Keras implementation of YOLO v3

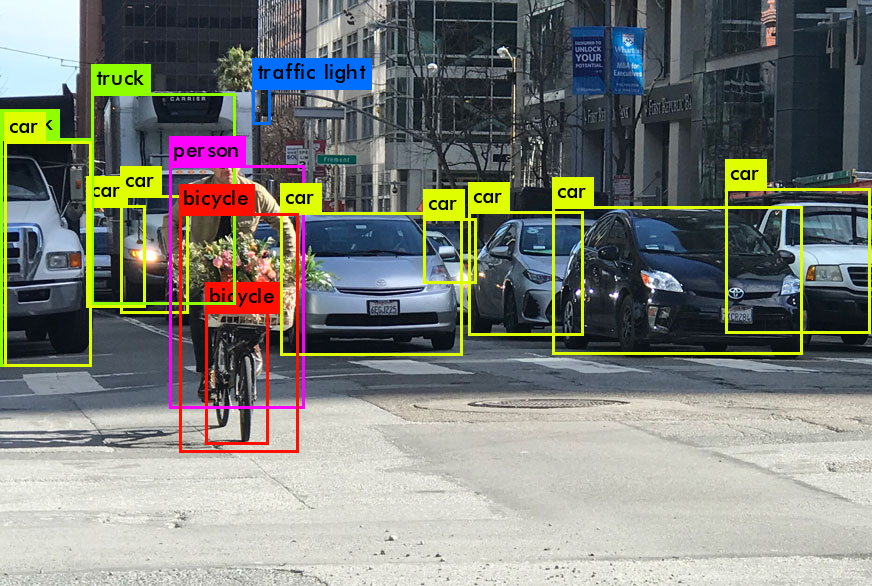
YOLO stands for you only look once and is an efficient algorithm for object detection.
Important papers on YOLO:
- Original - https://arxiv.org/abs/1506.02640
- 9000/v2 - https://arxiv.org/abs/1612.08242
- v3 - https://arxiv.org/abs/1804.02767
There are "tiny" versions of the architecture, often considered for embedded/constrained devices.
Website: https://pjreddie.com/darknet/yolo/ (provides information on a framework called Darknet)
This implementation of YOLOv3 (Tensorflow backend) was inspired by allanzelener/YAD2K.
Updates Provided in This Fork
- Option to bring custom data and labels
- Parameterization of scripts
- More detailed instructions and introductory material (above)
What You Do Here
Using this repo you will perform some or all of the following:
- Convert a Darknet model to a Keras model (and if custom setup, modify the config file with proper filter and class numbers)
- Perform inference on video or image as a test (quick-start)
- Label data with a bounding box definition tool
- Train a model on custom data using the converted custom Darknet model in Keras format (
.h5) - Perform inference on custom model
Quick Start (Inference Only)
pip install -r requirements.txt- Download YOLOv3 weights.
Download full-sized YOLOv3 here: https://pjreddie.com/media/files/yolov3.weights
Or, on linux: wget https://pjreddie.com/media/files/yolov3.weights
- If the tiny version of the weights are needed, download this file: https://pjreddie.com/media/files/yolov3-tiny.weights
- Convert the Darknet YOLOv3 model to a Keras model.
-
To convert the darknet format of weights to Keras format, make sure you have run the following using the proper config file
python convert.py -w experiment/yolov3.cfg yolov3.weights yolo_weights.h5
- Run YOLO detection with
yolo_video.py.
Run on video or image file:
usage: yolo_video.py [-h] [--model_path MODEL_PATH]
[--anchors_path ANCHORS_PATH]
[--classes_path CLASSES_PATH] [--gpu_num GPU_NUM]
[--image] [--input [INPUT]] [--output [OUTPUT]]
-h, --help show this help message and exit
--model_path MODEL_PATH
path to model weight file, default model_data/yolo.h5
--anchors_path ANCHORS_PATH
path to anchor definitions, default
model_data/yolo_anchors.txt
--classes_path CLASSES_PATH
path to class definitions, default
model_data/coco_classes.txt
--gpu_num GPU_NUM Number of GPU to use, default 1
--image Image detection mode, will ignore all positional
arguments
--input [INPUT] Video input path
--output [OUTPUT] [Optional] Video output path
For examples, see below in Use model.
Simple example for built-in webcam: python yolo_video.py --model_path yolo_weights.h5 --anchors model_data/yolo_anchors.txt --classes_path model_data/coco_classes.txt
For Tiny YOLOv3, just do in a similar way, except with tiny YOLOv3, converted weights.
- MultiGPU usage is an optional. Change the number of gpu and add gpu device id.
