Springboard's Capstone: A deep caption generation project
A first "Conceptual" captioning project: https://github.com/nadegepepin/capstone-prototype.
1- Preface
Automatic caption generation stands at the crossroads of computer vision and natural language processing, making it a perfect candidate for a challenging first Machine Learning project.
The production of the natural-language description of an image is nothing new. It is used as an assistance to people suffering from vision loss, it facilitates content indexation... Models themselves have passed an important milestone with the arrival of GPT3.
For this capstone, we have chosen to keep this first ML project simple, using a now dated ResNet/LSTM 'inject and merge' model (rather than a more updated Transformer model) and focusing mainly on producing robust, highly scalable, "Dockerized" code for both the training of our model and the inference of captions. The end result is a Flask App running in our Docker container https://github.com/nadegepepin/capstone-prototype/tree/master/src/app and deployed on AWS Fargate http://18.218.38.67:5000/ You might want to give it a try and upload your png or jpg (no transparency layer).
1.1- Project's highlights
Before we dive into the few steps that led us to a fully trained model and its deployment on AWS, here are a couple things that make this ML project specific:
- A learner mindset: Instead of spending time on a best-in-class model trained on the traditional COCO or Flickr dataset, we decided to go for a simple model trained on a different set of data google conceptual caption dataset (~3.3 M images) for the sake of dealing with the challenge of scalability. This path led us to split our data and jobs over 30 machines in paralell in order to boost the data extraction and transformation prior to the training of our model on AWS Sage Maker.
- During the course of our bootcamp, a thorough interview process for Pachyderm (a pipeline middleware product specialized in data lineage) led us to reproduce the same data extraction, tranformation, and the training of the model using Pachyderm Hub pipelines. Read about it here.
For this project, we will be using Conceptual Captions, a new, cleaned, hypernym-ed, Image Alt-text Dataset for Automatic Image Captioning created by Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut at Google AI in 2018. The dataset contains about 3.3M images URLs and their associated caption. Contrary to the previous datasets (MS-COCO, Flickr8) traditionally used to train captioning models, this one was programmatically generated/labeled from billion of original images harvested on the internet. The significant difference in the size of this new dataset (compared to the 200K images from MS-COCO) provides a wider diversity of images. Depending on our time at hand, we will ultimately try to fit our model with both datasets in order to compare how our model reacts.
You can download the Dataset here.
1.2- What Data?
In contrast with the curated style of the COCO images, Conceptual Captions images and raw descriptions are harvested from the web from the Alt-text HTML attribute associated with the web image. Google's team developed an automatic pipeline that extracts, filters, and transforms (hypernymes) candidate image/caption pairs, with the goal of "achieving a balance of cleanliness, informativeness, fluency, and learnability of the resulting captions". For more information on how the dataset was extracted/filtered/curated, see Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut’s paper.
