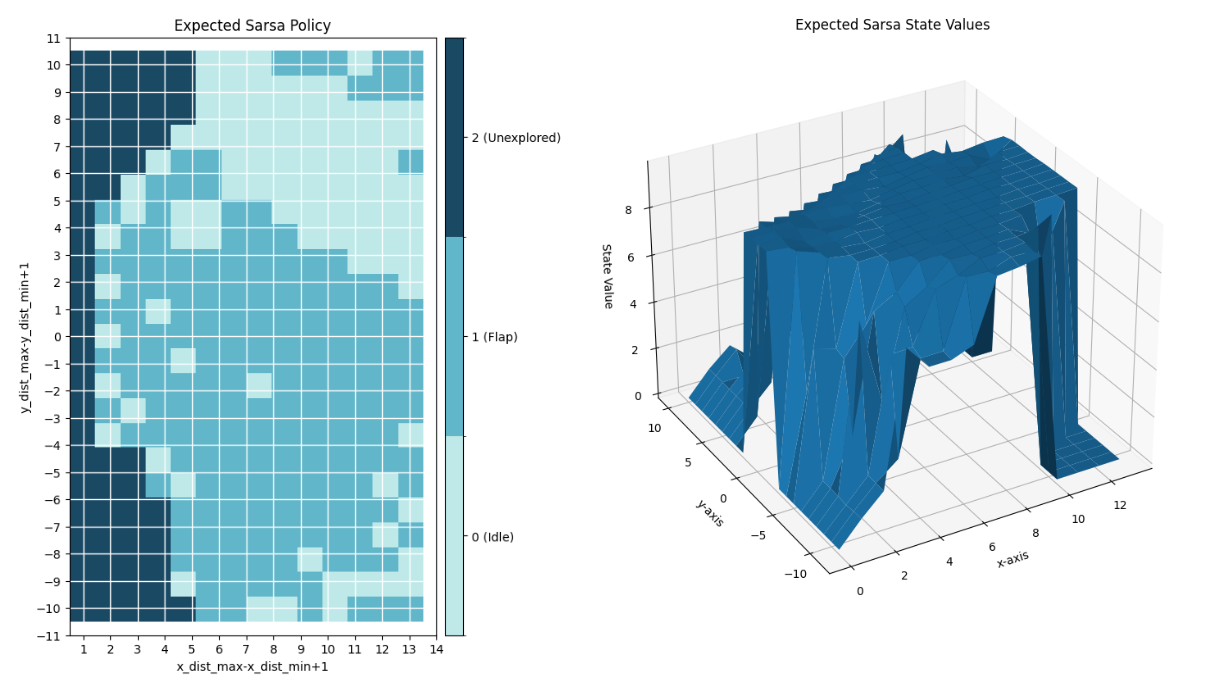
This project implements two different reinforcement learning algorithms for the Flappy Bird Gym environment. The two algorithms used are Expected SARSA and Deep Q Learning.

To get started, you'll need to have the following installed:
- Python 3.x
- OpenAI Gym
- PyTorch
You can install the required packages using conda:
conda create -f environment.yml
To run the code, simply clone the repository and navigate to the main directory. Then, run the following command:
python3 main.py -agent dqn
The above command will run the Deep Q Learning algorithm on the Flappy Bird Gym environment. The -render flag will render the game in your terminal. To run the Expected SARSA algorithm, simply replace dqn with expected_sarsa.
To train the agent, simply add the -train flag to the command above. For example, to train the Deep Q Learning agent, run the following command:
python3 main.py -agent dqn -train
The above command will train the Deep Q Learning agent for the number of iterations indicated in the configuration file. To train the Expected SARSA agent, simply replace dqn with expected_sarsa.
To change the hyperparameters, simply edit the files in the config dir, depending on if you want to simulate one run or perform a full sweep on hyperparams. The hyperparameters are as follows:
-
Expected SARSA
NUM_ACTIONS: The number of actions the agent can take.NUM_EPISODES: The number of episodes to train the agent for.NUM_STEPS: The number of steps to run the agent for.STEP_SIZE: The step size for the agent.EPSILON: The epsilon value for the epsilon-greedy policy.DISCOUNT: The discount factor for the agent.
-
Deep Q Learning
NUM_ACTIONS: The number of actions the agent can take.STATE_SIZE: The size of the state vector.NUM_EPISODES: The number of episodes to train the agent for.EPSILON_START: The epsilon value for the epsilon-greedy policy at the start of training.EPSILON_END: The epsilon value for the epsilon-greedy policy at the end of training.EPSILON_DECAY: The decay rate for the epsilon value.DISCOUNT: The discount factor for the agent.BATCH_SIZE: The batch size for the Deep Q agent.REPLAY_BUFFER_SIZE: The size of the replay memory for the Deep Q agent.SEED: The seed for the random number generator.TAU: The soft update parameter for the target network.LR: The learning rate for the agent.
You can find the results & models for the trained agents in the results dir.