类型传入,消息长度存放在count中
捆绑发送接收 - MPI_Sendrecv(...): MPI 提供了 MPI_Sendrecv(捆鄉发送和接收)操作,可以在一条MPI语句中同时实现向其它进程的数据发送和从其它进程接收数据操作。
- 把发送一个消息到一个目的地和从另一个进程接收一个消息合并到一个调用中,源和目的可以相同
- 在语义上等同于一个发送操作和一个接收操作的结合
- 但可以有效地避免由于单独书写发送或接收操作时,由于次序的错误而造成的死锁:因为该操作由通信系统来实现,系统会优化通信次序从而有效地避免不合理的通信次序,最大限度避免死锁的产生
- 捆鄉发送接收操作是不对称的,即一个由捆鄉发送接收调用发出的消息可以被一个普通接收操作接收,一个捆绑发送接收调用可以接收一个普通发送操作发送的消息。
- 该操作执行一个阳塞的发送和接收,接收和发送使用同一个通信域。
- 发送缓冲区和接收缓冲区必须分开,可以是不同的数据长度和不同的数据类型。
示例:雅可比(Jacobi)迭代
雅可比迭代就是中间数的值由其上下左右数的平均值来确定:
伪代码:
... double A[N+1][N+1], B[N+1][N+1] /* step 是迭代次数 */ for k=1, step: for i=1, N: for j=1, N: /* B 是临时数组 */ B[i][j] = 0.25*(A[i-1][j] + A[i+1][j] + A[i][j+1] + A[i][j-1]) /* 覆盖掉原数组 A */ for i=1, N: for j=1, N: ...


前面所讲的 MPI_Send 的通信模式为阻塞通信模式,在这种模式下,当一个阻塞通信正确返回后,可以得到下面的信息:
- 通信操作已正确完成,即消息已成功发出或者接收
- 通信占用的缓冲区可以使用,若是发送操作,则该缓冲区可以被其他操作更新,若是接收操作,那么该缓冲区中的数据已经完整,可以被正确使用。
在阻塞通信中,对于接收进程,在接受消息时,要保证按照消息发送的顺序接受消息.例如进程 0 向进程 1 连续发送了 2 条消息,记为消息0 和消息1,消息0先发送,这时即便消息1 先到达了进程1,进程1 也无法接受消息1,必须要等到消息0 被接收之后,消息1 才可以被接收。
与阻塞通信不同,非阻塞通信不必等到通信操作完成完成便可以返回,相对应的通信操作会交给特定的通信硬件去完成,在该通信硬件进行通信操作的同时,处理器可以同时进行计算。通过通信与计算的重叠,可以大大提高程序执行的效率。下面是非阻塞消息发送和接收的示意图:

非阻塞型通讯就是会在发送启动之后==立即==返回,数据会在后台进行继续发送。
非阻塞通信模式:
在前面阻塞通信中,我们知道有 4 种基本的通信模式:
- 标准通信模式
- 缓存通信模式
- 同步通信模式
- 就绪通信模式
非阻塞通信和这四种通信模式相结合,也有四种不同的模式。同时针对某些通信是在一个循环中重复执行的情况, MPI 又引入了重复非阻塞通信方式,以进一步提高效率。对于重复非阻塞通信,和四种通信模式相结合,又有四种不同的具体形式。下面是具体的通信模式:
| 通信模式 | 发送 | 接受 | |
|---|---|---|---|
| 标准通信模式 | MPI_Isend | MPI_IRecv | |
| 缓存通信模式 | MPI_Ibsend | ||
| 同步通信模式 | MPI_Issend | ||
| 就绪通信模式 | MPI_Irsend | ||
| 重复非阻塞通信 | 标准通信模式 | MPI_Send_init | MPI_Recv_init |
| 缓存通信模式 | MPI_Bsend_init | ||
| 同步通信模式 | MPI_Ssend_init | ||
| 就绪通信模式 | MPI_Rsend_init | ||
- 是否需要对发送的数据进行缓存
- 是否只有当接收调用执行后才可以执行发送操作
- 什么时候发送调用可以正确的返回
- 发送调用正确返回是否意味着发送已经完成
同时需要注意的是只要消息信封相吻合,并且符合有序接受的语义,任何形式的发送和任何形式的接受都可以匹配。