The Conceptual Captions dataset contains two splits: train (~3.3M examples) and validation (~16K examples) each in the form of a .tsv file, each line containing a (caption, corresponding url) pair. Dataset stats here.
2- Technical Approach
2.1- Data Loader and data preprocessing
The Architectural Diagram below gives an overview of the sequence of extraction/transformation jobs required to train our model.
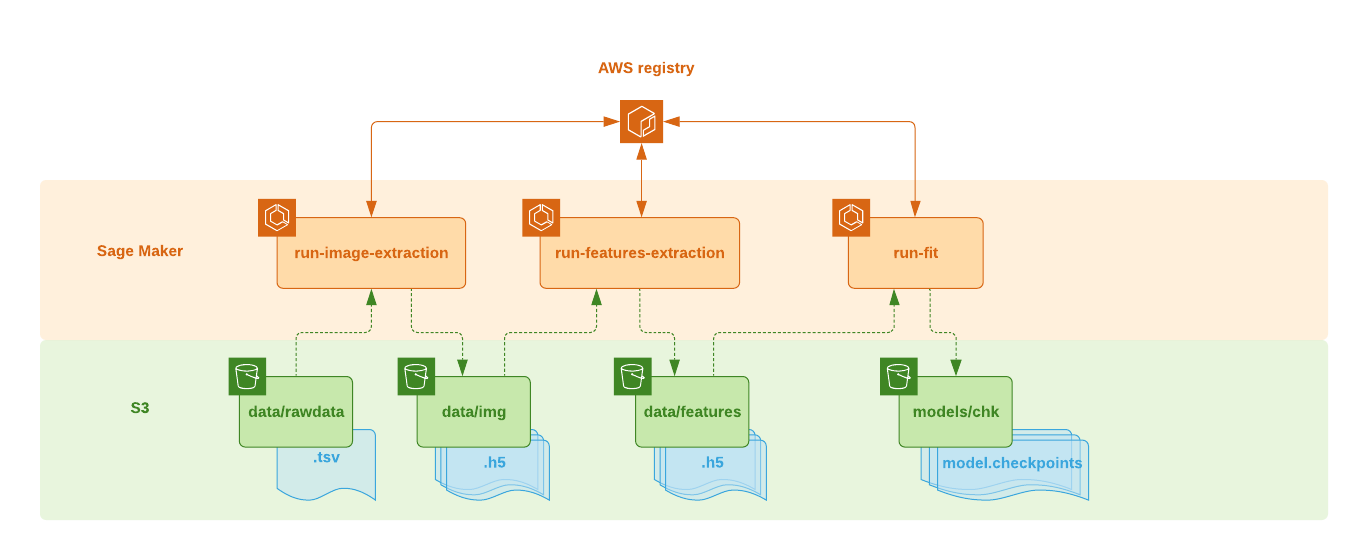 Fig 1: Training pipelines
Fig 1: Training pipelines
All the data loading and extraction code is found in the following two components:
The training pipeline requires the 2 following steps before the model is trained:
- Step 1: Retrieving the images from the tsv file's urls and storing them into multiple
data/img/train_<filenb>.h5ordata/validate_<filenb>.h5files each containing 100.000 indexes. Look for the code of the images' extraction functionrequest_data_and_storehere. In that function, you will notice the multi threading strategy used to boost the http request and storage of the 3 millions+ images. Each h5 file (25GB) stores the image, caption and, http status of the request in a separate group. The image might be nonexistent in the case where the http status code is different from 200 (404, 500, etc... ). - Step 2: Features are then extracted from the images in
data/img/train_<filenb>.h5files using a pre trained ResNet50 model and stored in a new .h5 filedata/features/resnet_train_<filenb>.h5. Again, features, caption and http status are stored in their own group in the h5 file. Each h5 contains the same 100.000 indexes as thedata/img/train_<filenb>.h5they come from. These files will be used to feed the model during the training phase. Look for the code of the features extraction functionextract_resnet_features_and_storehere. Each caption goes through a simple pre-processing 'clean up' before its final storage. It is lower cased, and all numerical characters, punctuation, and hanging ’s’ and ‘a’ are removed.
In the training phase of this project, we have created 30 .h5 files of 100.000 records each. This split of data allowed us to run 30 processing jobs in parallel, reducing the processing time for the images and features extraction of the complete train dataset to less than 7 hours with basic quad-core machines on AWS.
2.2- Model
We used an 'inject and merge' architecture (on tensorflow.keras 2.x ) for our encoder-decoder recurrent neural network model.
The model’s creation code can be found here under the function injectAndMerge(). See figure 2 below.
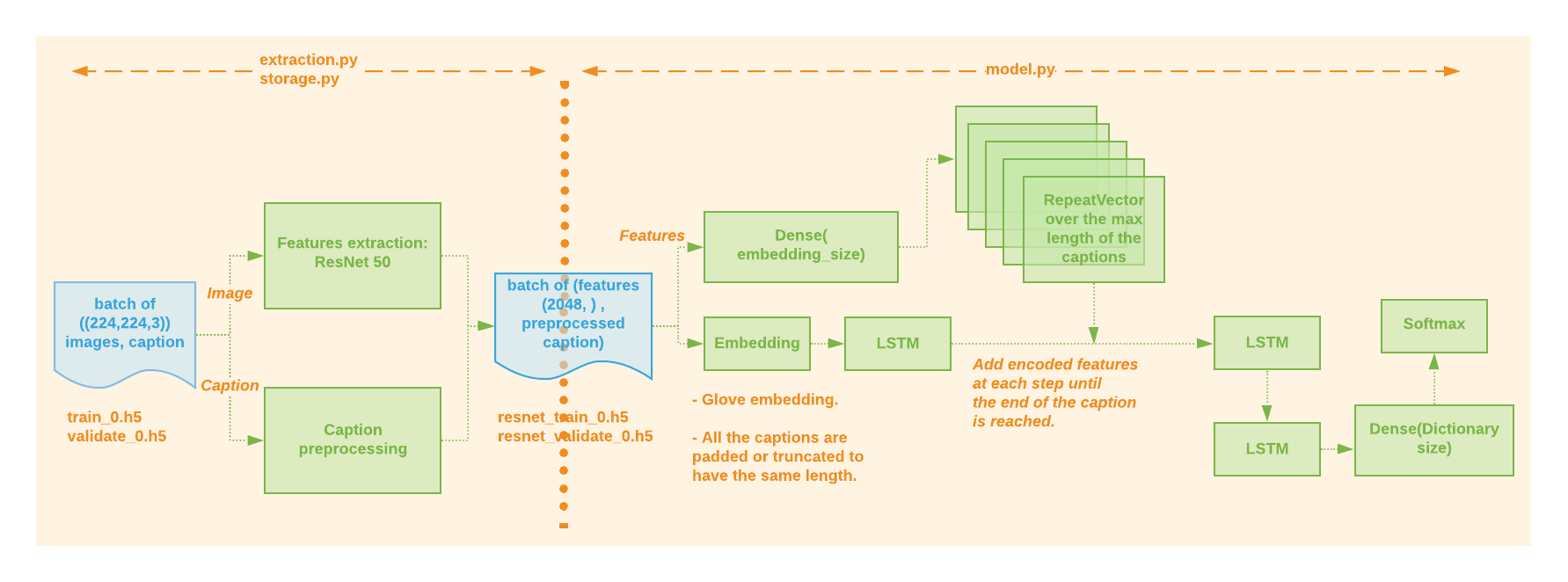 Fig 2: Captioning model training
Fig 2: Captioning model training
Note that the model generates one word of the output textual description at a time, given both the features of the image (repeated as many times as the max number of token in the description) and the description generated so far as input (see Figure 3 below). In this framing, the model is called recursively until the entire output sequence is generated.
