_____ ____ _ _ _
| __ \ / __ \ | | (_) (_)
| |__) | __ ___ ___ ___ ___ ___| | | |_ __ | |_ _ _ __ ___ _ _______ _ __
| ___/ '__/ _ \ / __/ _ \/ __/ __| | | | '_ \| __| | '_ ` _ \| |_ / _ \ '__|
| | | | | (_) | (_| __/\__ \__ \ |__| | |_) | |_| | | | | | | |/ / __/ |
|_| |_| \___/ \___\___||___/___/\____/| .__/ \__|_|_| |_| |_|_/___\___|_|
| |
|_|

This readme.md is work in progress
ProcessOptimizer is a fork of scikit-optimize. ProcessOptimizer will fundamentally function like scikit-optimize, yet developments are focussed on bringing improvements to help optimizing real world processes, like chemistry or baking. For examples on use, checkout https://github.com/novonordisk-research/ProcessOptimizer/tree/develop/examples.
ProcessOptimizer can be installed using pip install ProcessOptimizer
The repository and examples can be found at https://github.com/novonordisk-research/ProcessOptimizer
ProcessOptimizer can also be installed by running pip install -e . in top directory of the cloned repository.
This package is intended for real world process optimization problems of black-box functions. This could e.g. be some complex chemical reaction where no reliable analytical model mapping input variables to the output is readily available.
Bayesian optimization is a great tool for optimizing black-box functions where the input space has many dimensions and the function is expensive to evaluate in terms of time and/or resources.
Notice that this tool is designed to solve minimization problems. It is therefore important to define the scoring function such that it turns into a minimization problem.
Below is an illustrative example of minimization of the Booth function in 2 dimensions using the ProcessOptimizer package. Notice that in real world applications the function would be black box (and typically the input space would have more than 2 dimensions). However, it would still be possible to evaluate the function given a set of input values and thus use the same framework for optimization.
The Booth function is a 2-dimensional function defined by Booth Function (sfu.ca). In this example uniformly distributed random noise between 0-5% of the function value is added using np.random.
def Booth(x0, x1):
return ((x0 + 2 * x1 - 7)**2 + (2 * x0 + x1 - 5)**2) * (1 + 0.05 * np.random.rand())Below is an image of the Booth function on the square for i=0,1.
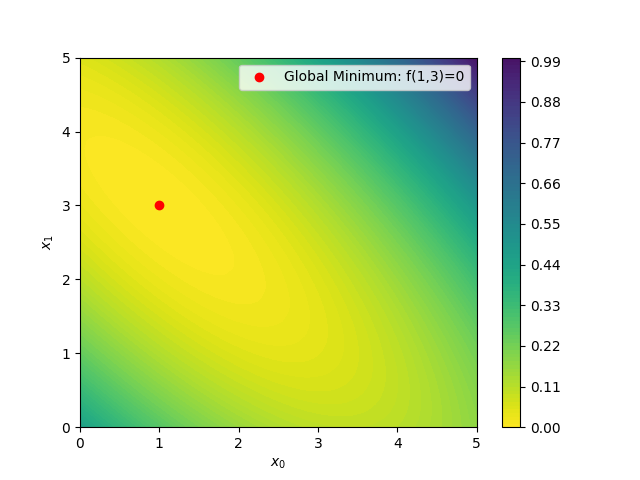
Suppose you are given the task of minimizing the function on the domain only using empirical observations and without any analytical function.
Working with the ProcessOptimizer package you simply define the Space and create an Optimizer object.
The Space object takes a list of dimensions which can either be Real, Integer or Categorical. Real dimensions are defined by the maximum and minimum values.
The Optimizer object initialized below uses GP (Gaussian Process). This means that after each step a Gaussian Process is fitted to the observations, which is used as a posterior distribution. Combined with an acquisition function the next point that should be explored can be determined. Notice that this process only takes place once n_initial_points of initial data has been aqcuired. In this case LHS = True (latin hypercube sampling) has been used as the initial sampling strategy for the first 6 points.
SPACE = Space([Real(0,5), Real(0,5)])
opt = Optimizer(SPACE, base_estimator = "GP", n_initial_points = 6, lhs = True)The optimizer can now be used in steps by calling the .ask() function, evaluating the function at the given point and use .tell() the Optimizer the result. In practise it would work like this. First ask the optimizer for the next point to perform an experiment:
opt.ask()
>>> [3.75, 3.75]Now go to the laboratory or wherever the experiment can be performed and use the values above. In this example the experiment can simply be performed by evaluating the Booth function using the values above:
Booth(3.75, 3.75)
>>> 59.313996676981354When a result has been obtained the user needs to tell the output to the Optimizer. This is done using the .tell() function:
res = opt.tell([3.75, 3.75], 59.313996676981354)The res object returned by tell contains a model of the Gaussian Process predicted mean. This model can be plotted using plot_objective(res). Below is a gif of how the Gaussian Process predicted mean evolves after the first 6 initial points and until 20 points have been sampled in total. The orange dots visualise each evaluation of the function and the red dot shows the position of the expected minimum. In the diagonal of the figure dependence plots are shown. These show how the function depend on each input variable with other input variables kept constant at the expected minimum.
