- python 3.7.1
- transformers==3.0.2
- torch==1.6.0
其他环境见requirements.txt
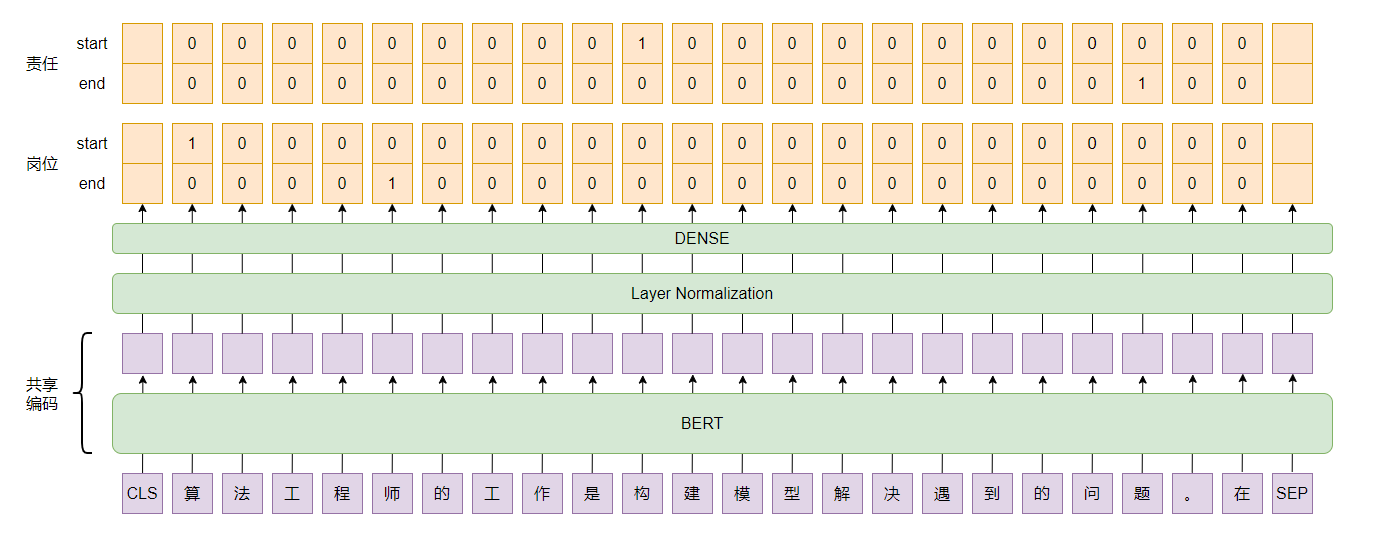
- 按照data中的格式整理好数据
[
{
"text": "XAAAXXXBBXXCCCCCCCCCCCXX",
"a": "AAA",
"b": "BB",
"c": "CCCCCCCCCCC"
},
]
- 在system.config文件中配置好参数,其中class_name必须和json文件中的类别的key一致
class_name=[a,b,c]
- 选择训练模式
################ Status ################
mode=train
# string: train/test/interactive_predict
- 根据结果调高或调低decision_threshold这个超参数(sigmoid的输出大于这个参数会被判定为实体的首/尾)
decision_threshold=0.5
- 运行main.py
- example_datasets1
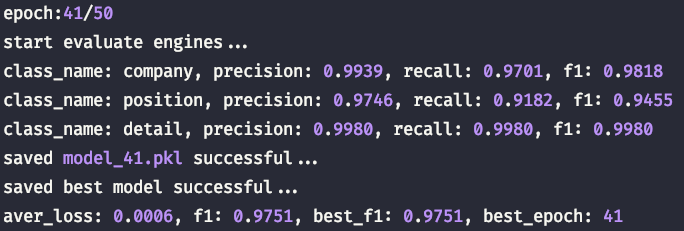
这里的数据模式比较简单,比较容易达到验证集拟合状态
- example_datasets2
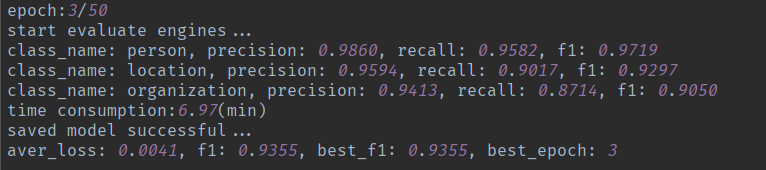
- 选择测试模式,程序会读取训练过程中最好的模型
################ Status ################
mode=interactive_predict
# string: train/test/interactive_predict
交互测试结果如下
- example_datasets1

- example_datasets2