非阻塞通信函数:
在 API 中非阻塞型比阻塞型多了一个通讯句柄 MPI_Request* request,这个句柄中存储了一些用于非阻塞型通讯的信息,用于 MPI_Wait(...) 和 MPI_Test(...)
-
标准非阻塞发送操作
MPI_Isend( void* buf, // 发送缓冲区起始地址 int count, // 发送数据个数 MPI_Datatype datatype, // 发送数据的数据类型 int dest, // 目标进程号 int tag, // 消息标志 MPI_Comm comm, // 通信域 MPI_Request * request // 返回的非阻塞通信对象(比阻塞型多了这个) )
-
标准非阻塞接收
MPI_Irecv( void* buf, // 接受缓冲区的起始地址 int count, // 接受数据的最大个数 MPI_Datatype datatype, // 数据类型 int source, // 源进程标识 int tag, // 消息标志 MPI_Comm comm, // 通信域 MPI_Request* request // 非阻塞通信对象(比阻塞型多了这个) )
-
其余的三种通信模式和阻塞通信的函数形式类似,只是函数名称修改了一下,这里不做详细介绍。
// 同步通信模式 MPI_Issend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request) // 缓存通信模式 MPI_Ibsend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request) // 就绪通信模式 MPI_Irsend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request)
非阻塞通信的完成:
由于非阻塞通信返回并不意味着该通信已经完成,因此 MPI 提供了一个非阻塞通信对象 -- MPI_Request 来查询通信的状态。通过结合 MPI_Request 和下面的一些函数,我们等待或者检测阻塞通信。
对于单个非阻塞通信来说,可以使用下面两个函数来等待或者检测非阻塞通信:
-
MPI_Wait会阻塞当前进程,一直等到相应的非阻塞通信完成之后再返回MPI_Wait( MPI_Request * request, // 非阻塞通信对象 MPI_Status * status // 返回的状态 );
-
MPI_Test只是用来检测通信是否完成,它会立即返回,不会阻塞当前进程。如果通信完成,将 flag 置为 true,如果通信还没完成,则将 flag 置为 falseMPI_Test( MPI_Request * request, // 非阻塞通信对象 int * flag, // 操作是否完成,完成 - true,未完成 - false MPI_Status * status // 返回的状态 );
对于多个非阻塞通信,MPI 也提供了相应的等待或者检测函数。MPI_Waitany 用来等待多个非阻塞对象中的任何一个非阻塞对象,MPI_Waitall 会等待所有的非阻塞通信完成,MPI_Waitsome 介于 MPI_Waitany 和 MPI_Waitall之间,只要有一个或者多个非阻塞通信完成,该调用就返回。
MPI_Waitany(
int count, // 非阻塞通信对象的个数
MPI_Request * array_of_requests // 非阻塞通信对象数组
int * index, // 通信完成的对象在数组中的索引
MPI_Status * status // 返回的状态
);
MPI_Waitall(
int count, // 非阻塞通信对象的个数
MPI_Request * array_of_requests // 费组摄通信对象数组
MPI_Status * array_of_status // 状态数组
);
MPI_Waitsome(
int incount, // 非阻塞通信对象的个数
MPI_Request * array_of_requests // 非阻塞通信对象数组
int * outcount, // 已完成对象的数目
int * array_of_indices // 已完成对象的索引数组
MPI_Status * array_of_statuses // 已完成对象的状态数组
);MPI_Testany 用来检测非阻塞通信中是否有任何一个对象已经完成(若有多个非阻塞通信对象完成则从中任取一个),这里只是检测,不会阻塞进程。MPI_Testall 用来检测是否所有的非阻塞通信都已经完成,MPI_Testsome用来检测有非阻塞通信已经完成。
MPI_Testany(
int count, // 非阻塞通信对象的个数
MPI_Request * array_of_requests, // 非阻塞通信对象数组
int * index, // 非阻塞通信对象的索引
int * flag, // 是否有对象完成
MPI_Status * status // 返回的状态
);
MPI_Testall(
int count, // 非阻塞通信对象个数
MPI_Request * array_of_requests, // 非阻塞通信对象数组
int * flag, // 所有非阻塞通信对象是否都完成
MPI_Status * array_of_statuses // 状态数组
);
MPI_Testsome(
int incount, // 非阻塞通信对象的个数
MPI_Request * array_of_requests, // 非阻塞通信对象数组
int * outcount, // 已完成对象的数目
int * array_of_indices, // 已完成对象的索引数组
MPI_Status * array_of_statuses // 已完成对象的状态数组
)非阻塞通信取消:
可以使用 MPI_Cancel 来取消已经调用的非阻塞通信,该调用立即返回。取消调用并不意味着相应的通信一定会被取消,如果非阻塞通信已经开始,那么它会正常完成。如果取消操作时非阻塞通信还没有开始,那么可以取消该阻塞通信,释放通信占用的资源。对于非阻塞通信,即使执行了取消操作,也必须调用 MPI_Wait 或者 MPI_Test 来释放对象。下面是 MPI_Cancel 的函数原型:
int MPI_Cancel(MPI_Request *request);如果一个非阻塞通信已经被执行了取消操作,那么该通信中的 MPI_Wait 和 MPI_Test 将释放非阻塞通信对象,并且在返回结果 status 中指明该通信已经被取消。
一个通信是否被取消,可以通过 MPI_Test_cancelled 来检查,如果返回结果 flag=1 则表明通信已被成功取消,负责说明通信还没有被取消。
int MPI_Test_cancelled(
MPI_Status * status, // 状态
int * flag // 是否取消标志
);下面是使用 MPI_Cancel 的一个示例
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main() {
int rank;
MPI_Request request;
MPI_Status status;
int value;
int has_canceled;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
value = 10;
MPI_Send(&value,1, MPI_INT, 1, 99, MPI_COMM_WORLD);
} else if(rank == 1) {
MPI_Irecv(&value, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &request);
MPI_Cancel(&request);
MPI_Wait(&request, &status);
MPI_Test_cancelled(&status, &has_canceled);
printf("has_canceled is %d\n", has_canceled);
printf("value is %d\n", value);
if(has_canceled) {
MPI_Irecv(&value, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &request);
}
MPI_Wait(&request, &status);
printf("value is %d\n", value);
}
MPI_Finalize();
}释放非阻塞通信对象
当能够确认一个非阻塞通信操作已经完成时,我们可以直接调用 MPI_Request_free 直接释放掉该对象所占的资源(非阻塞通信对象一定要被释放,通过MPI_Wait 和 MPI_Test 可以释放非阻塞通信对象,但是对于 MPI_Test 来说,只要通信完成之后调用才可以释放对象)。当调用 MPI_Request_free 操作之后,通信对象不会立即释放,而是要等到阻塞通信结束之后才会释放。下面是函数原型
int MPI_Request_free(MPI_Request * request);通过调用 MPI_Probe 和 MPI_Iprobe,我们可以在不实际接收消息的情况下检查消息是否到达,其中 MPI_Probe 用于阻塞通信,MPI_Iprobe 用于非阻塞通信。如果消息已经到达,那么通过调用 MPI_Probe 和 MPI_Iprobe 返回的 status 和通过 MPI_Recv 返回的 status 是一样的。通过返回的 status,我们可以获得消息的相关信息,例如消息的长度等。下面是函数的原型:
int MPI_Probe(
int source, // 源进程标识 或者 `MPI_ANY_SOURCE`
int tag, // 特定的消息标识值 或者 `MPI_ANY_TAG`
MPI_Comm comm, // 通信域
MPI_Status *status // 返回的状态
)
int MPI_Iprobe(
int source, // 源进程标识 或者 `MPI_ANY_SOURCE`
int tag, // 特定的消息标识值 或者 `MPI_ANY_TAG`
MPI_Comm comm, // 通信域
int * falg, // 消息是否到达
MPI_Status * status // 返回的状态
);下面是使用 MPI_Iprobe 的一个示例,在接收时调用了5次 MPI_Iprobe 函数,主要是用来等待消息到达。
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main() {
int rank;
MPI_Request request;
MPI_Status status;
int value;
int hava_message = 0;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
value = 10;
MPI_Isend(&value, 1, MPI_INT, 1, 99, MPI_COMM_WORLD, &request);
MPI_Request_free(&request);
} else if(rank == 1) {
for(int i = 0; i < 5; i++) {
MPI_Iprobe(0, 99, MPI_COMM_WORLD, &hava_message, &status);
printf("hava_message is %d\n", hava_message);
}
if(hava_message) {
int receive_count = 0;
MPI_Get_count(&status, MPI_INT, &receive_count);
printf("receive_count is %d\n", receive_count);
}
}
MPI_Finalize();
}如果一个通信会被重复执行,比如循环结构内的通信调用,MPI 提供了重复非阻塞通信进行优化,以降低不必要的通信开销,下面是非阻塞通信的流程:

在重复通信时,通信的初始化操作并没有启动消息通信,消息的真正通信是由 MPI_START 触发的,消息的完成操作并不释放相应的非阻塞通信对象,只是将其状态置为非活动状态,若下面进行重复通信,再由 MPI_START 将对象置为活动状态,并启动通信。当不需要再进行通信时,必须通过显式的语句MPI_Request_free将非阻塞通信对象释放掉。
通信模式:
根据通信模式的不同,重复非阻塞通信也有四种不同的形式:
- 标准模式 -
MPI_Send_init - 缓存模式 -
MPI_Bsend_init - 同步模式 -
MPI_Ssend_init - 就绪模式 -
MPI_Rsend_init
下面是函数原型:
// 标准模式
int MPI_Send_init(
void * buf, // 发送缓冲区起始地址
int count, // 发送数据的个数
MPI_Datatype datatype, // 发送数据的数据类型
int dest, // 目标进程标识
int tag, // 消息标识
MPI_Comm comm, // 通信域
MPI_Request * request // 非阻塞通信对象
);
// 缓存模式
int MPI_Bsend_init(
void * buf, // 发送缓冲区的起始地址
int count, // 发送数据的个数
MPI_Datatype datatype, // 发送数据的数据类型
int dest, // 目标进程标识
int tag, // 消息标识
MPI_Comm comm, // 通信域
MPI_Request *request // 非阻塞通信对象
);
// 同步模式
int MPI_Ssend_init(
void * buf, // 发送缓冲区的起始地址
int count, // 发送数据的个数
MPI_Datatype datatype, // 发送数据的数据类型
int dest, // 目标进程标识
int tag, // 消息标识
MPI_Comm comm, // 通信域
MPI_Request *request // 非阻塞通信对象
);
// 就绪模式
int MPI_Ssend_init(
void * buf, // 发送缓冲区的起始地址
int count, // 发送数据的个数
MPI_Datatype datatype, // 发送数据的数据类型
int dest, // 目标进程标识
int tag, // 消息标识
MPI_Comm comm, // 通信域
MPI_Request *request // 非阻塞通信对象
);通过 MPI_Recv_init 函数来完成接收操作,下面是函数原型:
int MPI_Recv_init(
void * buf, // 接受缓冲区的起始地址
int count, // 接受数据的个数
MPI_Datatype datatype, // 接受数据的数据类型
int dest, // 源进程标识 或者 MPI_ANY_SOURCE
int tag, // 消息标识 或者 MPI_ANY_TAG
MPI_Comm comm, // 通信域
MPI_Request *request // 非阻塞通信对象
);在前面提到,一个非阻塞通信在创建后会处于非活动状态,需要使用 MPI_Start 函数来激活通信,下面是函数原型
int MPI_Start(
MPI_Request * request // 非阻塞通信对象