Each caption input is set to the fixed length of max-caption-length using a right padding.
The output’s one hot encoding has the dictionary size determined in the embedding class (see below).
 Fig 3: Recursivity of the caption generation
Fig 3: Recursivity of the caption generation
2.3- Embedding
The captions have been embedded using Stanfords’ GloVe 50 embedding matrix. You will find the details of the GloVe embedding used in the class src/GloVepreprocessing.py. We fit a Tokenizer over the entire caption corpus and stored the dictionary and the weight matrix into a file using pickle (Look for the helper function preprocessor_factory() at the end of the GloVepreprocessing's class). The class provides one hot encoding, word to index and index to word helpers. For this project, we have set the caption max lenght to 34 and dictionary size to 10.000. Those are hyper-parameters stored in a config file.
MAX_SEQUENCE_LENGTH = 34
EMBEDDING_SIZE = 50
MAX_VOCAB_SIZE= 10000
3- Training
3.1- Generator
Details of the generator in the GloVepreprocessing.py can be found in the generator function.
3.2- Fit/Train and save model
Train
Details of compile, learning rate, loss, optimizer, check points, and tensor board callbacks used for fitting the model found in train.py. All values default in config file settings.toml.
Fit job
More details about the processing job used to fit the model here.
Sage Maker job processing
All the data processing and training jobs have run on Amazon SageMaker using my docker image and an S3 bucket as Input/Output.
 Fig 4: Job Processing - Fit
Fig 4: Job Processing - Fit
 Fig 5: s3 Input/Output buckets
Fig 5: s3 Input/Output buckets
4- Inference/Caption generation - Hosting
Caption generation
see predict.py
Flask App
Code to our simple Flask app here
AWS Fargate hosting
Our flask app was deployed as a container on AWS Container service using a Fargate (on demand Pay-per-Use) cluster.
 Fig 6: Fargate hosting of Flask App
Fig 6: Fargate hosting of Flask App
5- Metrics/BLEU score
We have tested our model (define_my_model) against another (define_model) and tried various datasets (Flickr8, Conceptual Caption) and features extraction models (VGG16, ResNet50). The detail of those combinations can be found in this Jupiter notebook.
BLEU scores (1,2,3 and 4-grams) for each of those tests: 
Last, a comparison of some predicted caption vs actual:
- Predicted: the interior of the house- Actual: opening up fireplace for the installation of wood burning
- Predicted: actor attends the premiere of the film- Actual: fashion shoot using balloons as prop
- Predicted: person attends the fashion show during fashion week- Actual: shoppers on the final saturday before western christian holiday
- Predicted: person performs on stage during festival- Actual: lead singer person puts the finishing touches on his solo performance
- Predicted: actor performs during the festival- Actual: electronica artist of electronica artist performs on stage during the second day of festival
- Predicted: young woman with his son in the street- Actual: disease homeless lives in the streets of neighborhood already
- Predicted: portrait of young woman with glasses- Actual: gloomy face of sad woman looking down zoom in gray background
- Predicted: the view from the top of the building- Actual: still shot of several boats on port
- Predicted: young woman in the park- Actual: woman with umbrella talking on the phone smiling feeling positive thoughts
- Predicted: person competes in the first half of the game against sports team- Actual: person warms up during game against american football team
- Predicted: map of the country- Actual: painting artist thought it was compliment that children could understand his art
- Predicted: person in the dress- Actual: person in dress and wrap