MNIST (Modified National Institute of Standards and Technology)
Beschreibt die Eigenschaften von Eingabedaten, z.B:
- Pixelwerte in einenm Bild
- Zanhlenwerte wie Umsatz, Alter, Anzahl,...
- Bestimmte Buchstaben in einem Dokument
- ...
Die anzahl an möglichen Features ist dabei nicht limitiert

- Ausrichten der Features auf den Bildausschnitt.
- Multiplikation eines jeden Bildpixel mit dem zugehörigen Feature-Pixel
- Addition der Produkte.
- Teilen durch die Gesamtzahl der Pixel des Features.
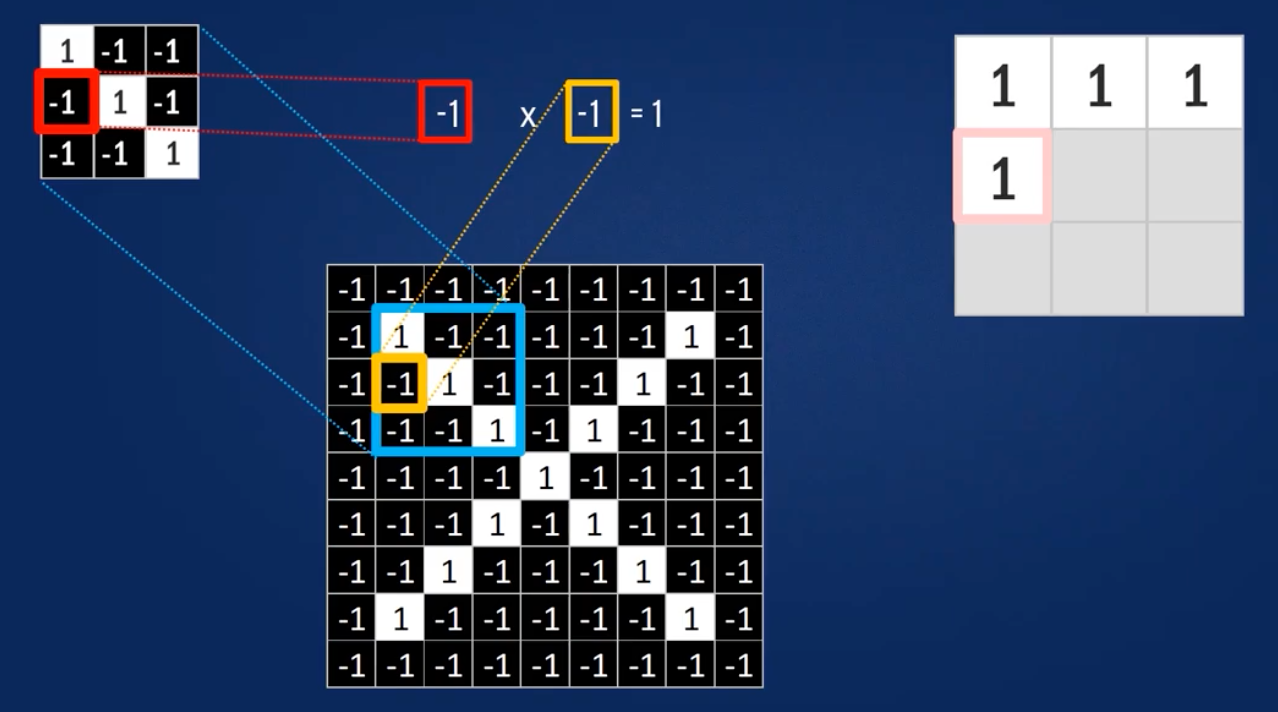
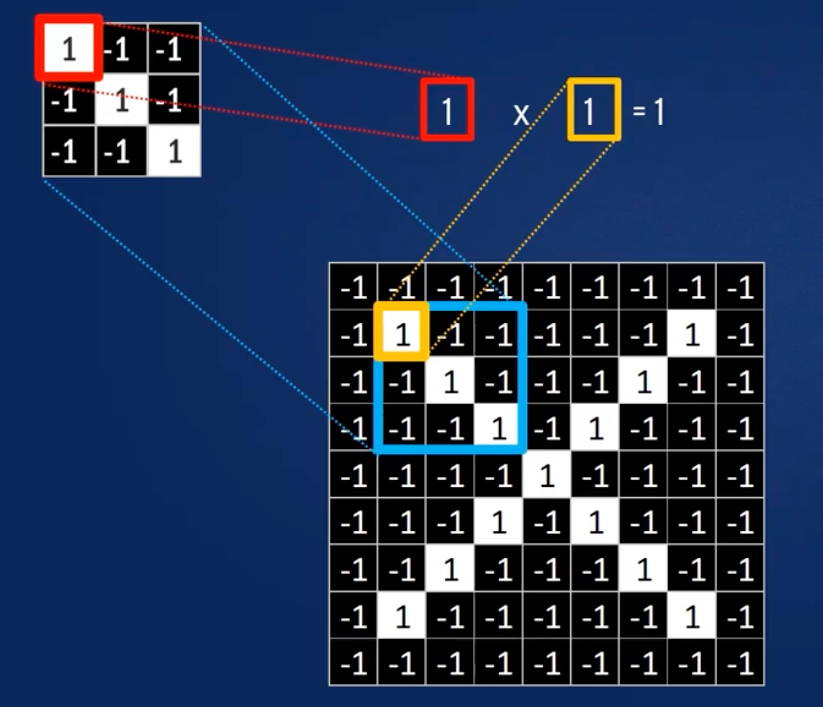
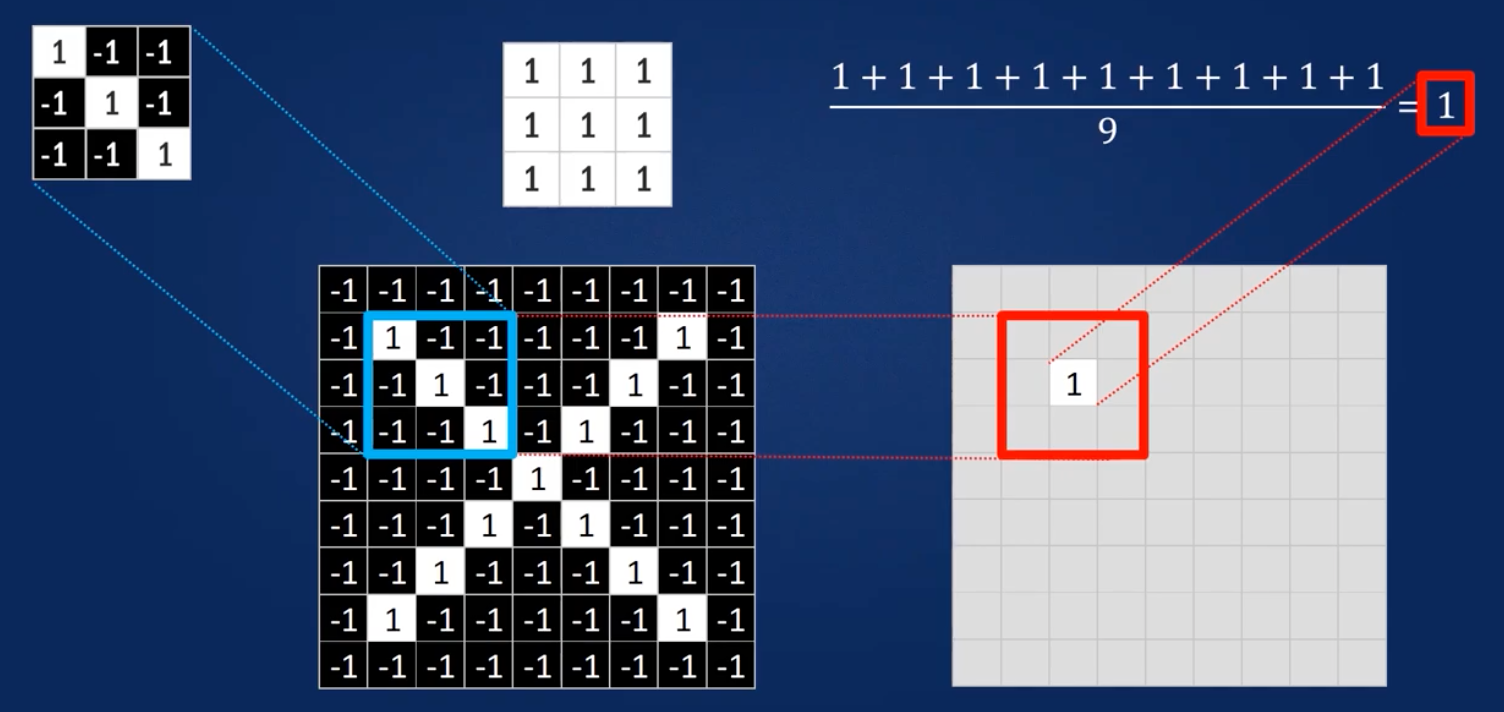





