This demo is part of a 'Interactive Query with Apache Hive' webinar.
The webinar recording and slides are available at http://hortonworks.com/partners/learn/#hive
Instructions for HDP 2.2 can be found here
- Start HDP 2.3 sandbox and enable Hive features like transactions, queues, preemption, Tez and sessions
- Sqoop - import PII data of users from MySql into Hive ORC table
- Flume - import browsing history of users e.g. userid,webpage,timestamp from simulated weblogs into Hive ORC table
- Storm - import tweets for those users into Hive ORC table
- Analyze tables to populate statistics
- Run Hive queries to correlate the data from thee different sources
- What to try next?
- Download HDP 2.3 sandbox VM image (Sandbox_HDP_2.3_VMware.ova) from Hortonworks website
- Import Sandbox_HDP_2.3_VMware.ova into VMWare and set the VM memory size to 8GB
- Now start the VM
- After it boots up, find the IP address of the VM and add an entry into your machines hosts file e.g.
192.168.191.241 sandbox.hortonworks.com sandbox
- Connect to the VM via SSH (password hadoop)
ssh root@sandbox.hortonworks.com
-
Setup/configure 'batch' and 'default' YARN queues using 'YARN Queue Manager' view in Ambari (login as admin/admin): http://sandbox.hortonworks.com:8080/#/main/views/CAPACITY-SCHEDULER/1.0.0/AUTO_CS_INSTANCE
-
For the default queue, make the below changes:
- Capacity: 50%
- Maximum AM Resource: 30%
- Queue mappings: g:IT:batch,g:Marketing:default
- User limit: 2
- ordering policy: set to fair
- max capacity: 100%

-
Create a batch queue at the same level as default queue (first highlight root queue, then click "Add Queue") and ensure the below are set changes:
- Capacity: 50%
- max capacity: 50%

-
Actions > Save and refresh queues > Save changes. This should start a 'Refresh Yarn Capacity Scheduler' operation
-
-
In Ambari, under YARN config: make the below pre-emption config changes,Save and restart YARN



-
you can also search for the property using its full name: yarn.resourcemanager.scheduler.monitor.enable=true
-
In Ambari, under Hive config: make the below compactor/interactive query config changes and restart Hive


-
you can also search for the properties using its full name:
- hive.compactor.initiator.on=true
- hive.compactor.worker.threads = 2
- hive.server2.tez.initialize.default.sessions = true
- hive.server2.tez.default.queues=hiveserver.hive1,hiveserver.hive2
-
Further reading:
- More details on Hive streaming ingest can be found here: https://cwiki.apache.org/confluence/display/Hive/Streaming+Data+Ingest
- More details on the above parameters can be found in the webinar slides, available at http://hortonworks.com/partners/learn/#hive
- Pull the latest Hive streaming code/scripts
cd
git clone https://github.com/abajwa-hw/hdp22-hive-streaming.git
- Inspect CSV of user personal data
cat ~/hdp22-hive-streaming/data/PII_data_small.csv
- Import users personal data into MySQL
mysql -u root -p
#empty password
create database people;
use people;
create table persons (people_id INT PRIMARY KEY, sex text, bdate DATE, firstname text, lastname text, addresslineone text, addresslinetwo text, city text, postalcode text, ssn text, id2 text, email text, id3 text);
LOAD DATA LOCAL INFILE '~/hdp22-hive-streaming/data/PII_data_small.csv' REPLACE INTO TABLE persons FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
- In MySQL, verify that the data was imported and exit. The remaining queries will be run in Hive
select people_id, firstname, lastname, city from persons where lastname='SMITH';
exit;
- Using the Ambari view for Hive, notice there is no Hive table called persons yet
http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive

- Optional: Not needed on 2.3 sandbox. Point Sqoop to a newer version of mysql connector. This is a workaround needed when importing large files using Sqoop, to avoid "GC overhead limit exceeded" error. See SQOOP-1617 and SQOOP-1400 for more info
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.31/mysql-connector-java-5.1.31.jar -O /tmp/mysql-connector-java-5.1.31.jar
cp -a /tmp/mysql-connector-java-5.1.31.jar /usr/share/java/
ln -sf /usr/share/java/mysql-connector-java-5.1.31.jar /usr/share/java/mysql-connector-java.jar
ls -la /usr/share/java/my*
- Import data from MySQL to Hive ORC table using Sqoop. From the terminal shell run:
sqoop import --verbose --connect 'jdbc:mysql://localhost/people' --table persons --username root --hcatalog-table persons --hcatalog-storage-stanza "stored as orc" -m 1 --create-hcatalog-table
Note: if importing large files you should also add the following argument: --fetch-size -2147483648
- Now re-open the Hive view and notice that the persons table was created and has data
http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive

