Exploring the design surface of ACE for crystal deep learning
Facet is an E(3) equivariant graph neural network framework for crystal property prediction. Specifically, current work is on predicting energy, forces, and stress in materials.
It uses a message passing architecture with steerable representations of SO(3), following the broad structure of MACE. By using these steerable representations, we can achieve the same effect as many-body interactions in conventional GNN architectures like GemNet with a smaller computational and architectural burden.
This repository implements a JAX/Flax neural network architecture based on
MACE and SevenNet. It is
built from the ground up, starting from e3nn and Flax.
Using JAX, we can safely use irreps and compute equivariant tensor products without any runtime cost. JAX also enables efficient parallelism. Testing on 3 RTX 3090 GPUs, I achieve 95+% GPU utilization throughout training with only a few lines of code.
This repository also contains my exploration of the design surface of MACE-family architectures. Early work shows significant gains over SevenNet and MACE in early training, although of course any pronouncements must wait for models trained at scale.
When the library is ready for production use, it will be containerized and packaged. Until then,
installation is a DIY process. You will need to first install JAX and GPU support. The reqs.txt
file should contain the necessary libraries, along with
pip install --editable .Data is processed using the scripts in scripts/, but that's not an exact science yet. Due to
JAX's requirement that code have static shapes to avoid recompilation, packing the graphs into
batches currently requires some manual intervention. File an issue or contact me directly at
nmiklaucic@sc.edu if you would like guidance or preprocessed data.
Credit to CHGNet for compiling the MPTrj dataset.
I am currently working on a pipeline that will download and preprocess everything without any user intervention.
For the best experience, it's recommended to use Neptune logging. The
env.sh and secrets_template.sh files indicate what environment variables you need. Fill in your
API key in secrets_template.sh and save that to secrets.sh. Then, run source env.sh to set up
the environment variables.
Everything is run from a configuration file. Check configs/default.toml to see the default
options and facet/configs/ to see the different options with some documentation. To check that a
configuration works, you can run
python facet/show_model.py --config_path=configs/your_config.tomlThis should print out a very detailed description of the model, an example of which can be found in
reports/model.html.
When that looks good, you can run
python facet/train_e_form.py --config_path=configs/your_config.tomlFor local use, I have a dashboard that works entirely within the terminal! You can set the config options within your config file, but you can also pass overrides in directly. So, if you want to run a config file without logging to Neptune and with a dashboard showing the metrics, you can run
python facet/train_e_form.py --config_path=configs/your_config.toml --display=dashboard --debug_mode=trueYou'll get a terminal that looks something like this:
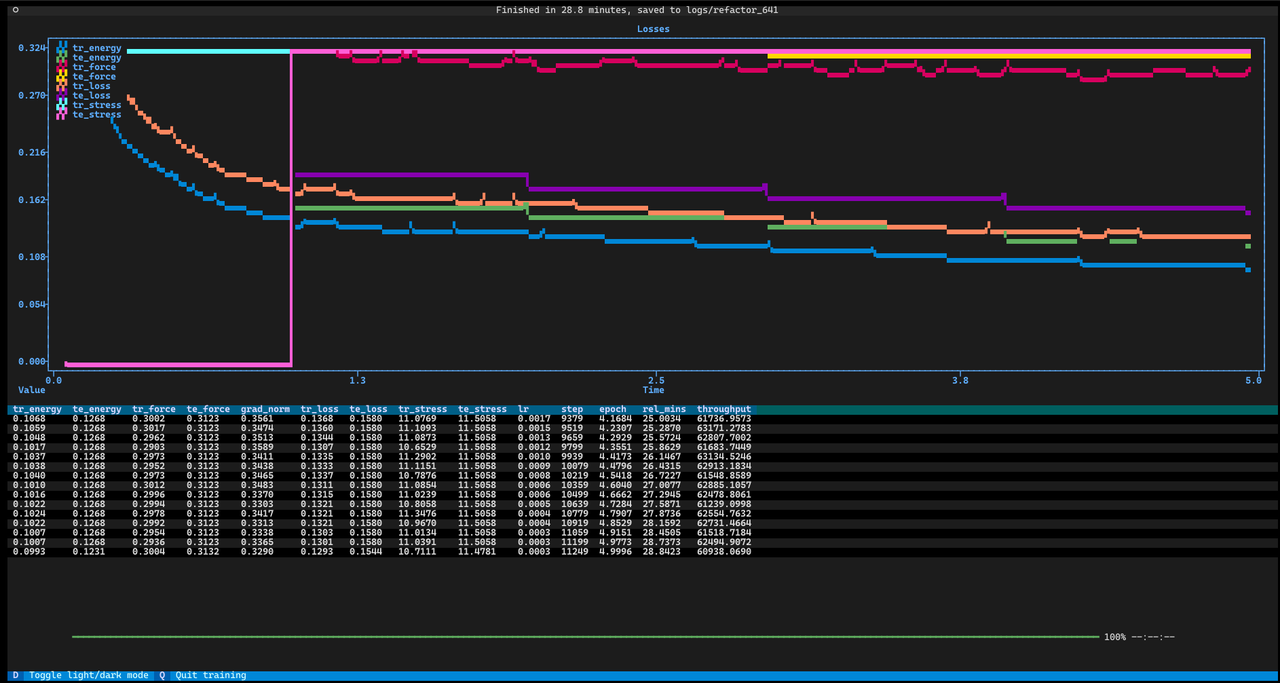
Neptune really is nicer, so I wouldn't recommend this for continual testing, but it will let you debug coding issues without polluting your experiment tracking repository.
The code in facet/ is where the stuff I'm running repeatedly goes: the model, layer, trainer API,
dashboard, etc. Code in that folder that does not work is considered a bug.
The code in notebooks/ has some stuff that may be useful to an observer: embedding_visual.ipynb
has a useful interface for understanding what's going on internally, and model_visualization.ipynb
is a WIP use of treescope to view models in more depth. However, many of those notebooks are for
exploratory purposes. Do not assume that code in there is correct, up to date, or what the code in
facet/ does.
The scripts/ directory contains one-off scripts that don't need to be run multiple times, mostly
for data preprocessing. They are not thoroughly tested, because I plan to replace them with a more
rigorous pipeline, but you will need them for now.
File an issue or contact me: either through this GitHub account or at nmiklaucic@sc.edu.
I work in the Machine Learning and Evolution Lab at the University of South Carolina, to which I am greatly indebted for support and counsel. Any and all mistakes within this code are purely my own.