- Yelp: https://www.yelp.com/dataset
- Businesses and Reviews files downloaded from the link above
- Seafood Watch: https://www.seafoodwatch.org/
- csv file provided by a representative of the organization containing their restaurant partners (email me for access)
- Green Restaurant Association: http://www.dinegreen.com/
- csv file provided by a representative of the organization containing the restaurants they have rated (email me for access)
- How different green ratings columns correlate with one another and the yelp star ratings
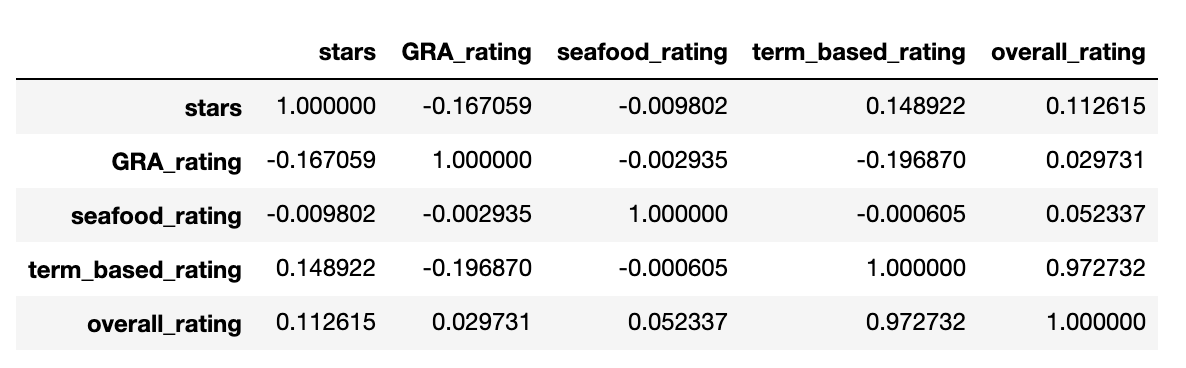
- The combined Green Rating for restaurants for each yelp star rating


To run any of the python scripts you must have the above data in data/original_sources in files named:
YelpBusiness.csv- generated byjson_to_csv.pyfrom json file downloaded from yelpYelpReview.csv- generated byjson_to_csv.pyfrom json file downloaded from yelpGRA.csvSeafoodWatch.csv
- json_to_csv.py
- Imports: pandas
- Converts JSON files downloaded from Yelp dataset challenge into csv files.
- clean_yelp_businesses.py
- Imports: pandas
- Removes unwanted columns and rows from yelp businesses csv file
- Yelp data contains businesses in addition to restaurants,
so we filter the categories column for these words:
['RESTAURANTS','BARS','FOOD','BREAKFAST & BRUNCH','DESSERTS','BAKERIES, DELIS, SANDWICHES', 'COFFEE & TEA', 'DINERS', 'CAFES']
- Yelp data contains businesses in addition to restaurants,
so we filter the categories column for these words:
- files required:
data/original_sources/YelpBusiness.csv - files generated:
data/clean_yelp_restaurants.csv
- clean_GRA_data.py
- Imports: pandas
- Removes unnecessary columns and standardizes text
- files required:
data/original_sources/GRA.csv - files generated:
data/clean_green.csv
- merge_restaurants_and_reviews.py
- Imports: pandas
- Merges yelp business and review data into one pandas dataframe by combining the text from each review about a restaurant into one large block of text
- Merges entries for separate locations of the same franchise into one row in our dataset.
- files required:
data/original_sources/YelpReview.csv,data/clean_yelp_restaurants.csv - files generated:
data/big_restaurants_and_reviews.csv,data/small_restaurants_and_reviews.csv
- environmental_term_analysis.py
- Can be run with --Small True to use the small dataset so it does not take as long
- Imports: pandas
- Create a green rating for each restaurant based on whether it’s reviews contains “environmental” terms.
- Examples of environmental terms: compost, recycle, green, local, vegan, vegetarian
- If 1% or more of the total words in the reviews were environmental words, the restaurant got a score of 3, the rest got scores of 0, 1, or 2 but in our final dataset we only counted those with a score of 3 as “green”
- files required:
data/helper_files/environmentalTerms.txt,data/big_restaurants_and_reviews.csvordata/small_restaurants_and_reviews.csv - file generated:
data/big_term_based_green_rating_results.csvordata/small_term_based_green_rating_results.csv
- merge_all_ratings.py
- Can be run with --Small True to use the small dataset so it does not take as long
- Imports: pandas
- Creates the Final dataset which contains a row for each restaurant
- columns: name, review text, yelp stars, GRA rating, seafood watch rating, term based rating, overall green rating
- files required:
data/small_restaurants_and_reviews.csvordata/big_restaurants_and_reviews.csvdata/small_term_based_green_rating_results.csvordata/big_term_based_green_rating_results.csv - file generated:
data/small_restaurants_reviews_ratings.csvordata/big_restaurants_reviews_ratings.csv,
- In the jupyter notebook
notebooks/restaurants_reviews_ratings_analysis.ipynbI generate the dataset generated bypythonScripts/merge_all_ratings.py(notebook cells are copied from there) and do some basic data exploration and analysis. The visualization and graph above come from this notebook. There are no striking conclusions based on this analysis.
- Run better stemming and lemmatization algorithms on the reviews and determine topics for green restaurant reviews and non green restaurant reviews.
- Expand list of green restaurants by using more alternative data sources (such as blogs or web scraping)
- Use nyc open data in addition to yelp stars to measure if green restaurants are more successful