September 2, 2017
Doing the New York Times Crossword is the closest thing I have to an evening ritual. Most of the time, I'll tackle it before the day actually arrives - they launch at 10pm the night before (except Sunday's, which launches at 6pm on Saturday).
Other people have already done pretty cool explorations of crossword text data. They've looked at at comparisons to the Oxford English Dictionary and the Google Books corpuses (corpi?) respectively. My favorite piece so far: last year, the NYTimes themselves published an interactive piece exploring the changing meanings of clues over the years.
Meanwhile, my goal here (aside from indulging my inner crossword geek) is to try out a few new packages: website scraping with rvest and wrangling text data with tidytext.
I didn't scrape NYTimes.com itself. Why? Because crosswords tend to arrive blank, and I wanted answers. Instead, I used the rvest package and Selector Gadget to gather historical puzzle data from the amazing resource that is XWord Info.
Although the NYTimes crossword has been around since far earlier than 1994, I chose to only look at puzzles from the Will Shortz era (1994 - present). I've chosen not to host the data here, but the scraper code is available as part of this repository.
Starting off with something easy. What words pop up most frequently?
## # A tibble: 5 × 2
## word n
## <chr> <int>
## 1 ERA 514
## 2 AREA 458
## 3 ERE 428
## 4 ONE 425
## 5 ELI 411
It looks like ERA is our winner, with 514 appearances since 1994, with AREA, ERE, ONE and ELI filling out the top 5. It's unsurprising that these are all short, vowel-heavy words. They're likely used as short fillers between the longer, more inflexible feature words.