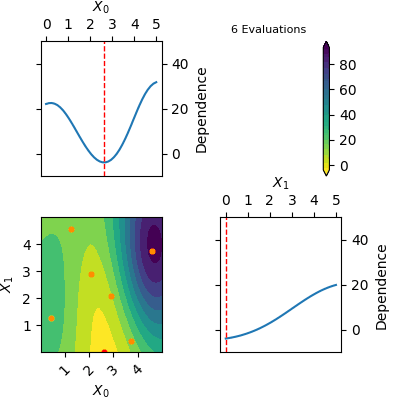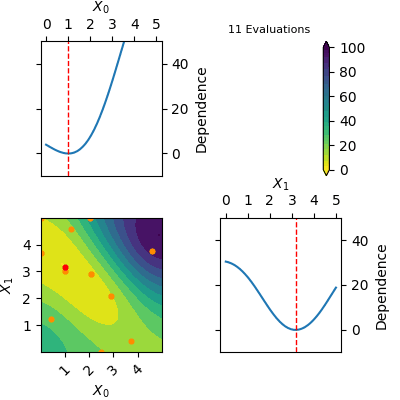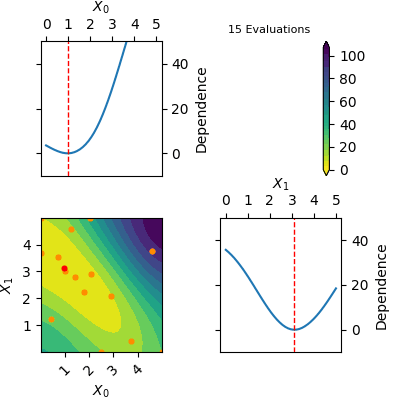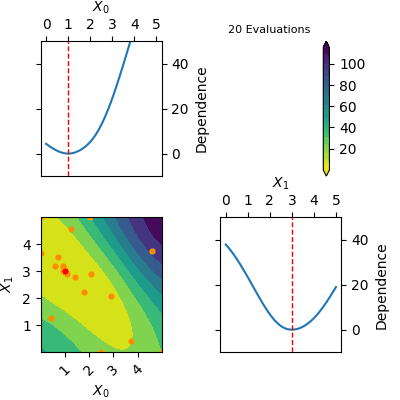
Notice that this is an optimization tool and not a modelling tool. This means that the optimizer finds an approximate solution for the global minimum quickly however it does not guarantee that the Gaussian Process predicted mean is an accurate model on the entire domain.
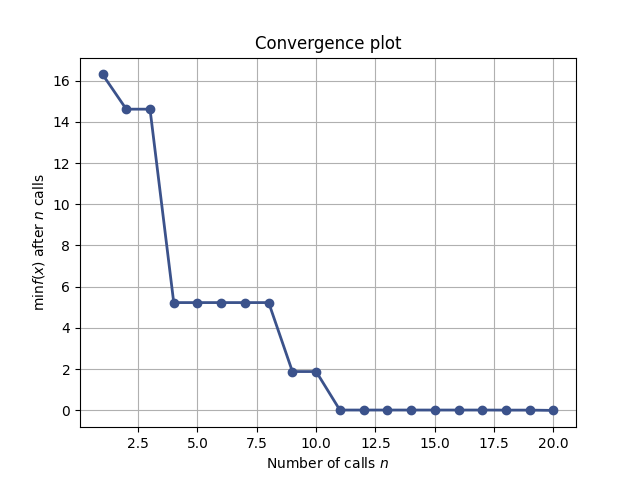
The best observation against the number of observations can be plotted with plot_convergence(res):
If you use the package in relation to a citation, please cite: https://doi.org/10.5281/zenodo.5155295.
Please also cite the underlaying package (scikit-optimize).
Feel free to play around with algorithm. Should you encounter errors while using ProcessOptimizer, please report them
at https://github.com/novonordisk-research/ProcessOptimizer/issues.
To help solve the issues, please:
- Provide minimal amount of code to reproduce the error
- State versions of ProcesOptimizer, sklearn, numpy, ...
- Describe the expected behavior of the code
If you would like to contribute by making anything from documentation to feature-additions, THANK YOU. Please open a pull request
marked as WIP as early as possible and describe the issue you seek to solve and outline your planned solution.
Pull requests to the develop branch will be automatically tested using pytest and flake8. We'll be happy to help solving potential
issues that could arise here.
We are currently building a GUI to offer the power of Bayesian Process Optimization to non-coders. Stay tuned. (Sneak-peak at https://www.browniebee.dk/uk/)
If you have not packaged before check out https://packaging.python.org/tutorials/packaging-projects/ To upload a new version to PyPi do the following in the root folder of the project:
- In terminal run the command "pytest" and make sure there are no errors
- Change version number in setup.py
- Change version number in ProcessOptimizer/__init__.py
- Remember to
pip install twineif running in a new virtual env. (You might also have topip install wheel) - Run
python setup.py sdist bdist_wheel - Run
python -m twine upload dist/*(make sure that /dist only contains relevant version) - (Remember that pypi has changed the way it handles credentials, you might have to state username: [dunderscore]token[dunderscore] and then use your token value (incl pypi-prefix) as password. As stated here https://pypi.org/help/#apitoken