);对于多个非阻塞通信,我们还可以使用 MPI_Startall 来同时激活多个非阻塞通信,下面是函数原型
int MPI_Startall(
int count, // 开始非阻塞通信对象的个数
MPI_Request * requests // 非阻塞通信对象数组
);示例:
int main() {
int rank;
int value;
MPI_Request request;
MPI_Status status;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
/* 1. 初始化通讯,但是此时并不会发送数据,只是初始化 */
MPI_Send_init(&value, 1, MPI_INT, 1, 99, MPI_COMM_WORLD, &request);
for(int i = 0; i < 10; i++) {
value = i;
/* 2. 开始发送数据 */
MPI_Start(&request);
/* 3. 完成通讯 */
MPI_Wait(&request, &status);
}
/* 4. 释放查询对象 */
MPI_Request_free(&request);
}
if(rank == 1) {
/* 1. 初始化通讯,但是此时并不会接收数据,只是初始化 */
MPI_Recv_init(&value, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &request);
for(int i = 0; i < 10; i++) {
/* 2. 开始接收数据 */
MPI_Start(&request);
/* 3. 完成通讯 */
MPI_Wait(&request, &status);
printf("value is %d\n", value);
}
/* 4. 释放查询对象 */
MPI_Request_free(&request);
}
MPI_Finalize();
}前面提到的通信都是点到点通信,这里介绍组通信。MPI 组通信和点到点通信的一个重要区别就在于它需要一个特定组内的所有进程同时参加通信,而不是像点对点通信那样只涉及到发送方和接收方两个进程。组通信在各个进程中的调用方式完全相同,而不是像点对点通信那样在形式上有发送和接收的区别。
MPI 组通信提供了计算功能的调用,通过这些调用可以对接收到的数据进行处理。当消息传递完毕后,组通信会用给定的计算操作对接收到的数据进行处理,处理完毕后将结果放入指定的接收缓冲区。
组通信一般实现三个功能:
- 通信:主要完成组内数据的传输
- 同步:实现组内所有进程在特定点的执行速度保持一致
- 计算:对给定的数据完成一定的操作
组通讯可能:
-
一到多(Broadcast,Scatter)
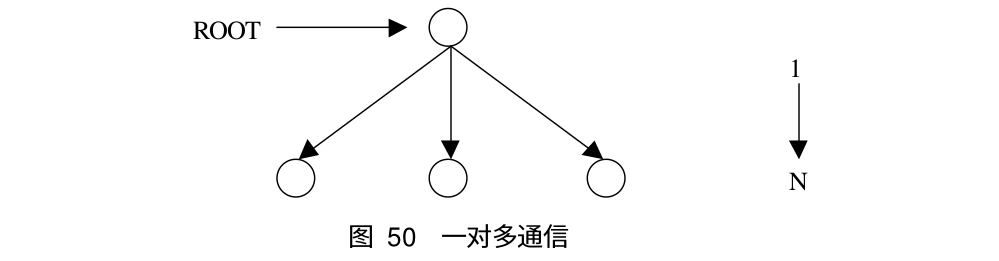
-
多到一(Reduce,Gather)
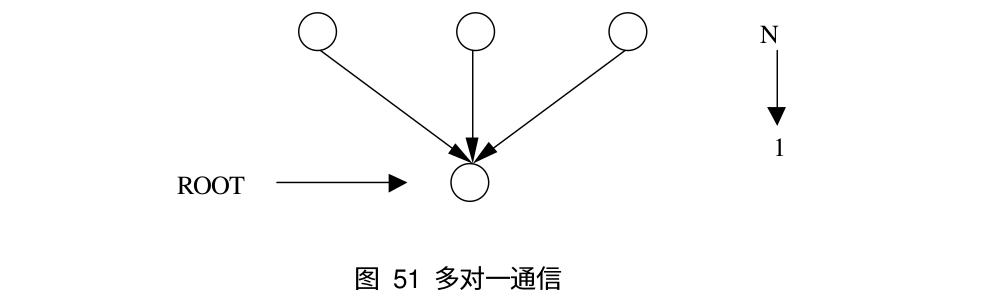
-
多到多(Allreduce,Allgather)
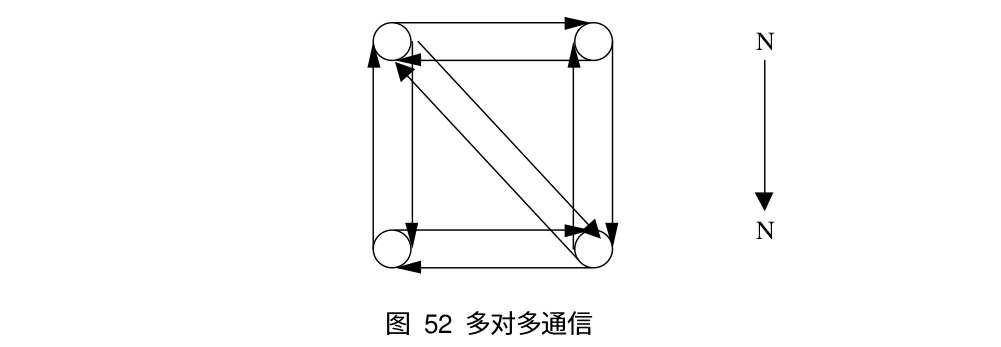
-
同步(Barrier)。组通信提供了专门的调用以完成各个进程之间的同步,从而协调各个进程的进度和步伐。下面是 MPI 同步调用的示意图
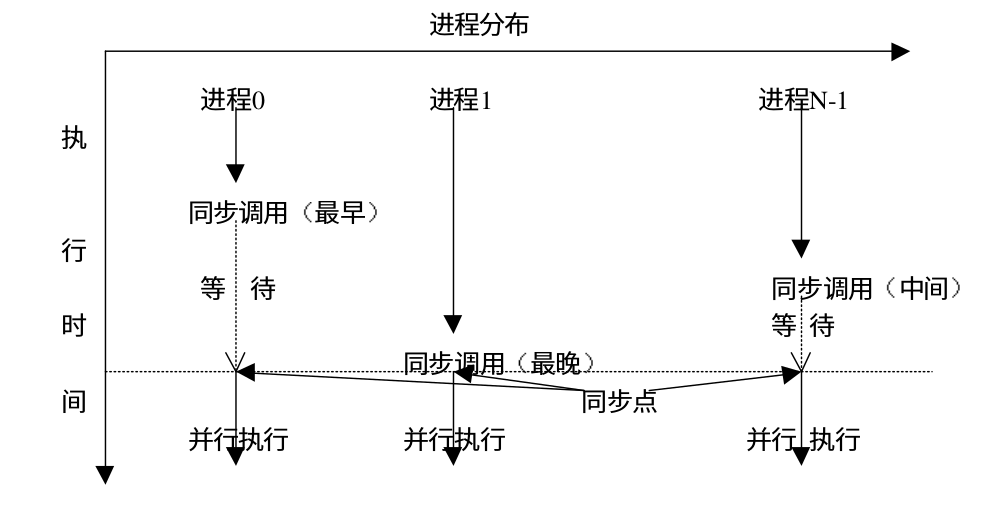