What about their frequency of use over time? Have some of these common words become more or less frequent? Plotting each word's number of appearances by year:
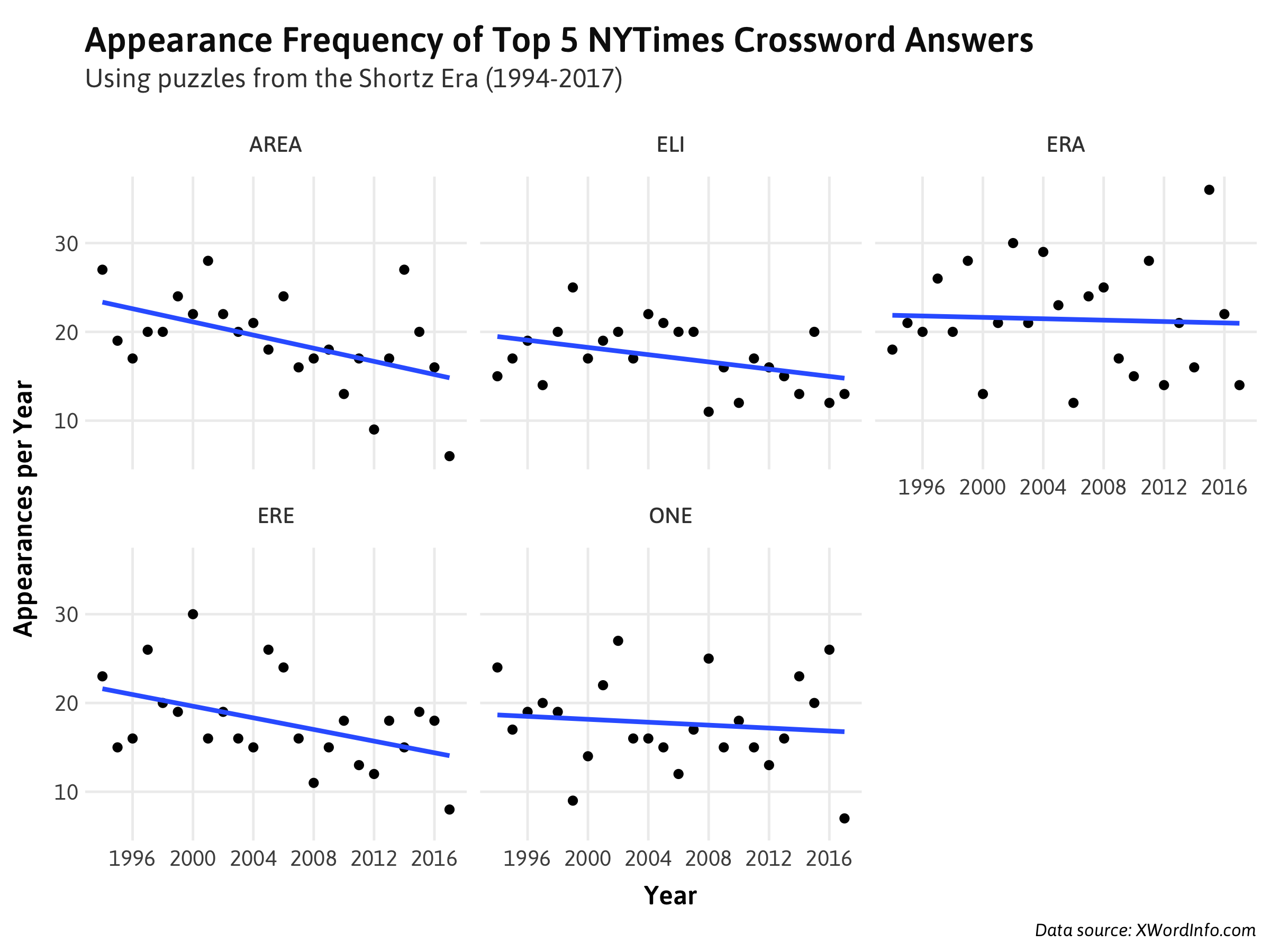
Short of a slight downward trend, nothing really convincing yet. What about the nature of the words themselves?
Calculating the average length of all the crossword answers in each year, then plotting them:
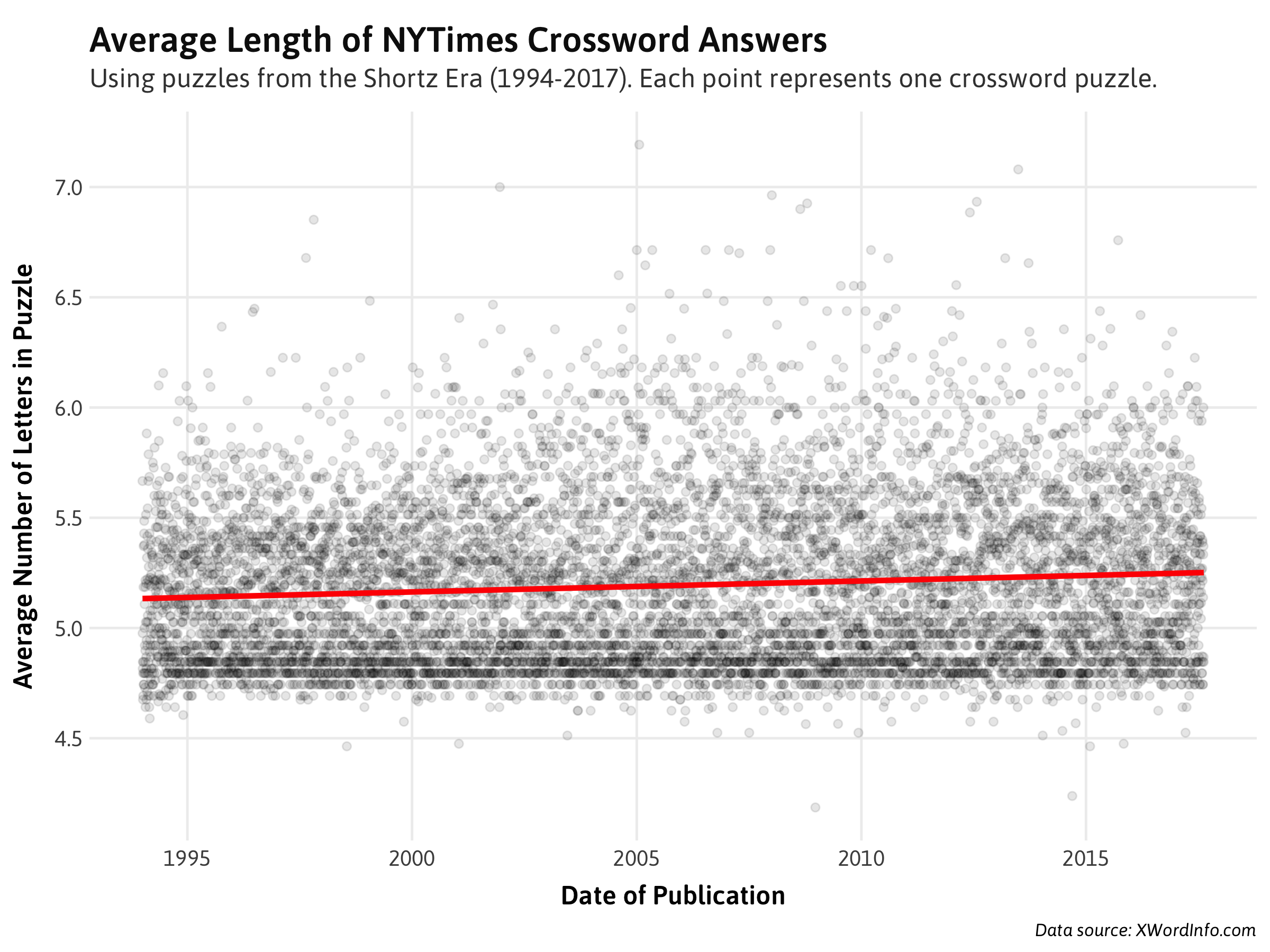
A weakly positive relationship, but this doesn't tell us much. Monday puzzles are designed to be far easier than Saturday puzzles, so it's likely that variation in word length between days will be far greater than within them. Plotting the average word length by day of the week, then year:
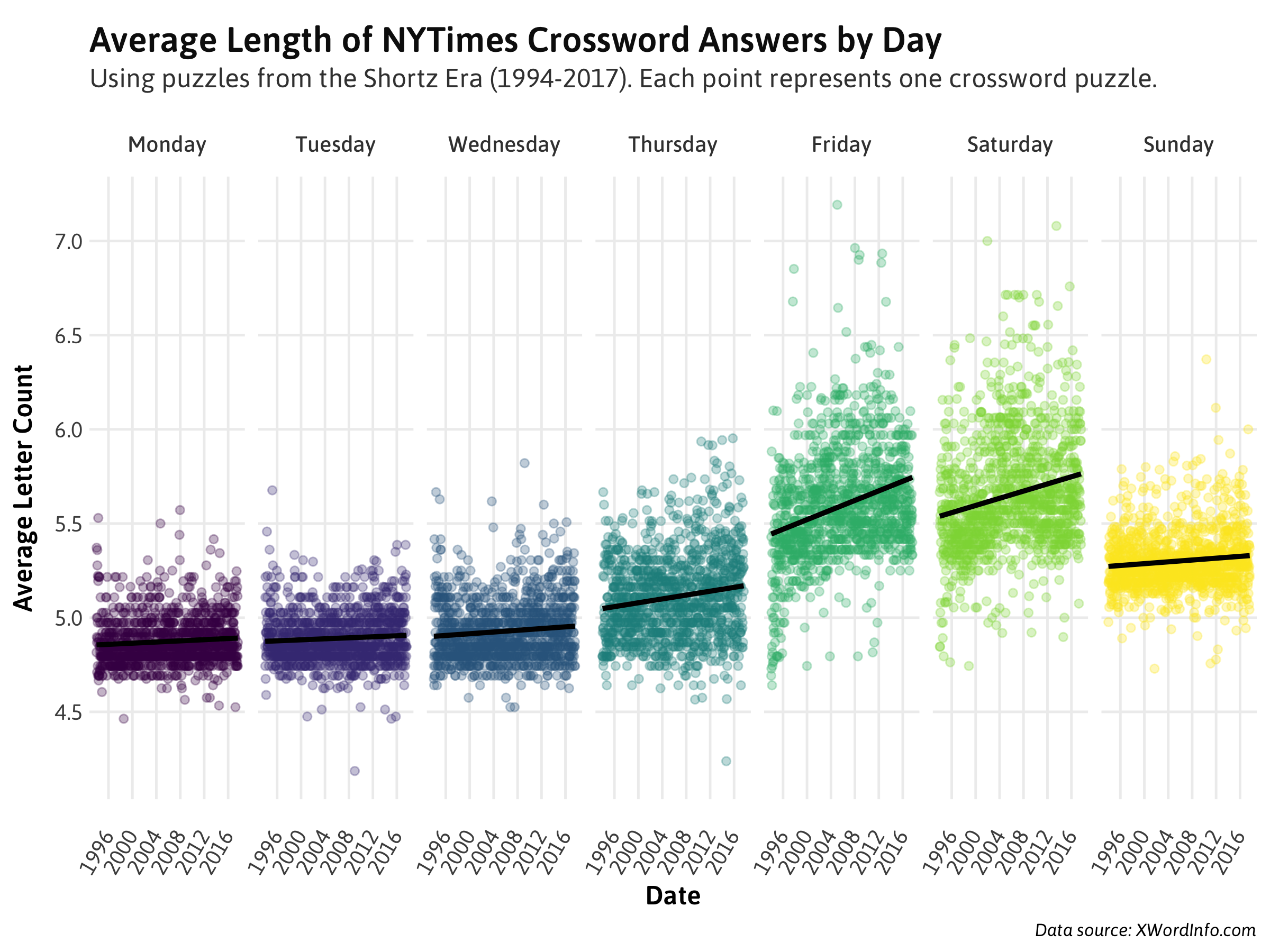
Now we're getting somewhere. A few observations:
- You can see a puzzle's intended complexity reflected in the average word length for each day.
