- Build something cool with Neo4j under the theme graphs4good
- Register your project and team here
- Present your project
- Win cool prizes
Network: ---- Passsword: ----
| 6:00-6:30 | Arrive |
| 6:30-7:00 | Introduction, form teams, start hacking |
| 7:00-9:00 | Hacking |
| 9:00-9:30 | Teams present |
| 10:00 | Prizes / Awards |
Teams!
- Teams are encouraged, but individual participation is allowed.
- Teams may have up to 5 participants, but only 4 prizes are awarded per team.
- Register your project and all team mates here
Winners
- Most impactful idea
- Best complete application
- Best data visualization
- Best use of Cypher
Criteria for judging - all projects must use Neo4j
- Creativity (perhaps including merging disparate data sources)
- Use of Cypher and Neo4j
- Interesting new information uncovered
- Quality of presentation (perhaps including visualization)
- Completeness
Prize Distribution
- A variety of prizes will be on display throughout the event
- Each member of winning teams may choose (1) prize
- First place team will be announced and choose prizes first, followed by 2nd place team, followed by 3rd place team
- As long as prize inventory allows, honorable mention teams will be announced and be able to choose prizes
- Each prize is limited in quanity. Within each winning team, individuals will need to decide who gets which prize.
- Airpod
- Echo Show
- Nest Camera
- BB8 Droid
- Google Home
- Echo Dot
- Exclusive GraphHack T-shirts!
The Humanitarian Data Exchange is an open platform for sharing data, launched in July 2014. The goal of HDX is to make humanitarian data easy to find and use for analysis.

- bit.ly/foodgraph
- username: foodgraph
- password: foodgraph
- bit.ly/fakenewsgraph
- username: fakenewsgraph
- password: fakenewsgraph

NOTE: This dataset has an interactive Neo4j Browser guide for exploring the data:

- Neo4j Sandbox
:play http://guides.neo4j.com/legisgraph

- Available on Neo4j Sandbox with this link, then look for "IRE 2017 Workshop" use case.

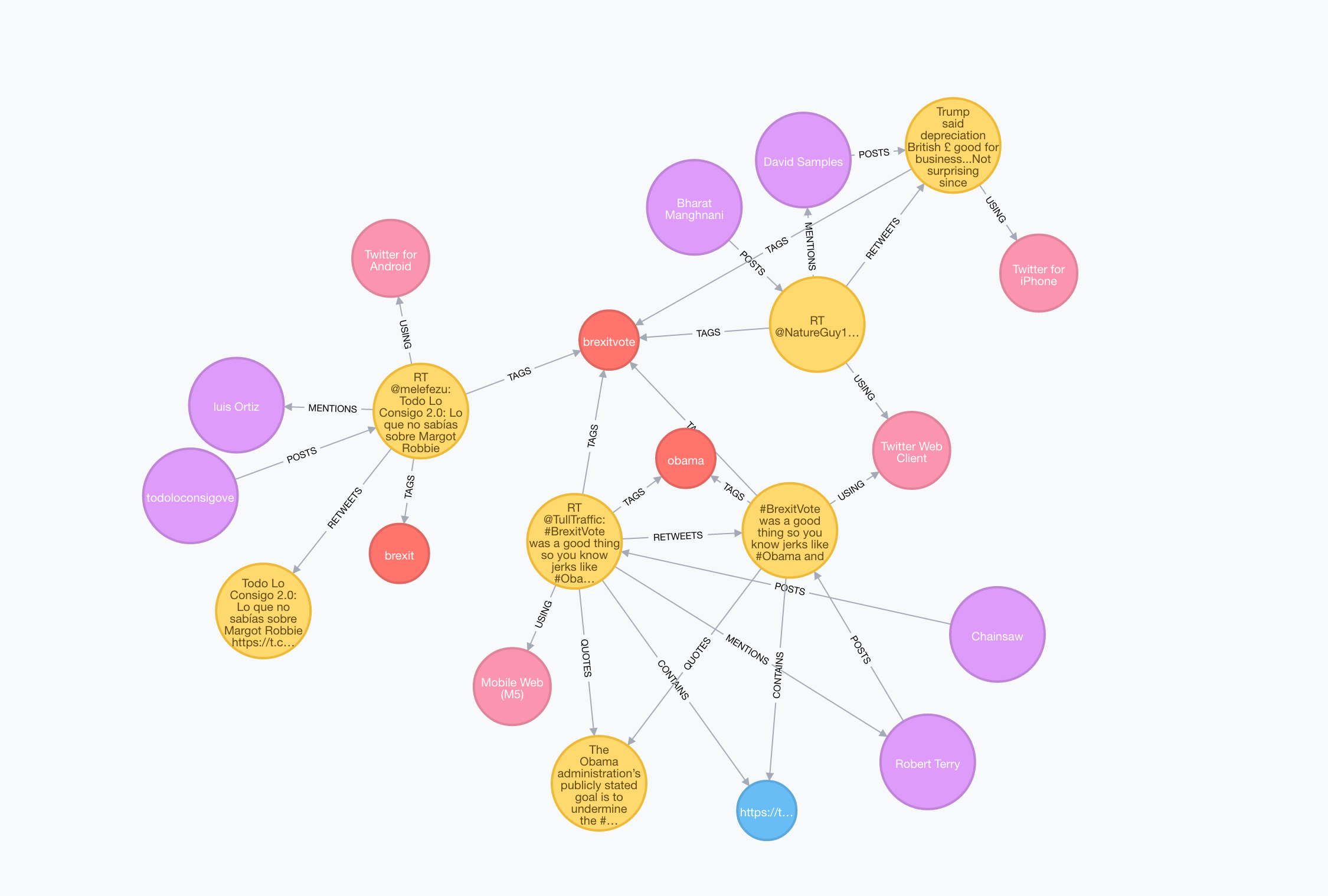
Download
wget http://demo.neo4j.com.s3.amazonaws.com/electionTwitter/neo4j-election-twitter-demo.tar.gz
tar -xvzf neo4j-election-twitter-demo.tar.gz
cd neo4j-enterprise-3.0.3
bin/neo4j start
NOTE: This dataset has an interactive Neo4j Browser guide for exploring the data:

Fivethirtyeight has made the data behind their famous election forecast publicly available:
http://projects.fivethirtyeight.com/2016-election-forecast/summary.json
You can easily pull this into Neo4j using apoc.load.json:
CALL apoc.load.json("http://projects.fivethirtyeight.com/2016-election-forecast/summary.json") YIELD value AS data
RETURN data
// Creating the graph
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://s3-us-west-2.amazonaws.com/neo4j-datasets-public/Emails-refined.csv" AS line
MERGE (fr:Person {alias: COALESCE(line.MetadataFrom, line.ExtractedFrom,'')})
MERGE (to:Person {alias: COALESCE(line.MetadataTo, line.ExtractedTo, '')})
MERGE (em:Email { id: line.Id })
ON CREATE SET em.foia_doc=line.DocNumber, em.subject=line.MetadataSubject, em.to=line.MetadataTo, em.from=line.MetadataFrom, em.text=line.RawText, em.ex_to=line.ExtractedTo, em.ex_from=line.ExtractedFrom
MERGE (to)<-[:TO]-(em)-[:FROM]->(fr)
MERGE (fr)-[r:HAS_EMAILED]->(to)
ON CREATE SET r.count = 1
ON MATCH SET r.count = r.count + 1;
// Updating counts
MATCH (a:Person)-[r]-(b:Email) WITH a, count(r) as count SET a.count = count;

The Fivethirtyeight teams does an amazing job of providing the data behind many of their stories in their Github repo. There are a lot of possibilities but here are a few ideas we hacked up:
Import
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/fivethirtyeight/data/master/hip-hop-candidate-lyrics/genius_hip_hop_lyrics.csv" AS row
MERGE (c:Candidate {name: row.candidate})
MERGE (a:Artist {name: row.artist})
MERGE (s:Sentiment {type: row.sentiment})
MERGE (t:Theme {type: row.theme})
MERGE (song:Song {name: row.song})
MERGE (line:Line {text: row.line})
SET line.url = row.url
MERGE (line)-[:MENTIONS]->(c)
MERGE (line)-[:HAS_THEME]->(t)
MERGE (line)-[:HAS_SENTIMENT]->(s)
MERGE (song)-[:HAS_LINE]->(line)
MERGE (a)-[r:PERFORMS]->(song)
SET r.data = row.album_release_date


Many governments use the Socrata data portal software to make their data (i.e. crime, transportation, etc) available. This means that we can use apoc.load.json to import data directly from any Socrata site. For example, to import San Francisco crime data:
CALL apoc.load.json("https://data.sfgov.org/resource/cuks-n6tp.json?$limit=5000&$offset=0") YIELD value AS crime
MERGE (c:Crime {incidntnum: crime.incidntnum})
ON CREATE SET c.address=crime.address, c.time=crime.time, c.dayofweek=crime.dayofweek
MERGE (cat:Category {name: crime.category})
CREATE (c)-[:HAS_CATEGORY]->(cat)
MERGE (dis:District {name: crime.pddistrict})
CREATE (c)-[:OCCURRED_IN]->(dis);
Beyond the resources listed above.
We don't have Neo4j import scripts or graph exports for these, but we think they might be interesting to explore:
You'll need to use Neo4j to participate in the hackathon. You can download Neo4j here or use one of the hosted versions above.
Graph algorithms, data import, job scheduling, full text search, geospatial, ...
Grab your friendly Neo4j staff and community members if you have any questions.