Pürfen auf alle möglichen Übereinstimmungen



- Feature + convolution => feature-map
Ein Bild wird zu einem Stapel gefilterter Bilder


Verkleinern des Bildstapels
- Wählen einer Fenstergröße (normaleweise 2x2px oder 3x3px)
- Wählen einer Schnittweite (typisch: 2px)
- Mit dem Fenster über die gefilterten Bilder "gehen"
- Aus jedem Fenster den Maximalwert nehmen


Wir behalten bestimmte Merkmale, auch wenn das Bild nicht perfekt ist

- Reduktion von Rechnemaufwand durch Modifikation einzelner Werte.
- Negative Zahlen werden auf Null (0) gesetzt.



Das Ergebnus einer Schicht wird zur Eingangsinformation (Input) der nächsten Schicht

Ebenen können einige (oder auch viele) Male wiederholt werden

=> Frage: wie kommmen wir zu Ergebniss ?
Jeder Wert ist stimmberechtigt in Bezug auf das Ergebnis
 Zukünftige Werte stimmen für X oder O ab
Zukünftige Werte stimmen für X oder O ab
 Eine Liste von Features wird zu einer Liste von Stimmen
Eine Liste von Features wird zu einer Liste von Stimmen
 Diese können auch gestapelt werden
Diese können auch gestapelt werden
 Ein Satz von Pixel wird zu einem Satz von Stimmen
Ein Satz von Pixel wird zu einem Satz von Stimmen

(None, 244, 244, 3) => Eingabeformat 244x244 Px, RGB: 3
(None, 224, 224, 64) => Features: 64
in der ausgabe sehen wir:
- Bildgrösser werden verkleinert
- Anzahl der Features zunehmmen => immer mehr details
###Interessant: Total params: 138,357,544
- Features in convolutional layers
- Voting weights in fully connected layers
Fehler = richtige Anwort - aktuelle Antwort

Für jedes Features-Pixel und jde Gewichtung (weight) passen wir das Gewicht ein wenig nach oben und unten an und sehen,
wie der Fehler sich ändern



Den Slope direkt berechnen

Lernrate ist zu klein und benötigt zu viel Rechnenleistung

Lernrate ist zu gross und verhält sich unvorhersehbar

Erreicht schnell niedrige Fehlerwerte

Erreicht schnell niedrige Fehlerwerte


- Anzahl der Features
- Größe der Features
- Fenstergröße
- Fensterschnitt
- Anzahl der Neuronen
- Wie viele von jeden Layer ?
- in welcher Reihensfolge ?
- Alle 2D- (oder 3D-) Daten
- Dinge, die näher beieinander liegen, sind enger miteinander verbunden als Dinge, die weit weg sind