- Friday and Saturday words seem to be growing longer on average much faster than that of other days'.
- Sunday words, while described as comparable to Wednesdays or Thursdays in terms of difficulty, are probably a little longer on average to account for the larger grid.
When different words or phrases enter the lexicon, it's only a matter of time before they're referenced in popular media. I wanted to find the words that only became popular (in terms of the crossword) in recent years.
To do this, I'm leveraging the concept of term frequency-inverse document frequency (td-idf). From Julia Silge's also-amazing resource, Text Mining with R:
The statistic tf-idf is intended to measure how important a word is to a document in a collection (or corpus) of documents, for example, to one novel in a collection of novels or to one website in a collection of websites.
If we treat each year as separate "documents", we should be able to figure out what words are most important to each year. This is easily done using tidytext::bind_tf_idf:
## # A tibble: 412,230 × 6
## year word n tf idf tf_idf
## <int> <chr> <int> <dbl> <dbl> <dbl>
## 1 2017 BAE 4 0.0002075765 3.178054 0.0006596894
## 2 2015 BLANKS 8 0.0002590170 2.484907 0.0006436331
## 3 2000 TTTT 8 0.0002568548 2.484907 0.0006382602
## 4 2017 LGBT 5 0.0002594707 2.079442 0.0005395541
## 5 2017 IDRISELBA 3 0.0001556824 3.178054 0.0004947671
## 6 2016 LAIDITONTHELINE 4 0.0001296849 3.178054 0.0004121455
## 7 2016 ROMCOM 4 0.0001296849 3.178054 0.0004121455
## 8 2017 ABBACY 3 0.0001556824 2.484907 0.0003868563
## 9 2017 ETSY 4 0.0002075765 1.791759 0.0003719272
## 10 2017 NSFW 4 0.0002075765 1.791759 0.0003719272
## # ... with 412,220 more rows
Some curious results already, but we'll have to dig deeper to get anything particularly interesting.