- Notice the table is stored in ORC format by opening the underlying HDFS file in the HDFS files view and then on part-m-00000: /apps/hive/warehouse/persons/part-m-00000
http://sandbox.hortonworks.com:8080/#/main/views/FILES/1.0.0/Files


- Compare the format of table persons against the format of sample_07 which is stored in text format: /apps/hive/warehouse/sample_07/sample_07


- Use Hive view to create table webtraffic to store the userid and web url enabling transactions and partition into day month year: http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive
create table if not exists webtraffic (id int, val string)
partitioned by (year string,month string,day string)
clustered by (id) into 7 buckets
stored as orc
TBLPROPERTIES ("transactional"="true");

- Now lets configure the Flume agent. High level:
- The source will be of type exec that tails our weblog file using a timestamp intersept (i.e. flume interseptor adds timestamp header to the payload)
- The channel will be a memory channel which is ideal for flows that need higher throughput but could lose the data in the event of agent failures
- The sink will be of type Hive that writes userid and url to default.webtraffic table partitioned by year, month, day
- More details about each type of source, channel, sink are available here
- In Ambari > Flume > Service Actions > Turn off maintenance mode
- In Ambari > Flume > Configs > flume.conf enter the below, Save and restart Flume
## Flume NG Apache Log Collection
## Refer to https://cwiki.apache.org/confluence/display/FLUME/Getting+Started
##
agent.sources = webserver
agent.sources.webserver.type = exec
agent.sources.webserver.command = tail -F /tmp/webtraffic.log
agent.sources.webserver.batchSize = 20
agent.sources.webserver.channels = memoryChannel
agent.sources.webserver.interceptors = intercepttime
agent.sources.webserver.interceptors.intercepttime.type = timestamp
## Channels ########################################################
agent.channels = memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 1000
agent.channels.memoryChannel.transactionCapacity = 1000
## Sinks ###########################################################
agent.sinks = hiveout
agent.sinks.hiveout.type = hive
agent.sinks.hiveout.hive.metastore=thrift://localhost:9083
agent.sinks.hiveout.hive.database=default
agent.sinks.hiveout.hive.table=webtraffic
agent.sinks.hiveout.hive.batchSize=1
agent.sinks.hiveout.hive.partition=%Y,%m,%d
agent.sinks.hiveout.serializer = DELIMITED
agent.sinks.hiveout.serializer.fieldnames =id,val
agent.sinks.hiveout.channel = memoryChannel
- Start tailing the flume agent log file in one terminal...
tail -F /var/log/flume/flume-agent.log
- After a few seconds the agent log should contain the below
02 Jan 2015 20:35:31,782 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.ExecSource.start:163) - Exec source starting with command:tail -F /tmp/webtraffic.log
02 Jan 2015 20:35:31,782 INFO [lifecycleSupervisor-1-1] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) - Monitored counter group for type: SINK, name: hiveout: Successfully registered new MBean.
02 Jan 2015 20:35:31,782 INFO [lifecycleSupervisor-1-1] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) - Component type: SINK, name: hiveout started
02 Jan 2015 20:35:31,783 INFO [lifecycleSupervisor-1-1] (org.apache.flume.sink.hive.HiveSink.start:611) - hiveout: Hive Sink hiveout started
02 Jan 2015 20:35:31,785 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) - Monitored counter group for type: SOURCE, name: webserver: Successfully registered new MBean.
02 Jan 2015 20:35:31,785 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) - Component type: SOURCE, name: webserver started
- Using another terminal window, run the createlog.sh script which will generate 400 dummy web traffic log events at a rate of one event per second
cd ~/hdp22-hive-streaming
./createlog.sh ./data/PII_data_small.csv 400 >> /tmp/webtraffic.log
- Start tailing the webtraffic file in another terminal
tail -F /tmp/webtraffic.log
- The webtraffic.log should start displaying the webtraffic
581842607,http://www.google.com
493259972,http://www.yahoo.com
607729813,http://cnn.com
53802950,http://www.hortonworks.com
- The Flume agent log should start outputting below
02 Jan 2015 20:42:37,380 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hive.HiveWriter.commitTxn:251) - Committing Txn id 14045 to {metaStoreUri='thrift://localhost:9083', database='default', table='webtraffic', partitionVals=[2015, 01, 02] }
- After 6-7min, notice that the script has completed and the webtraffic table now has records created
http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive

- Open Files view and navigate to /apps/hive/warehouse/webtraffic/year=xxxx/month=xx/day=xx/delta_0000001_0000100 and view the files
http://sandbox.hortonworks.com:8000/filebrowser/view//apps/hive/warehouse/webtraffic