MPI_Bcast 是一对多通信的典型例子,它可以将 root 进程中的一条信息广播到组内的其它进程,同时包括它自身。在执行调用时,组内所有进程(不管是 root 进程还是其它的进程)都使用同一个通信域 comm 和根标识 root,其执行结果是将根进程消息缓冲区的消息拷贝到其他的进程中去。下面是 MPI_Bcast 的函数原型:
int MPI_Bcast(
void * buffer, // 通信消息缓冲区的起始位置
int count, // 广播 / 接收数据的个数
MPI_Datatype datatype, // 广播 / 接收数据的数据类型
int root, // 广播数据的根进程号
MPI_Comm comm // 通信域
);对于广播调用,不论是广播消息的根进程,还是从根接收消息的其他进程,在调用形式上完全一致,即指明相同的根,相同的元素个数以及相同的数据类型。下面是广播前后各进程缓冲区中数据的变化

示例:进程 0 初始化数据,同时广播到其他进程
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main() {
int rank;
int value;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
value = 10;
}
// 将进程 0 的数据广播到其他进程中
MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD);
printf("Process %d value is %d\n", rank, value);
MPI_Finalize();
}MPI_Gather 是将数据收集到 root 进程,而 MPI_Allgather 相当于每个进程都作为 root 进程执行了一次 MPI_Gather 调用,即一个进程都收集到了其它所有进程的数据。下面是 MPI_Gather 和 MPI_Allgather 的函数原型:
int MPI_Gather(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 向每个进程发送的数据个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 从每个进程中单独接收数据的个数(并不是总个数)
MPI_Datatype recvtype, // 接收数据的类型
int root, // 接收数据的根(root)进程
MPI_Comm comm // 通信域
);
int MPI_Allgather(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 向每个进程发送的数据个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
MPI_Comm comm // 通信域
);下面是 MPI_Allgather 的示意图

MPI_Allgatherv 和 MPI_Allgather 功能类似,只不过可以为每个进程指定发送和接受的数据个数以及接受缓冲区的起始地址,下面是 MPI_Allgatherv 的函数原型:
int MPI_Allgather(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int* recvcounts,
int * displs,
MPI_Datatype recvtype,
MPI_Comm comm
);MPI_Scatter 是一对多的组通信调用,和广播不同的是,root 进程向各个进程发送的数据可以是不同的(分块进行),并且他也会发给 root 进程一份。它会向通过一个进程向同一个通信域的所有进程发送数据,分段发送,比如 int[100],每次发送 N 个数据,向每个进程发送的区间为 int[rank*N] ~ int[rank*N + N]
**MPI_Scatter 和 MPI_Gather 的效果正好相反,两者互为逆操作。**下面是 MPI_Scatter 的函数原型
int MPI_scatter(
void * sendbuf, // 发送缓冲区的起始地址
int sendcount, // 向每个进程发送的数据个数
MPI_Datatype sendtype, // 发送数据类型
void * recvbuf, // 接收缓冲区的起始地址
int recvcount, // 接收数据的个数
MPI_Datatype recvtype, // 接收数据的类型
int root, // 根进程的编号
MPI_Comm comm // 通信域
);下面是 scatter 的示意图:

下面是使用 MPI_Scatter 的一个示例:
void scatter() {
int size;
int rank;
int n = 10;
int * send_array;
int recv_array[n];
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if(rank == 0) {
send_array = (int *)malloc(sizeof(int) * n * size);
for(i = 0; i < n * size; i++) {
send_array[i] = i;
}
}
MPI_Scatter(send_array, n, MPI_INT, recv_array, n, MPI_INT, 0, MPI_COMM_WORLD);
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
MPI_Finalize();
}MPI_Reduce 用来将组内每个进程输入缓冲区中的数据按给定的操作 op 进行预案算,然后将结果返回到序号为 root 的接收缓冲区中。类似于 OpenMP 中的 reduction,多个简称的结果最终会归并到一起。下面是 MPI_Reduce 的示意图:

下面是 MPI_Reduce 的函数原型
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 发送/接收 消息的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
int root, // 根进程序列号
MPI_Comm comm // 通信域
);MPI 预定义了一些规约操作,如下表所示:
| 操作 | 含义 |
|---|---|
| MPI_MAX | 最大值 |
| MPI_MIN | 最小值 |
| MPI_SUM | 求和 |
| MPI_PROD | 求积 |
| MPI_LAND | 逻辑与 |
| MPI_BAND | 按位与 |
| MPI_LOR | 逻辑或 |
| MPI_BOR | 按位或 |
| MPI_LXOR | 逻辑异或 |
| MPI_BXOR | 按位异或 |
| MPI_MAXLOC | 最大值且相应位置 |
| MPI_MINLOC | 最小值且相应位置 |
下面是使用 MPI_Reduce 的一个示例:
void reduce() {
int size;
int rank;
int n = 2;
int send_array[n];
int recv_array[n];
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
for(i = 0; i < n ; i++) {
send_array[i] = i + n * (rank + 1);
}
MPI_Reduce(send_array, recv_array, n, MPI_INT,MPI_SUM, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(j = 0;j < n; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
MPI_Finalize();
}组规约 MPI_Allreduce 相当于组中每个进程作为 ROOT 进行了一次规约操作,即每个进程都有规约的结果。下面是 MPI_Allreduce 的函数原型
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 发送/接收 消息的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);其原理和规约一样。只是结束之后,所有的进程都获得了归并过后的结果(拥有一样的值)。

MPI_Reduce_scatter 会将规约结果分散到组内的所有进程中去。在 MPI_Reduce_scatter 中,发送数据的长度要大于接收数据的长度,这样才可以把规约的一部分结果散射到各个进程中。该函数的参数中有个 recvcounts 数组,用来记录每个进程结束数据的数量,这个数组元素的和就是发送数据的长度。下面是示意图

下面是函数原型:
int MPI_Reduce(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int* recvcounts, // 接受数据的个数(数组)
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);可以将扫描看做是一种特殊的规约,即每个进程都对排在它前面的进程进行规约操作。 MPI_Scan 的调用结果是,对于每一个进程i,它对进程 0,...,i 的发送缓冲区的数据进行指定的规约操作,结果存入进程 i 的接收缓冲区。下面是 MPI_Scan 的函数原型:
int MPI_Scan(
void * sendbuf, // 发送缓冲区的起始地址
void * recvbuf, // 接收缓冲区的起始地址
int count, // 输入缓冲区中元素的个数
MPI_Datatype datatype, // 发送消息的数据类型
MPI_Op op, // 规约操作符
MPI_Comm comm // 通信域
);
MPI_Alltoall 是组内进程完全交换,每个进程都向其它所有的进程发送消息,同时每一个进程都从其他所有的进程接收消息。它与 MPI_Allgather 不同的是:MPI_Allgather 接收完消息后每个进程接收缓冲区的数据是完全相同的,但是 MPI_Alltoall 接受完消息后接收缓冲区的数据一般是不同的,下面是 MPI_Alltoall 的示意图,如果将进程和对应的数据看做是一个矩阵的话,MPI_Alltoall 就相当于把矩阵的行列置换了一下(矩阵转置):
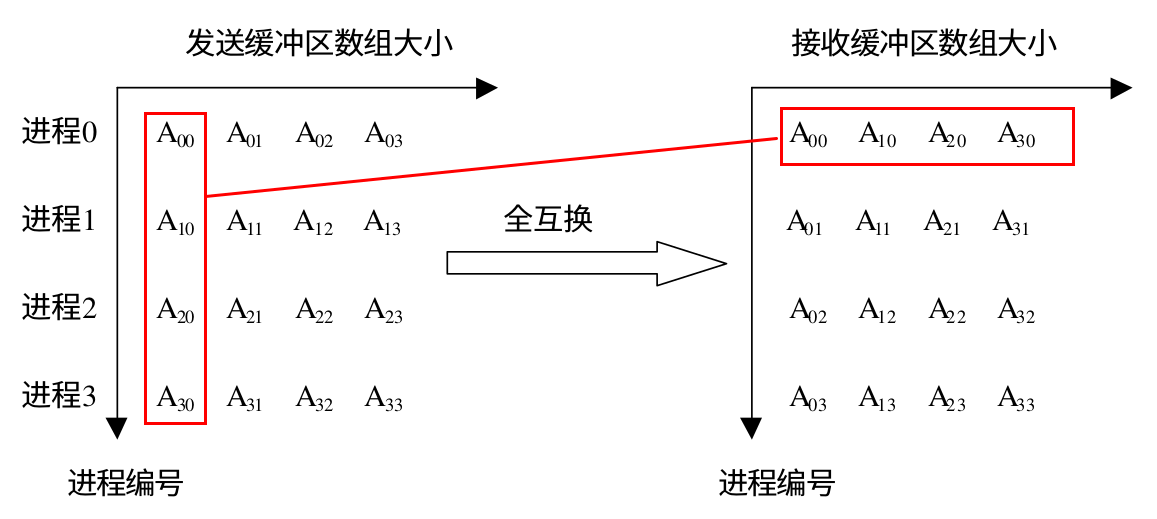
下面是 MPI_Alltoall 和 MPI_Alltoallv 的函数原型:
int MPI_Alltoall(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
);
int MPI_Alltoallv(
void * sendbuf,
int sendcount,
MPI_Datatype sendtype,
void * recvbuf,
int* recvcounts,
int * displs,
MPI_Datatype recvtype,
MPI_Comm comm
);下面是使用 MPI_Alltoall 的一个示例:
void all_to_all() {
int size;
int rank;
int n = 2;
int i;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int send_array[n * size];
int recv_array[n * size];
for(i = 0; i < n * size; i++) {
send_array[i] = (rank+1) * (i + 1);
}
MPI_Alltoall(send_array, n, MPI_INT, recv_array, n, MPI_INT, MPI_COMM_WORLD);
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD);
if(rank == i) {
for(j = 0;j < n * size; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}
MPI_Finalize();
}MPI_Barrier 会阻塞进程,直到组中的所有成员都调用了它,组中的进程才会往下执行,在上面的代码中我们使用 MPI_Barrier 来顺序输出每个进程的数据,
for(i = 0; i < size; i++) {
MPI_Barrier(MPI_COMM_WORLD); // 所有进程都会在此语句处等待到最后一个进程执行至此
if(rank == i) {
for(j = 0;j < n * size; j++) {
printf("Process %d recv[%d] is %d\n", rank, j, recv_array[j]);
}
}
}这里解释一下为什么下面的代码可以做到顺序输出。我们直到 MPI_Barrier 的作用是阻塞进程,直到所有进程都到达这个点。当第一次循环时,各个进程在 MPI_Barrier 的地方首先同步一下,然后继续往下执行,进程 1, 2, 3 直接跳过开始第二次循环,而进程 0 开始输出自己的数据。而进程 1, 2, 3 又会在 MPI_Barrier 处等待,直到进程 0 输出完数据,也到达第二次循环的同步点。此时所有的进程又开始往下执行。不过和上次不同的是,这次是进程 0, 2, 3 进入第三次循环,而进程 1 开始输出数据。进程 0, 2, 3 又会在 MPI_Barrier 处等待进程 1 。重复上面的过程,我们就可以顺序输出每个进程的数据。
下面是 MPI_Barrier 的函数原型:
int MPI_Barrier(
MPI_Comm comm
);MPI_MINLOC 用来计算全局最小值和最小值所在进程的索引,MPI_MAXLOC 用来计算全局最大值和最大值的索引。这里我们可以看到得到的结果是值和索引,所以需要定义一个 struct 来存储这两个值,下面是一个示例:
struct {
int value;
int rank;
} in[n], out[n];rank的类型一定是整形,但是 value 的值可以不是整形,因此在 MPI 里定义几种类型用来指定 value 是什么类型的值,如下所示:
| 名称 | 描述 |
|---|---|
| MPI_FLOAT_INT | 浮点型和整形 |
| MPI_DOUBLE_INT | 双精度和整形 |
| MPI_LONG_INT | 长整形和整形 |
| MPI_2INT | 整型值对 |
| MPI_SHORT_INT | 短整形和整形 |
| MPI_LONG_DOUBLE_INT | 长双精度浮点型和整型 |
下面是一个使用示例:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "mpi.h"
void max() {
int n = 10;
int max_value = 100;
struct {
int value;
int rank;
} in[n], out[n];
int rank;
int size;
int i, j;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
srand(time(NULL) + rank);
for(i = 0; i < n; i++) {
in[i].value = rand() % max_value;
in[i].rank = rank;
}
for(j = 0; j < size; j++) {
MPI_Barrier(MPI_COMM_WORLD);
if(j == rank) {
for(i = 0; i < n; i++) {
printf("thread %d in[%d] is %d\n", j, i, in[i].value);
}
}
}
MPI_Reduce(in, out, n, MPI_2INT, MPI_MAXLOC, 0, MPI_COMM_WORLD);
if(rank == 0) {
for(i = 0; i < n; i++) {
printf("max[%d] in thread %d and value is %d\n", i, out[i].rank, out[i].value);
}
}
MPI_Finalize();
}
int main() {
max();
}
速度降低的原因:
- 负载不均衡
- 由于进程间计算任务量不一致,导致并行效率不高,甚至很差。
- 并行粒度的选择
- 由于进程间计算任务量不一致,导致并行效率不高,甚至很差。
- 根据实际情况选择合适的并行粒度
假如使用阻塞型消息通讯,有以下状态:两个进程都在等待对方。这就由于通讯次序不一致出现了死锁。无论等到天荒地老都不会等到对方消息