Plotting the words most important to the last 5 years:
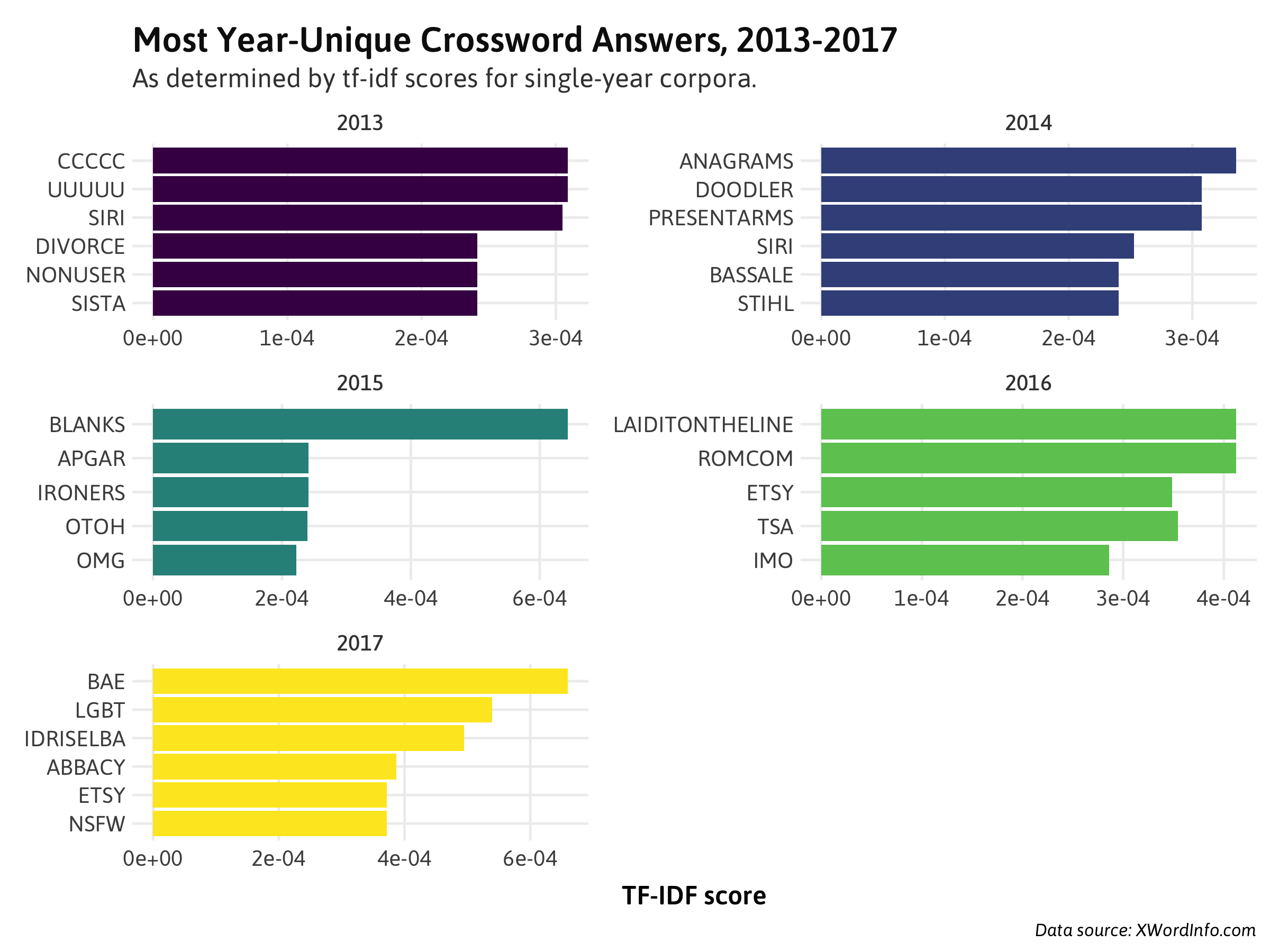
There you have it: 2017 is the year of the #BAE. In fact, it's been used as an answer this year four whole times so far, and not once before. But what does identifying a word as "important" to a particular document actually look like in terms of appearance frequency? Plotting how often each of 2017's important words appeared by year:
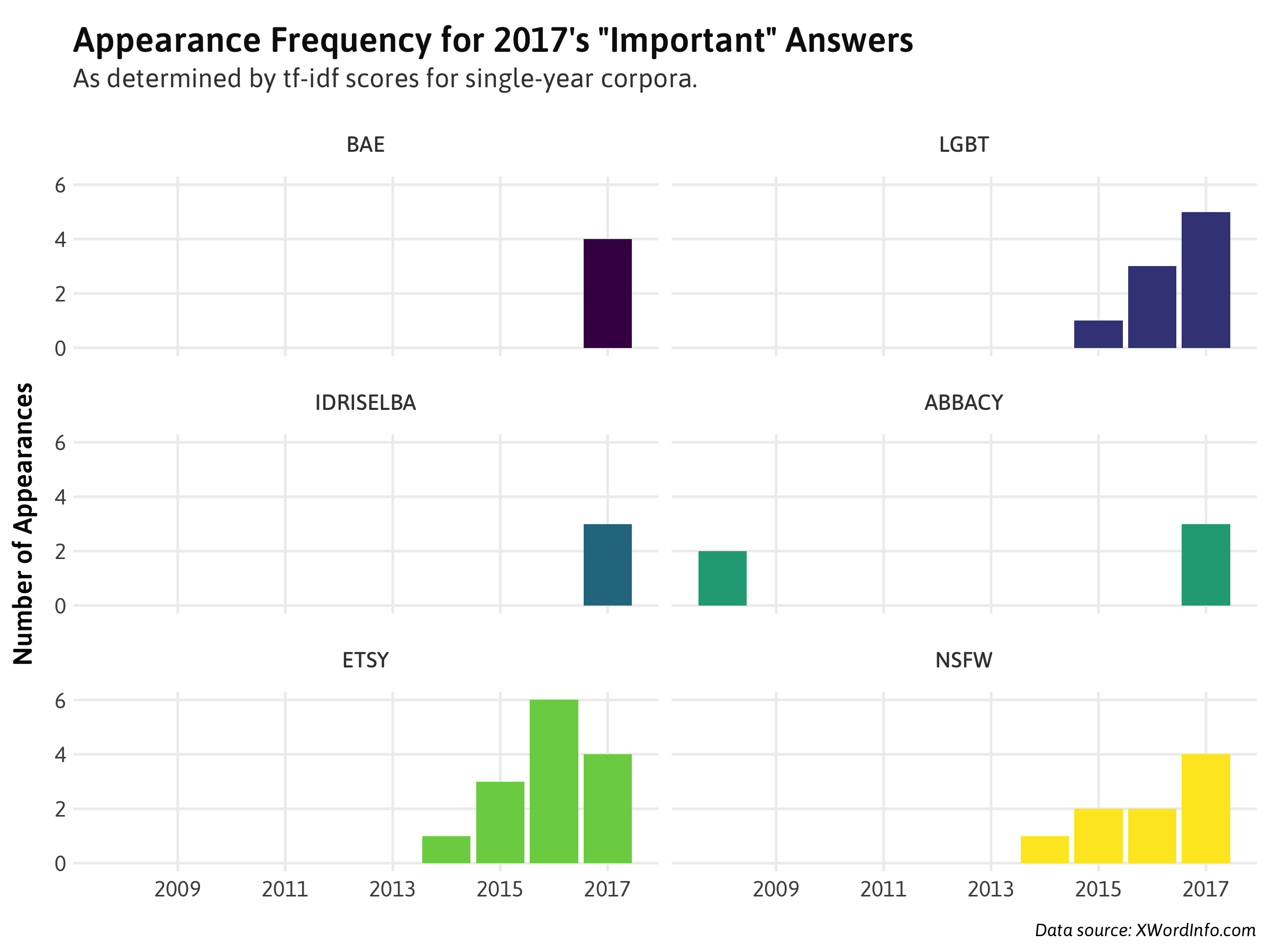
If unique to a year's crossword answer corpus, it looks like a given word only needs to appear as few as 3-4 times within that year - unsurprising when you consider that most other words are used a handful of times across all time at best. Other observations:
- ETSY actually peaked in 2016 (so far), and you'll notice that it appears as #3 on 2016's important words as well.
- SIRI also ranks high twice in the last five years. It was lauched with the iPhone 4S in late 2011, so it makes sense that it'd take until 2013/2014 at the earliest for the word to become popular enough to use as a crossword clue.
- A manual look at the clues for IDRISELBA cited his roles in The Wire (2002-2004) once and Mandela: Long Walk to Freedom (2013) twice. Interestingly enough, no mention of the four films he's been in this year ( Thor: Ragnarok , The Mountain Between Us, The Dark Tower and Molly's Game ).
- What's the deal with CCCCC and UUUUU in 2013? A count by date shows that both answers actually appeared three distinct times, all in the same puzzle. I looked the puzzle up out of curiosity and was faced with this monster, courtesy of Jeff Chen:

What a beaut. (Also note that TTTTT, unlike the other two letters, only appeared twice and did not rank as important to 2013's corpus.)
There were lots of ideas that I played around with that were either less compelling, difficult to execute or outside the scope of what I wanted to do here today. I welcome you to take a stab at them. Here are a few:
- What first names appear most often? Do male and female names appear with the same frequency?
- As above, but with cities and continental representation.
- What languages are represented the most? Many loanwords or straight-up foreign language words exist in the crossword but are very difficult to detect computationally out of the context of a sentence.
- Who are the most prolific crossword submitters, and do they have distinct lexical differences between them?
- Any analysis involving the text of the crossword clues and not just the answers.