- Notice the table is stored in ORC format


- Make hive config changes to enable transactions, if not already done above
hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
hive.compactor.initiator.on = true
hive.compactor.worker.threads > 0
-
Add your Twitter consumer key/secret, token/secret under hdp22-hive-streaming/src/test/HiveTopology.java
-
Create hive table for tweets that has transactions turned on and ORC enabled
create table if not exists user_tweets (twitterid string, userid int, displayname string, created string, language string, tweet string) clustered by (userid) into 7 buckets stored as orc tblproperties("orc.compress"="NONE",'transactional'='true');

- Optional: build the storm uber jar (may take 10-15min first time). You can skip this to use the pre-built jar in the target dir.
#Install maven from epel
curl -o /etc/yum.repos.d/epel-apache-maven.repo https://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo
yum -y install apache-maven
#build storm jar
cd /root/hdp22-hive-streaming
mvn package
- In case your system time is not accurate, fix it to avoid errors from Twitter4J
yum install -y ntp
service ntpd stop
ntpdate pool.ntp.org
service ntpd start
- Using Ambari, make sure Storm has maintenance mode turned off and is started (it is stopped by default on the sandbox) and twitter_topology does not already exist
- Open up the Storm webview or Storm webui

- Run the topology on the cluster and notice twitter_topology appears on Storm webui
cd /root/hdp22-hive-streaming
storm jar ./target/storm-integration-test-1.0-SNAPSHOT.jar test.HiveTopology thrift://sandbox.hortonworks.com:9083 default user_tweets twitter_topology
Note: to run in local mode (ie without submitting it to cluster), run the above without the twitter_topology argument
- In Storm view or UI, drill down into the topology to see the details and refresh periodically. The numbers under emitted, transferred and acked should start increasing.


In Storm view or UI, you can also click on "Show Visualization" under "Topology Visualization" to see the topology visually


- After 20-30 seconds, kill the topology from the Storm UI or using the command below to avoid overloading the VM
storm kill twitter_topology
-
After a few seconds, navigate to Hive view and query the user_tweets table and notice it now contains tweets
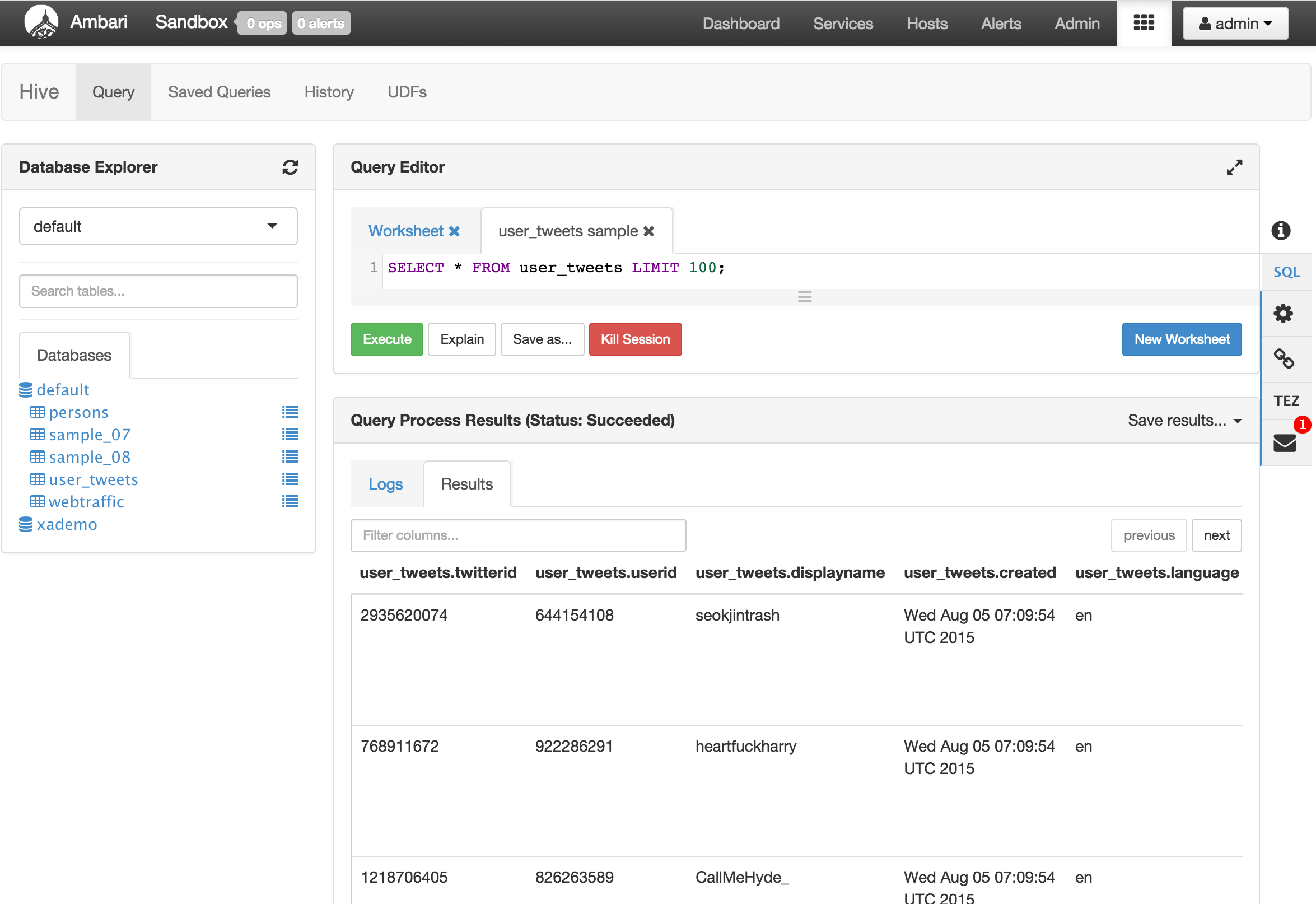
- You may encounter the below error through Hue when browsing this table. This is because in this version, Hue beeswax does not support UTF-8 and there were such characters present in the tweets