Data Prep
- Use the VoTT (link) labeling tool if using custom data and export to Tensorflow Pascal VOC.
You should get some name of a folder followed by _output. It will have three subfolders
/Annotations
/ImageSets
/JPEGImages
-
Rename the
xyz_outputfolder todata. -
Copy
datato the base of this repo.
Training
IMPORTANT NOTES:
- Make sure you have set up the config
.cfgfile correctly (filtersandclasses) - more information on how to do this here - Make sure you have converted the weights by running:
python convert.py yolov3-custom-for-project.cfg yolov3.weights model_data/yolo-custom-for-project.h5(i.e. for config update thefiltersin CNN layer above[yolo]s andclassesin[yolo]'s to class number)
-
Generate your own annotation file and class names file in the following format with
voc_annotation.pydescribed below.- It should generate one row for each image, e.g.:
image_file_path x_min,y_min,x_max,y_max,class_id.
- It should generate one row for each image, e.g.:
Generate this file with voc_annotation.py. This script takes all of the Annotations and ImageSets (classes with val and train) and converts them into one file. The final text file will then be used by the training script.
-
Modify the
setsandclassesappropriately withinvoc_annotation.py -
Run with
python voc_annotation.pyHere is an example of the output:
path/to/img1.jpg 50,100,150,200,0 30,50,200,120,3 path/to/img2.jpg 120,300,250,600,2 ...
-
To convert the darknet format of weights to Keras format, make sure you have run the following using the proper config file
python convert.py -w yolov3.cfg yolov3.weights yolo_weights.h5
- The file
yolo_weights.h5is, next in training, used to load pretrained weights.
-
Calculate the appropriate achor box sizes with
kmeans.pyusing the training annotation file output fromvoc_annotation.pyas the--annot_file.python kmeans.py --annot_file project/train.txt --out_file project/custom_anchors.txt --num_clusters 9- Note, for
--num_clusters, use 9 for full YOLOv3 and 6 for tiny YOLOv3.
- Note, for
-
Train with
train.pywith the following script arguments:
usage: train.py [-h] [--model MODEL] [--gpu_num GPU_NUM]
[--annot_path ANNOT_PATH] [--class_path CLASS_PATH]
[--anchors_path ANCHORS_PATH]
-h, --help show this help message and exit
--model MODEL path to model weight file, default model_data/yolo.h5
--gpu_num GPU_NUM Number of GPU to use, default 1
--annot_path ANNOT_PATH
Annotation file with image location and bboxes
--class_path CLASS_PATH
Text file with class names one per line
--anchors_path ANCHORS_PATH
Text file with anchor positions, comma separated, on
one line.
Note, if you want to use original pretrained weights for YOLOv3:
wget https://pjreddie.com/media/files/darknet53.conv.74- rename it as darknet53.weights
python convert.py -w darknet53.cfg darknet53.weights model_data/darknet53_weights.h5- use model_data/darknet53_weights.h5 in
train.py
Use Model
Inference on an image
In addition to other arguments, use --image
Example: python yolo_video.py --model_path trained_weights_final.h5 --anchors model_data/custom_anchors.txt --classes_path model_data/custom_classes.txt --image
Inference on video from a webcam
Note: on linux video0 is usually the built-in camera (if this exists) and a USB camera may be used so look for video1 etc. (if there is not camera, then video0 is usually USB cam). On MacOS, use for --input 0, for built-in, and 1 for USB. This should be the same on Windows.
In addition to other arguments, use --input <video device id>
Example: python yolo_video.py --model_path trained_weights_final.h5 --anchors model_data/custom_anchors.txt --classes_path model_data/custom_classes.txt --input 0
Inference on video file and output to a video file
In addition to other arguments, use --input <video file name> --output xyz.mov
Example: python yolo_video.py --model_path trained_weights_final.h5 --anchors model_data/custom_anchors.txt --classes_path model_data/custom_classes.txt --input <path to video>/some_street_traffic.mov --output some_street_traffic_with_bboxes.mov
Some issues to know
-
Default anchors can be used. If you use your own anchors, probably some changes are needed (using
model_data/yolo_tiny_anchors.txt). -
The inference result is not totally the same as Darknet but the difference is small.
-
The speed is slower than Darknet. Replacing PIL with opencv may help a little.
-
Always load pretrained weights and freeze layers in the first stage of training. Or try Darknet training. It's OK if there is a mismatch warning.
-
The training strategy is for reference only. Adjust it according to your dataset and your goal. And add further strategy if needed.
-
For speeding up the training process with frozen layers train_bottleneck.py can be used. It will compute the bottleneck features of the frozen model first and then only trains the last layers. This makes training on CPU possible in a reasonable time. See this for more information on bottleneck features.