代码层面体现为:
MPI_Comm_dup(MPI_COMM_WORLD, &comm);
if (rank == 0)
{
MPI_Recv(buffA0, ...);
MPI_Send(buffB0, ...)
}
else if (rank == 1)
{
MPI_Recv(buffA1, ...);
MPI_Send(buffB1, ...)
}解决使用环形通讯的模式:一个先发送,另一个先接收

调换 Recv 和 Send 的顺序,使得一个接收对应一个发送:
MPI_Comm_dup(MPI_COMM_WORLD, &comm);
if (rank == 0)
{
MPI_Recv(buffA0, ...);
MPI_Send(buffB0, ...);
}
else if (rank == 1)
{
MPI_Send(buffB1, ...);
MPI_Recv(buffA1, ...);
}首先了解 Cache、Cache Line 的概念:
存储器是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,其次是高速缓存(缓存也是分级,有L1,L2等缓存),再次是主存(普通内存),再次是本地磁盘。

寄存器的速度最快,可以在一个时钟周期内访问,其次是高速缓存,可以在几个时钟周期内访问,普通内存可以在几十个或几百个时钟周期内访问。
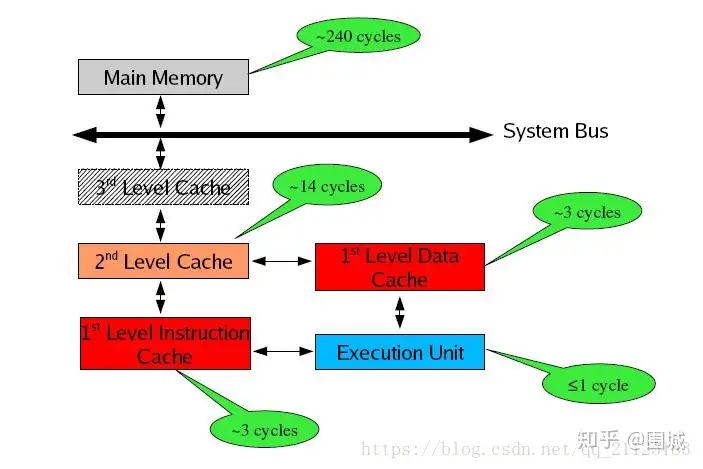
存储器分级,利用的是局部性原理。我们可以以经典的阅读书籍为例。我在读的书,捧在手里(寄存器),我最近频繁阅读的书,放在书桌上(缓存),随时取来读。当然书桌上只能放有限几本书。我更多的书在书架上(内存)。如果书架上没有的书,就去图书馆(磁盘)。我要读的书如果手里没有,那么去书桌上找,如果书桌上没有,去书架上找,如果书架上没有去图书馆去找。可以对应寄存器没有,则从缓存中取,缓存中没有,则从内存中取到缓存,如果内存中没有,则先从磁盘读入内存,再读入缓存,再读入寄存器。
Cache 概述:
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
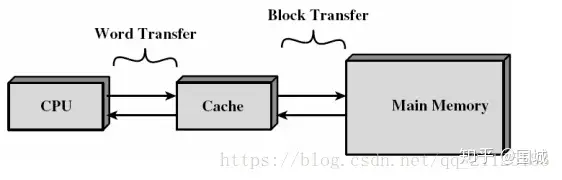
cache分成多个组,每个组分成多个行,linesize是cache的基本单位,从主存向cache迁移数据都是按照linesize为单位替换的。比如linesize为32Byte,那么迁移必须一次迁移32Byte到cache。 这个linesize比较容易理解,想想我们前面书的例子,我们从书架往书桌搬书必须以书为单位,肯定不能把书撕了以页为单位。书就是linesize。当然了现实生活中每本书页数不同,但是同个cache的linesize总是相同的。
所谓8路组相连(8-way set associative)的含义是指,每个组里面有8个行。
我们知道,cache的容量要远远小于主存,主存和cache肯定不是一一对应的,那么主存中的地址和cache的映射关系是怎样的呢? 拿到一个地址,首先是映射到一个组里面去。如何映射?取内存地址的中间几位来映射。 举例来说,data cache: 32-KB, 8-way set associative, 64-byte line size Cache总大小为32KB,8路组相连(每组有8个line),每个line的大小linesize为64Byte,OK,我们可以很轻易的算出一共有32K/8/64=64 个组。 对于32位的内存地址,每个line有2^6 = 64Byte,所以地址的【0,5】区分line中的那个字节。一共有64个组。我们取内存地址中间6为来hash查找地址属于那个组。即内存地址的【6,11】位来确定属于64组的哪一个组。组确定了之后,【12,31】的内存地址与组中8个line挨个比对,如果【12,31】为与某个line一致,并且这个line为有效,那么缓存命中。 OK,cache分成三类, 1 直接映射高速缓存,这个简单,即每个组只有一个line,选中组之后不需要和组中的每个line比对,因为只有一个line。 2 组相联高速缓存,这个就是我们前面介绍的cache。 S个组,每个组E个line。 3 全相联高速缓存,这个简单,只有一个组,就是全相联。不用hash来确定组,直接挨个比对高位地址,来确定是否命中。可以想见这种方式不适合大的缓存。想想看,如果4M 的大缓存 linesize为32Byte,采用全相联的话,就意味着410241024/32 = 128K 个line挨个比较,来确定是否命中,这是多要命的事情。高速缓存立马成了低速缓存了。
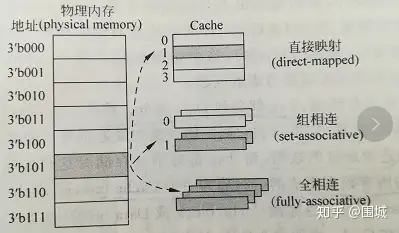
描述一个cache需要以下参数 :
1 cache分级,L1 cache, L2 cache, L3 cache,级别越低,离cpu越近
2 cache的容量
3 cache的linesize
4 cache 每组的行个数.
假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位)
倘若把内存地址分为以下三个区间:
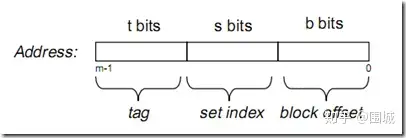
tag, set index, block offset三个区间有什么用呢?再来看看Cache的逻辑结构吧:
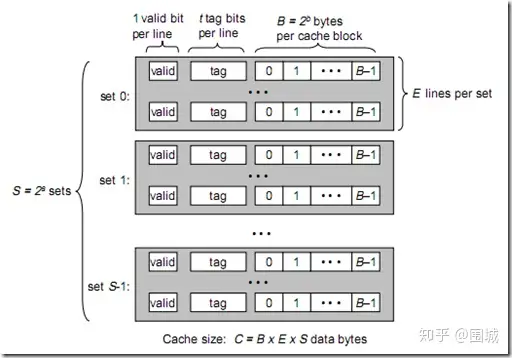
将此图与上图做对比,可以得出各参数如下:
B = 2^b
S = 2^s
现在来解释一下各个参数的意义:
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中,有B个存储单元,现代处理器中,这个存储单元一般是以字节(通常8个位)为单位的,也是最小的寻址单元。因此,在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功是,我们称为cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)。当不命中的情况发生时,系统就会从内存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。注意,以下这一点对理解linux cache机制非常重要:
高速缓存其实就是一组称之为缓存行(cache line)的固定大小的数据块,其大小是以突发读或者突发写周期的大小为基础的。
每个高速缓存行完全是在一个突发读操作周期中进行填充或者下载的。即使处理器只存取一个字节的存储器,高速缓存控制器也启动整个存取器访问周期并请求整个数据块。缓存行第一个字节的地址总是突发周期尺寸的倍数。缓存行的起始位置总是与突发周期的开头保持一致。
当从内存中取单元到cache中时,会一次取一个cacheline大小的内存区域到cache中,然后存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
下面看看cache的映射机制:
当E=1时, 每组只有一个cacheline。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cacheline中。(好好想想为什么?) 当1<E<C/B时,每组有E个cacheline,不同的地址,只要中间s位相同,那么就会被映射到同一组中,同一组中被映射到哪个cacheline中是依赖于替换算法的。 当E=C/B,此时S=1,每个内存单元都能映射到任意的cacheline。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
不管哪种映射,只要发生了cache miss,那么必定会有一个cacheline大小的内存区域,被取到cache中相应的cacheline。
现代处理器,一般将cache分为2~3级,L1, L2, L3。L1一般为CPU专有,不在多个CPU**享。L2 cache一般是多个CPU共享的,也可能装在主板上。L1 cache还可能分为instruction cache, data cache. 这样CPU能同时取指令和数据。
Лекция 1 - Подходы разработки архитектуры процессора
每个处理器厂商采用不同的方法设计处理器,内核会影响处理器的效率,因此公司追逐更多的内核。