'ascii' codec can't decode byte 0xf0 in position 62: ordinal not in range(128)
- To workaround replace
default_filters=['unicode', 'escape'],withdefault_filters=['decode.utf8', 'unicode', 'escape'],in /usr/lib/hue/desktop/core/src/desktop/lib/django_mako.py
cp /usr/lib/hue/desktop/core/src/desktop/lib/django_mako.py /usr/lib/hue/desktop/core/src/desktop/lib/django_mako.py.orig
sed -i "s/default_filters=\['unicode', 'escape'\],/default_filters=\['decode.utf8', 'unicode', 'escape'\],/g" /usr/lib/hue/desktop/core/src/desktop/lib/django_mako.py
- Open Files view and navigate to /apps/hive/warehouse/user_tweets: http://sandbox.hortonworks.com:8080/#/main/views/FILES/1.0.0/Files

- Notice the table is stored in ORC format

- In case you want to empty the table for future runs, you can run below
delete from user_tweets;
Note: the 'delete from' command are only supported in 2.2 when Hive transactions are turned on)
- Run Hive table statistics
analyze table persons compute statistics;
analyze table user_Tweets compute statistics;
analyze table webtraffic partition(year,month,day) compute statistics;
- Run Hive column statistics
analyze table persons compute statistics for columns;
analyze table user_Tweets compute statistics for columns;
analyze table webtraffic partition(year,month,day) compute statistics for columns;
-
Using the Hive view http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive :
-
Check size of PII table
select count(*) from persons;
returns 400 rows
- Correlate browsing history with PII data
select p.firstname, p.lastname, p.sex, p.addresslineone, p.city, p.ssn, w.val
from persons p, webtraffic w
where w.id = p.people_id;
Notice the last field contains the browsing history:

- Correlate tweets with PII data
select t.userid, t.twitterid, p.firstname, p.lastname, p.sex, p.addresslineone, p.city, p.ssn, t.tweet
from persons p, user_tweets t
where t.userid = p.people_id;
Notice the last field contains the Tweet history:

- Correlate all 3
select p.firstname, p.lastname, p.sex, p.addresslineone, p.city, p.ssn, w.val, t.tweet
from persons p, user_tweets t, webtraffic w
where w.id = t.userid and t.userid = p.people_id
order by p.ssn;
Notice the last 2 field contains the browsing and Tweet history:

-
Notice that for these queries Hive view provides the option to view Visual Explain of the query for performance tuning.

-
Also notice that for these queries Hive view provides the option to view Tez graphical view to help aid debugging.



-
Enhance the sample Twitter Storm topology
- Import the above Storm sample into Eclipse on the sandbox VM using an Ambari stack for VNC and use the Maven plugin to compile the code. Steps available at https://github.com/abajwa-hw/vnc-stack
- Update HiveTopology.java to pass hashtags or languages or locations or Twitter user ids to filter Tweets
- Add other Bolts to this basic topology to process the Tweets (e.g. rolling count) and write them to different components (like HBase, Solr etc). Here is a HDP 2.2 sample project showing a more complicated topology with Tweets being generated from a Kafka producer and being emitted into local filesystem, HDFS, Hive, Solr and HBase: https://github.com/abajwa-hw/hdp22-twitter-demo
-
Use Sqoop to import data into ORC tables from other databases (e.g. Oracle, MSSQL etc). See this blog entry for more details
-
Experiment with Flume
- Change the Flume configuration to use different channels (e.g. FileChannel or Spillable Memory Channel) or write to different sinks (e.g HBase). See the Flume user guide for more details.