- ConvNets erfassen nur locale "räumliche" Muster in Daten
- Wenn die Daten nicht wie ein Bild aussehen können, sind ConvNets weniger nützlich
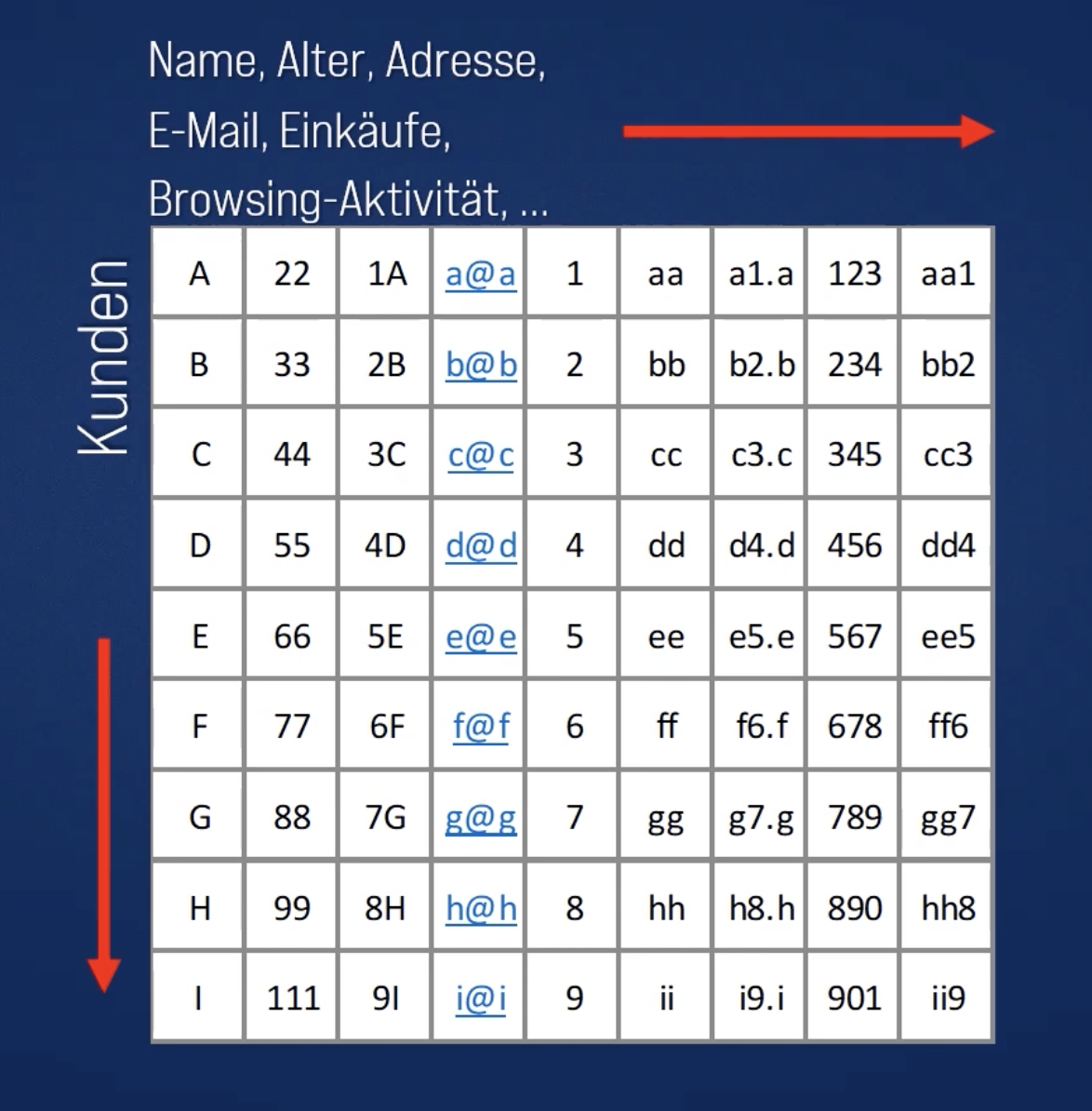

Wenn die Daten genauso nutzlich sind, nachdem wir eine Ihrer Spalten miteinander vertauscht haben, dann können wir Convolutional Neural Networks nicht verwenden CNN sind hervorragend darin, Muster zu finden und damit Bilder zu klassifizieren.