
大家好,我是只会心疼giegie的桨师,最近因为想做一个手势相关的小游戏,所以看了一下手势识别。但是目前搜到的数据集中,手势识别的背景都是纯色(纯白或是纯绿),一旦在验证的时候背景变得复杂,则准确率会大大降低。
既然如此......那就来做个数据增广吧,把这些数据集里的手全都抠出来,然后贴到复杂场景里就行了。那把手抠出来......当然优先选择
Paddlehub
当然我并没有使用ace2p这种更细粒度的模型,而是使用了deeplabv3p_xception65_humanseg,不因为别的,只是因为我顺手......这个模型用得很熟练哈哈
手势数据集:aistudio前排手势的数据基本上都用了,因为还有背景数据,用的比较多,一个项目好像只能索引两个数据集,所以我就不引入了,以防不公平,这里把链接贴出来。
手势识别
手势
gesture
手势
手势_石头剪头布
背景数据集,我直接使用的我本地的图,只有上次从ADE2K里挑出来的segsky分割出的数据了。
segsky
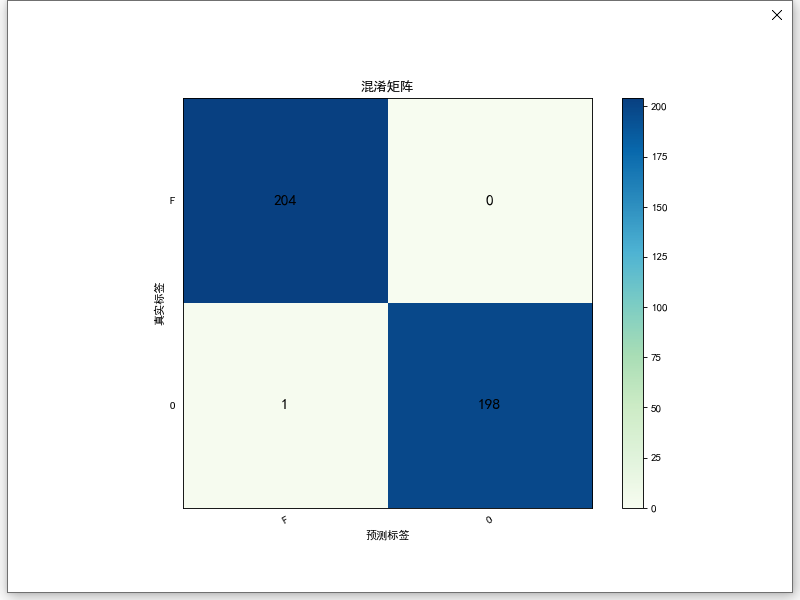
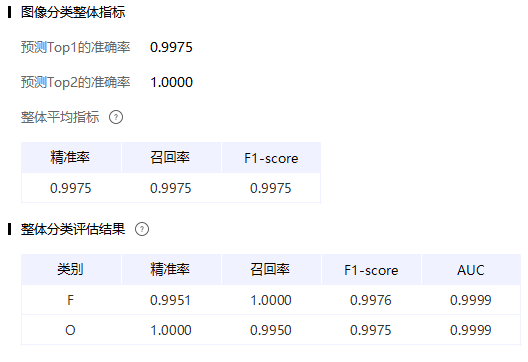
由于我的任务只需要检测到“5”的手势,所以这里是一个简单的2分类,区分“5”及其他
增广前的“5”
增广后的“5”
增广前的“其他”
增广后的“其他”
一方面为手势增加了背景,另一方面让数据变得更多了
经过筛选,5的数据原本979张,增广后2988张




import paddlehub as hub
import cv2
import numpy as np
import glob
import os
import random
import argparse
class segUtils():
def __init__(self):
super().__init__()
self.module = hub.Module(name="deeplabv3p_xception65_humanseg")
def doseg(self, frame):
res = self.module.segmentation(images=[frame], use_gpu=True)
return res[0]['data']
def randomCrop(frame, h, w):
bh, bw = frame.shape[:2]
if bw - w > 0 and bh - h > 0:
randx = random.randint(0, bw - w)
randy = random.randint(0, bh - h)
return frame[randy:randy + h,randx:randx + w]
else:
return cv2.resize(frame, (w, h))
def main(args):
backlist = glob.glob(os.path.join(args.backdir, "*.jpg"))
handlist = glob.glob(os.path.join(args.handdir, "*.png")) + glob.glob(os.path.join(args.handdir, "*.jpg"))
print("back image: ", len(backlist))
print("hand image: ", len(handlist))
save_dir = args.savedir
if not os.path.exists(save_dir):
os.makedirs(save_dir)
SU = segUtils()
for handpath in handlist:
img = cv2.imread(handpath)
basename = os.path.basename(handpath)
filename, ext = os.path.splitext(basename)
mask = SU.doseg(img)
mask[mask <= 1] = 0
mask[mask > 1] = 1
mask = np.repeat(mask[:,:,np.newaxis], 3, axis=2)
h,w = img.shape[:2]
for i in range(2):
rback = cv2.imread(backlist[random.randint(0, len(backlist)-1)])
crop = randomCrop(rback, h, w)
res = mask * img + (1 - mask) * crop
newname = filename + str(i) + ext
cv2.imwrite(os.path.join(save_dir,newname), res.astype(np.uint8))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--backdir", type=str, required=True)
parser.add_argument("--handdir", type=str, required=True)
parser.add_argument("--savedir", type=str, required=True)
args = parser.parse_args()
main(args)至于训练,当然是直接paddleX啦,直接用GUI版本的快速验证自己的想法啦,快速的选择分类模型,开始吧~
选择的MobileNetV3_small_ssld这个模型,batchsize32,训练了30个epoch,太过简单,就不写流程了。
一些测试结果图,效果完全OK哈哈哈




本地开着摄像头视频做了一些测试,效果还不错,但是忘了保存视频了,之后补上。

# 验证 上传一张test.jpg的图片进行测试吧
!python predict.py项目使用Paddlehub来做数据增广,然后使用PaddleX来快速的训练模型验证效果. 其实这个实践只用了几个小时,主要花的时间是在挑数据,有很多增广后的数据不可用,这个和分割的模型有关系,人工筛选了一遍,但我觉得还是值得的(谁让你不用ace2p呢,这不活该吗?别骂了别骂了~) PaddleX真好用,希望支持更多的模型吧,简直我这种懒人福音. 我是不想做趣味项目的桨师,下次再见.
百度飞桨开发者技术专家 PPDE
百度飞桨官方帮帮团、答疑团成员
国立清华大学18届硕士
以前不懂事,现在只想搞钱~欢迎一起搞哈哈哈
我在AI Studio上获得至尊等级,点亮9个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/311006
B站ID: 玖尾妖熊