需要注意的内容:
- 处理器具体型号,比如 i7-9700k (Модель процессора)
- 架构 (Архитектура)
- 代码名称 (Кодовое имя)
- 内核和线程数 (Число ядер и потоков)
- 各级高速缓冲存储器的大小 (Размер кэш-памяти всех уровней)
- 高速缓冲存储器的连接 (Связанность кэш-памяти)
- 所有高速缓冲存储器层的示意图 (Диаграмма всех уровней кэш-памяти)
Intel:
英特尔尝试采用 Tic-Tac 方法。每两年更新一次工艺技术。然而,近年来,这样的转型已经枯燥乏味。在转向 14 纳米工艺时,处理器包含了南桥(южный мост)功能,功耗降低。这一决定提高了移动设备的自主性。Skylake 架构采用了相同的工艺。与上一代产品相比,由于出现了两个芯片(插入了南桥),自主性再次下降。在购买移动解决方案时,优先考虑较低的技术工艺。后来,出现了处理器开发三步走的概念:先开发新架构,再优化架构,然后过渡到工艺(改变工艺技术)。现在,即使是这种方法也难以为继。
Многопоточность и гиперпоточность
https://www.zhihu.com/tardis/zm/art/352676442?source_id=1003
超线程(Hyper-Threading):
虽然现在超线程(Hyper-Threading)被大家广泛接受,并把所有一个物理核心上有多个虚拟核心的技术都叫做超线程,但这其实是Intel的一个营销名称。而实际上这一类技术的(学术/技术)通行名称是**同步多线程(SMT,Simultaneous Multithreading)**技术。SMT 技术初衷是通过提升CPU核心后端执行单元的利用率,来提升整体的并行性能。
Intel的SMT技术是我们认知最广泛的,早在2002年的Pentium 4上(应该是Pentium 4的E)和Xeon上,Intel就把SMT技术包装成Hyper Threading,并推向市场了。之后因为架构切换,在酷睿诞生初期暂停过一段时间,而自从Core i7 960这个划时代的酷睿后,就一直是Intel中高端CPU的标配了。 Intel的超线程一直都是SMT2,也就是一个物理核心虚拟出两个核心,也就是逻辑核心。 AMD最新的Zen系列CPU,也同样加入了SMT2的超线程,现在超线程技术可以说是PC和服务器CPU的标配了。
SMT为什么能提升并行性能(多线程性能)?
SMT同步多线程具有多个执行单元,CMT(芯片多线程)和FMT都是在单个执行单元下的技术,不同的线程在指令级别上并不是真正的“并行”,而SMT则具有多个执行单元,同一时间内可以同时执行多个指令,可以充分发掘超标量处理器的潜力,因此SMT具有最大的灵活性和资源利用率,不过处理器也更复杂。
相比物理多核心,SMT有什么优势?
增加物理核心,以及加入SMT都是提升多任务性能的方式。但为什么现在核心那么多了,还依旧会有SMT? 因为相比于增加物理核心,使用SMT来的更加廉价。因为SMT提供的是虚拟核心,所有虚拟核心共享很大一部分的资源,通常加入SMT技术只需要在前端额外增加一部分资源(毕竟两个任务是两个上下文)就可以。例如Intel曾经就披露过,奔腾4增加HT技术只需要多花费5%的核心面积,就可以增加15-30%的多线程性能,而如果增加物理核心,增加多少性能,就至少要增加多少比例的核心数量,性价比显然不如SMT。
SMT有什么代价?
天下没有免费的午餐,SMT技术带来多线程性能进步的同时,势必也会引入一些负面的影响。大体有如下一些:
- 多线程维护开销:我们上面的例子中比较理想的展示了SMT的效果,但也没展现出SMT的一些代价。一个物理核心如果引入多个线程,那么是要协调、隔离多个线程的,这会引入额外的开销。所以最理想的情况下,如果一个核心有两个线程,那么两个线程的总执行时间会更快,但是如果细分到每一个线程的执行时间,会比分别执行来的慢一些。
- 资源冲突:此外,在SMT核心中,因为多个逻辑核心会共享很多资源,如果两个线程的性质比较接近,总是在使用类似的资源,那么它们会遭遇资源冲突。程度轻一点的情况下,互相等待一下就好,多牺牲一点单线程性能,还能保证多线程效率。而差一点的情况就是资源冲突反而导致性能下降,最典型的冲突就是缓存的冲突,一个线程可以用100%的缓存,而超过一个线程使用同一个缓存,可用缓存就不是100%,会导致大量开销极大的缓存-内存换入换出。只要有一个线程是非常吃缓存的,那么加入SMT不但不会提升总的执行效率,反而会降低整体的效率。SMT非常忌讳不同线程的资源冲突,一但冲突SMT就很容易引入反面效果。比如在很多云服务器、HPC服务器上,SMT通常是关闭的,就是因为资源冲突。
- 线程安全问题:两个线程在同一个核心内执行,是需要严格隔离它们的上下文的,线程A不能访问修改其他线程的资源。线程隔离是一个非常复杂和繁琐的过程,如果隔离不彻底,那么会导致执行错误、以及隐私泄漏的问题。Intel前两年Skylake爆发的若干安全漏洞,就是因为线程隔离不到位造成的。
- 导致功耗增加:SMT整体的思路是略微牺牲单核性能/能耗比,换取大多数情况下的多线程时的单核性能和能耗比,那么对应的加入SMT后单核的能耗比会有些许倒退。由于引入SMT会导致核心设计更加复杂,静态功耗、漏电会更难控制,这对于移动设备是致命的。这也是为什么SMT在PC和服务器上大行其道这么多年,手机上几乎看不到的原因。
多线程与超线程区别:
多线程与超线程的不同之处在于,在**超线程 (Hyper-Threading, гиперпоточность)**情况下,可以在以下条件下通过内核传递两个线程:这些线程需要不同的硬件。一个是 ALU,另一个是浮点模块。 超线程需要准备相当复杂的代码。因此,我们不应该太关注这种方法。
- L1 - 最快的是 L1 一级高速缓冲存储器。i-n 系列 intel 处理器的区别首先在于高速缓冲存储器的大小。
- L2 - 第二级高速缓冲存储器不分指令和数据,容量也很小。
- L3 - 三级高速缓冲存储器由所有四个内核共享。高速缓冲存储器位于芯片 CPU上。
(Основы) векторизация кода
- Применение знаний и умений по написанию кода на языке высокого уровня для современных архитектур процессоров 为现代处理器架构应用高级语言编写代码的知识和技能
- Применяется в технологиях программирования и без регулярного программирования 适用于无常规编程的编程技术
- Регулярное программирование позволяет легче задействовать векторизацию 常规编程使矢量化更容易使用
程序指标:
Показатели ПО
-
代码质量 (качества кода)
-
代码性能 (Производительность кода Perf, code perfomance)
-
代码性能/效率 $$ Perf = 1 / T[c^{(-1)}] $$
-
内存消耗 (Потребление памяти Mem, memory consumption)
-
支持现代微架构 (Поддержка современных микроархитектур)
-
代码复杂性 (Сложность кода Compl),这是一个量化指标,比如代码行数,不包括注释 $$ Compl – LOC , \ Compl = Cycl $$
-
代码行数 (Число строк кода LOC, Lines of a code)
-
循环复杂度(Цикломатическая сложность кода Cycl, cyclomatic complexity of a code),它在测试中得到了很好的应用。这些指标与开发人员息息相关。它显示了程序代码中与行无关的路径数量。如果出现分支,代码复杂度将增加 1 或出现分支的周期长度
-
-
代码效率 (Эффективность кода)
-
代码生产效率(Эффективность кода Prod, code productivity)。
如果在性能相当的情况下,代码量是原来的两倍,那么效率就是原来的一半
如果代码的生产率提高了一倍,体积增大了一倍,其效率却没有提高
还可以在分母上加上:代码消耗的内存、上市时间、开发成本 $$ Prod = Perf / Compl = 1 / (T · Compl) $$
-